2018년 12월 19일 고대하던 CKA 자격증을 취득하였습니다. 자랑겸, 정보 공유겸 취득 후기 포스트를 작성합니다.
저는 오늘 kubernetes에 대해 소개하고자 합니다. 사실 이미 인터넷상에는 kubernetes에 대해서 소개하는 글과 동영상들이 많이 있습니다. 또한 쿠버네티스를 이용하여 웹...
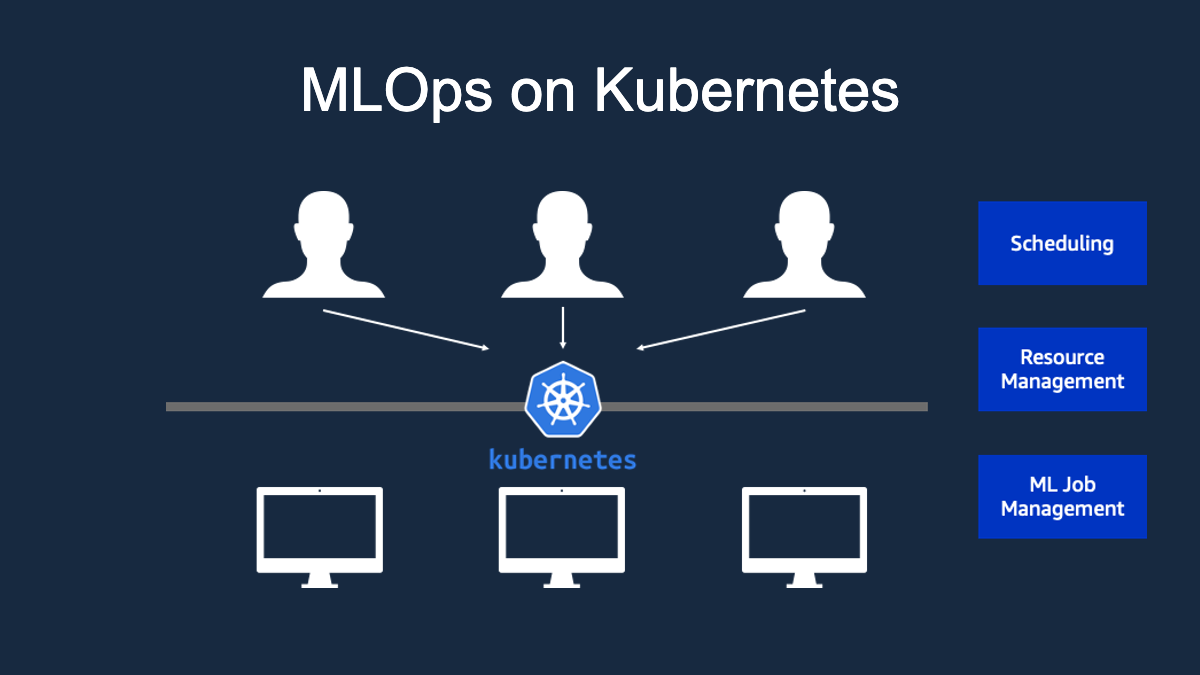
개별 host에서 학습한 모델 파일을 통합적으로 관리할 수 있는 방법에 대해 알아보겠습니다.
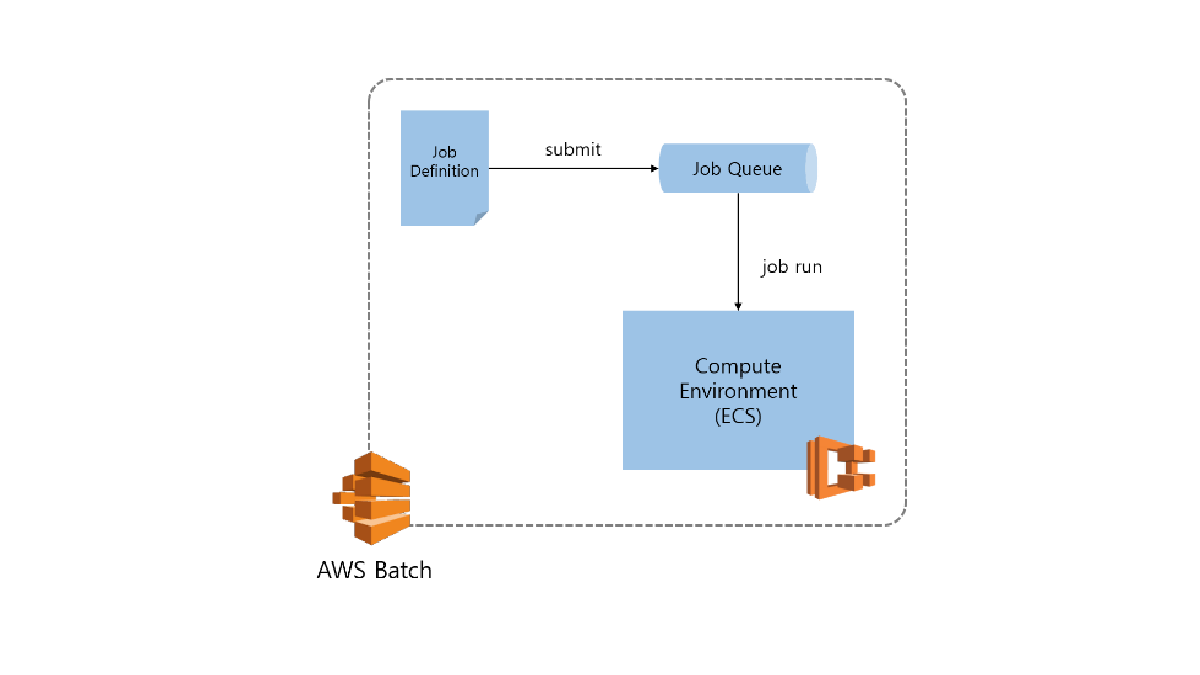
지난 포스트에서 AWS Batch가 어떤 서비스인지에 대해 알아봤습니다. 이번에는 실제 코드와 함께 어떻게 분산 병렬 학습을 할 수 있을지에 대해...
AWS Batch 서비스를 이용하여 쉽고 빠르게 분산 병렬 딥러닝 학습 환경을 구축해 봅시다.
AWS ECS용 GPU instance AMI를 만들어 AWS 컨테이너 서비스에서 (ECS, Batch) 딥러닝 학습을 해 봅시다.
작성날짜: 2017년 1월 기준 tensorflow 설치방법
slack을 이용하여 모델학습이 끝난 이후에 알람을 받도록 해봅시다.
저의 블로그의 독자라면 저의 믿음인, 더 많은 데이터가 보통 더 좋은 알고리즘을 이긴다는 사실에 대해서 잘 알고 계실 것입니다. 여기에...
제가 적은 블로그 포스트 ‘더 많은 데이터가 더 좋은 알고리즘을 이긴다’가 많은 사람들의 관심을 이끌었습니다. 많은 의견들을 개인적으로 다 대답하기...
이 글은 데이터 마이닝을 공부하던 중, The Mining of Massive Datasets의 저자인 Datawocky의 블로그 글(More data usually beats better algorithms)을...


![[기계학습] Slack을 이용한 Training 완료 알람 시계 만들기](/assets/images/slack_alarm.png)
![[번역] 더 많은 데이터가 더 좋은 알고리즘을 이긴다 #3](/assets/images/bigdata-landing.png)