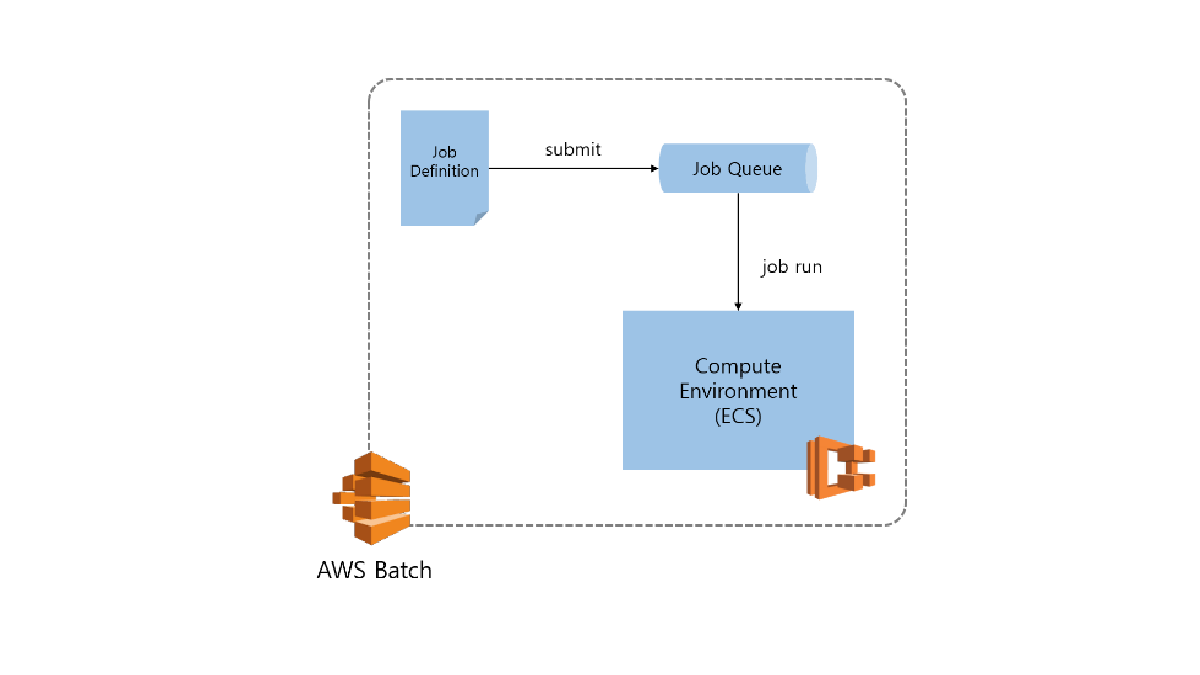
AWS Batch를 이용한 분산 병렬 딥러닝 학습 #2
11 min read
지난 포스트에서 AWS Batch가 어떤 서비스인지에 대해 알아봤습니다. 이번에는 실제 코드와 함께 어떻게 분산 병렬 학습을 할 수 있을지에 대해 알아봅시다.
Build model
먼저 hyper parameter를 이용하여 모델을 만드는 간단한 코드부터 시작하겠습니다.
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint
NUM_CLASSES = 10
def build_model(paramset):
# Hyper parameter setting
batch_size = paramset['batch_size']
epochs = paramset['epochs']
hidden_nodes = paramset['hidden_nodes']
dropout_rate = paramset['dropout_rate']
activate_fn = paramset['activate_fn']
optimizer = paramset['optimizer']
model_path = paramset['model_path']
# building model
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
for hidden_node in hidden_nodes:
model.add(Dropout(dropout_rate))
model.add(Dense(hidden_node, activation=activate_fn))
model.add(Dropout(0.2))
model.add(Dense(NUM_CLASSES, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model
paramset = {}
paramset['batch_size'] = 128
paramset['epochs'] = 20
paramset['hidden_nodes'] = [10, 20, 30]
paramset['dropout_rate'] = 0.5
paramset['activate_fn'] = 'relu'
paramset['optimizer'] = 'rmsprop'
model_path = 'model.h5'
model = build_model(paramset)
train(model, paramset, model_path)
보시다시피 paramset을 build_model 함수에 넘겨주면 해당 파라미터값들에 따라 모델이 만들어지게 하였습니다. 그럼 다음으로 S3에서 순서에 맞게 hyper parameter들을 가져올 수 있게 만들어 보겠습니다.
