AWS Batch를 이용한 분산 병렬 딥러닝 학습 #3
3 min read
개별 host에서 학습한 모델 파일을 통합적으로 관리할 수 있는 방법에 대해 알아보겠습니다.
현재 문제점
현재 각 서버에서 병렬로 학습을 실행 시키기 때문에 학습된 모델들이 각각의 서버에 생성됩니다. 그렇기 때문에 학습된 모델들을 이용하기 위해서는 개별 서버에 접속하여 모델 학습 결과들을 확인하거나 직접 한 곳으로 옮겨줘야합니다. host 서버가 적을 때는 조금만 수고하면 그리 어렵지 않게 각 서버들을 순회하며 결과 파일을 한 곳으로 옮길 수 있습니다. 혹은 ssh remote command를 사용하거나 ansible과 같은 툴을 이용하면 조금 더 편리하게 학습 결과를 한 곳으로 옮길 수 있습니다. 하지만 매번 학습 결과에 대해서 추가적인 작업을 할 필요 없이 자동적으로 한 곳으로 모이게는 할 수 없을까요?
제안
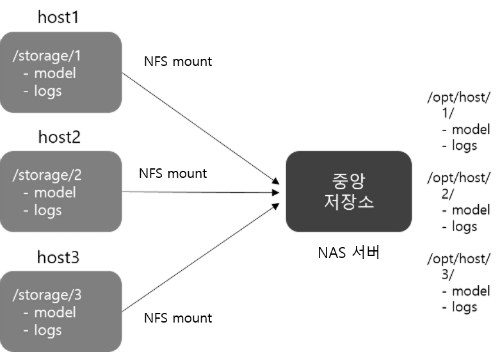
애초부터 원격 저장소를 학습 서버에 직접 마운트 시켜서 학습 결과가 생성되는 즉시 중앙 저장소로 모이게하는 건 어떨까요? 바로 NAS서버를 이용하여 각 서버에 Network File System으로 마운트하는 방법이 되겠습니다. 이를 통해 학습 서버에서는 기존과 마찬가지로 마치 로컬 디렉토리에 파일을 저장하는 것처럼 보이나 실제로는 원격 저장소로 모델 파일들일 모이게 됩니다. 방법도 그리 어렵지 않습니다.
How to?
원격 저장소로 AWS에서 제공하는 NAS 서비스인 EFS를 사용하도록 하겠습니다. AWS에서 이미 EFS를 ECS의 스토리지로 활용할 수 있게 가이드를 제공하고 있습니다. 해당 문서를 참고하셔도 좋습니다. Amazon ECS에 Amazon EFS 파일 시스템 사용
AWS EFS 서비스 생성
가장 먼저 EFS 서비스를 생성해야 합니다. AWS > Storage > EFS 서비스에 들어가셔서
- Create file system 버튼을 클릭합니다.
- 속할 VPC와 subnet을 선택합니다. (특별히 세팅을 안하면 default VPC 선택), Next 클릭
- Performance mode
- General purpose: 기본 성능 모드, latency가 중요한 경우
- Max I/O: 많은 머신이 동신에 접속해야 할 경우, latency가 약간 높다고 함. - Throughput mode
- Bursting: 기본 throughput 모드
- Provisioned: provisioned 모드, EFS 같은 경우 저장된 용량에 따라 throughput이 결정되는데 작은 용량의 파일이 여러개 있을 경우, 느려지는 현상이 있는데 이럴 경우 throughput을 provision 시켜 처리량을 일정 수준 유지 시켜줄 수 있습니다.
performance에 관한 더 자세한 사항은 AWS 공식 문서를 참고.
학습 서버에 EFS 연결
이제 만들어진 NAS 서버를 학습 서버에 mount 시켜 보겠습니다.
- 학습 서버에 ssh 접속을 합니다.
- EFS를 mount 시킬 디렉토리를 /efs 라는 이름으로 만듭니다.
sudo mkdir /efs - NFS client 소프트웨어를 설치합니다.
- CentOS / Amazon Linux:
sudo yum install -y nfs-utils(참고: ECS 전용 instance는 Amazon Linux를 base로 합니다) - Ubuntu:
sudo apt-get install -y nfs-common
- CentOS / Amazon Linux:
- /efs에 EFS를 마운트 시킵니다.
아래의 명령어에서
${REPLACE_HERE}부분을 EFS 서비스의 DNS name으로 바꿔서 실행하시기 바랍니다.
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 ${REPLACE_HERE}:/ /efs
- 각 서버를 순회하면서 EFS를 mount해주면 학습 서버 세팅 완료!
- 이제 지난 포스트 에서 만든 학습 스크립트 (
train_model.py) 의 코드 중 모델을 저장하는 부분을 수정해 봅시다.s3 = boto3.resource('s3') s3.Bucket(BUCKET_NAME).download_file(KEY, 'hyperparam_list.yml') index = int(os.environ['AWS_BATCH_JOB_ARRAY_INDEX']) with open(KEY) as f: hyperparam_list = yaml.load(f) paramset = hyperparam_list[index] print(paramset) model = build_model(paramset) model_path = '/storage/%s/model/' % index # 기존, 'model_%s.h5' % index os.makedirs(model_path, exist_ok=True) # 새롭게 추가 model_path = os.path.join(model_path, 'model.h5') - (optional) 새로운 instance를 생성할 때마다 EFS를 mount할 필요 없이 AMI로 만들어서 관리하면 편리합니다.
AWS Batch 서비스를 이용하여 Job을 완료한 이후에 EFS storage에 원하는 결과물이 생성 되었는지 확인해 봅니다.
ls -al /storage/*
이제 한 곳에서 기계학습 결과물을 관리할 수 있게 되었습니다. 생성된 모