Fetch hyperparameter from S3
# 다음과 같은 YAML형식으로 S3에 hyperparam_list.yml라는 이름으로 저장되어 있다고 생각해봅시다.
- batch_size: 128
epochs: 20
hidden_nodes: [10, 20, 30]
dropout_rate: 0.2
activate_fn: relu
optimizer: rmsprop
- batch_size: 128
epochs: 20
hidden_nodes: [30, 50, 70]
dropout_rate: 0.7
activate_fn: tanh
optimizer: rmsprop
아래의 코드는 index값에 따라 hyper parameter 리스트 중 하나의 paramset을 가지고 와서 모델을 만들고 학습 시키는 코드입니다.
import boto3
import yaml
import os
BUCKET_NAME = 'my_bucket'
KEY = 'hyperparam_list.yml'
s3 = boto3.resource('s3')
s3.Bucket(BUCKET_NAME).download_file(KEY, 'hyperparam_list.yml')
index = 1 # hyperparam_list.yml의 첫번째 paramset
with open(KEY) as f:
hyperparam_list = yaml.load(f)
paramset = hyperparam_list[index]
print(paramset)
model = build_model(paramset)
model_path = 'model_%s.h5' % index
train(model, paramset, model_path)
그렇다면 hyperparameter list를 indexing하는 index 변수는 어디서 가지고 오면 될까요? 바로 지난번 포스트에서 설명한 AWS Batch 환경에서 제공해주는 AWS_BATCH_JOB_ARRAY_INDEX 환경 변수를 활용하면 모든 것이 완벽할 것 같습니다.
index = int(os.environ['AWS_BATCH_JOB_ARRAY_INDEX'])
그럼 이제 해당 코드를 docker image로 묶어 보도록 하겠습니다.
전체코드
아래 코드는 위 설명에 대한 전체 코드를 train_model.py로 저장한 것입니다.
# 전체 코드: train_model.py
from __future__ import print_function
import boto3
import yaml
import os
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint
NUM_CLASSES = 10
def build_model(paramset):
# Hyper parameter setting
batch_size = paramset['batch_size']
epochs = paramset['epochs']
hidden_nodes = paramset['hidden_nodes']
dropout_rate = paramset['dropout_rate']
activate_fn = paramset['activate_fn']
optimizer = paramset['optimizer']
model_path = paramset['model_path']
# building model
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
for hidden_node in hidden_nodes:
model.add(Dropout(dropout_rate))
model.add(Dense(hidden_node, activation=activate_fn))
model.add(Dropout(0.2))
model.add(Dense(NUM_CLASSES, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model
def train(model, paramset, model_path):
epochs = paramset['epochs']
batch_size = paramset['batch_size']
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_train = x_train[:10000]
y_train = y_train[:10000]
x_test = x_test[:10000]
y_test = y_test[:10000]
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, NUM_CLASSES)
y_test = keras.utils.to_categorical(y_test, NUM_CLASSES)
chkpt = ModelCheckpoint(model_path, monitor='val_acc', \
verbose=1, save_best_only=True, mode='max')
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
callbacks=[chkpt],
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print(score)
BUCKET_NAME = 'my_bucket'
KEY = 'hyperparam_list.yml'
s3 = boto3.resource('s3')
s3.Bucket(BUCKET_NAME).download_file(KEY, 'hyperparam_list.yml')
index = int(os.environ['AWS_BATCH_JOB_ARRAY_INDEX'])
with open(KEY) as f:
hyperparam_list = yaml.load(f)
paramset = hyperparam_list[index]
print(paramset)
model = build_model(paramset)
model_path = 'model_%s.h5' % index
train(model, paramset, model_path)
Docker file
# keras Dockerfile을 그대로 가져와서 조금 수정하였습니다.
ARG cuda_version=9.0
ARG cudnn_version=7
FROM nvidia/cuda:${cuda_version}-cudnn${cudnn_version}-devel
# Install system packages
RUN apt-get update && apt-get install -y --no-install-recommends \
bzip2 \
g++ \
git \
graphviz \
libgl1-mesa-glx \
libhdf5-dev \
openmpi-bin \
wget && \
rm -rf /var/lib/apt/lists/*
# Install conda
ENV CONDA_DIR /opt/conda
ENV PATH $CONDA_DIR/bin:$PATH
RUN wget --quiet --no-check-certificate https://repo.continuum.io/miniconda/Miniconda3-4.2.12-Linux-x86_64.sh && \
echo "c59b3dd3cad550ac7596e0d599b91e75d88826db132e4146030ef471bb434e9a *Miniconda3-4.2.12-Linux-x86_64.sh" | sha256sum -c - && \
/bin/bash /Miniconda3-4.2.12-Linux-x86_64.sh -f -b -p $CONDA_DIR && \
rm Miniconda3-4.2.12-Linux-x86_64.sh && \
echo export PATH=$CONDA_DIR/bin:'$PATH' > /etc/profile.d/conda.sh
ARG python_version=3.6
RUN conda install -y python=${python_version} && \
pip install --upgrade pip && \
pip install \
sklearn_pandas \
tensorflow-gpu && \
pip install https://cntk.ai/PythonWheel/GPU/cntk-2.1-cp36-cp36m-linux_x86_64.whl && \
conda install \
bcolz \
h5py \
matplotlib \
mkl \
nose \
notebook \
Pillow \
pandas \
pygpu \
pyyaml \
scikit-learn \
six \
boto3 \
theano && \
git clone git://github.com/keras-team/keras.git /src && pip install -e /src[tests] && \
pip install git+git://github.com/keras-team/keras.git && \
conda clean -yt
ENV PYTHONPATH='/src/:$PYTHONPATH'
ADD train_model.py .
CMD python train_model.py
docker build . -t {account-id}.dkr.ecr.{region}.amazonaws.com/{name}:{tag}
docker push {account-id}.dkr.ecr.{region}.amazonaws.com/{name}:{tag}
해당 이미지를 ECR에 upload까지 하면 모든 준비가 완료되었습니다. 이제 AWS Batch 서비스를 이용하여 분산 병렬 학습을 해봅시다.
Using aws cli
aws batch register-job-definition --job-definition-name train_model_def --type=container --container-properties '{ "image": "{account-id}.dkr.ecr.{region}.amazonaws.com/{name}:{tag}", "vcpus": 4, "memory": 20000}'
먼저 Job definition을 등록하겠습니다. 이름은 train_model_def이라고 정하겠습니다. 여기서 중요한 점은 vcpus값을 학습 시키려는 EC2 instance의 vcpu 개수와 동일하게 설정하여 주시기 바랍니다. (저는 p2.xlarge type을 사용하여 vcpu 4를 입력하였습니다.) 그 이유는 현재 AWS Batch에는 명시적으로 GPU자원을 요청하는 기능이 없습니다. CPU와 Memory 자원만 명시적으로 요청하는 기능이 있습니다. 그렇기 때문에 한 host당 하나의 training 작업이 돌아가길 원하신다면 CPU 요청값을 이용하여 해결해야 합니다. 그렇지 않는다면 잘못하다가 두개의 job이 동시에 동일한 host에서 돌다가 GPU 자원이 모자라게 되어 프로그램이 죽을 수 있습니다.
aws batch submit-job --job-name train_model --job-queue {job_queue_name} --job-definition train_model_def --array-properties '{"size": 2}'
이제 만든 Job definition을 실제로 돌려보도록 하겠습니다. 작업을 실행 시키기 위해서 다음과 같은 변수들에 값을 채워야 합니다.
- job-name: job definition과 별도로 job의 이름을 지정해야 합니다. 저는 train_model이라 하겠습니다
- job-queue: compute environment와 연결된 job queue 이름을 넣습니다.
- job-definition: 실행하려는 작업 정의 이름을 넣습니다.
train_model_def를 입력합니다. - array-properties: 몇개의 job을 돌릴지, job간의 dependency등을 정합니다. 저희는 테스트로 2개의 hyper parameter set을 만들었기 때문에 size를 2라고 적겠습니다. 결국 해당 property를 이용하여 한개의 image를 가지고 분산 병렬 처리를 할 수 있게 만들어 줍니다.
job submit을 할 때에도, CPU, memory 자원 요청을 할 수 있습니다. 저희는 Job definition을 등록할 때 이미 설정을 하여 생략합니다. 학습한 모델 파일을 (checkpoint file, h5 등) 직접 눈으로 보고 싶으시다면 작업 실행시 volume을 마운트 시키고 직접 host에 들어가서 해당 위치에서 확인하시기 바랍니다. volume 마운트 생략시 도커 컨테이너 내부에 만들어지게 됩니다. 이번 포스트에서는 volume 마운트를 생략하겠습니다.
지금까지 살펴본 과정을 정리하자면 다음과 같습니다.
- AWS Batch에서 필요한 환경을 만들었습니다. (Job Queue, Compute environment, 지난 포스트)
- S3에서 hyper parameter list를 다운 받아 하나의 paramset을 이용하여 모델을 구축하고 학습하는 코드를 만들었습니다.
- 해당 코드를 도커 이미지로 만들어 저장하였습니다.
- AWS Batch에서 해당 이미지로 작업 정의를 만들어 등록하였습니다.
- 작업을 실행할 때, 몇개의 작업을 병렬로 실행할 것인가, 컨테이너 property들을 설정할 수 있습니다.
이렇게 환경을 세팅하고 나면 대규모 모델 학습하는 일은 무척 편리해 집니다. 비즈니스의 중요도에 따라 빠르게 많은 모델을 학습 시켜야 한다면 더 많은 instance들을 compute environment에 붙이면 되고, 가격적인 면으로는 spot instance를 통해 최소의 비용으로 최대의 효율을 뽑을 수 있습니다.
그럼 다음 포스트에서 각 host에서 학습한 모델 결과 파일 (checkpoint file, h5 등)을 어떻게 효율적으로 한곳에서 관리할 수 있을지에 대해서 알아보도록 하겠습니다.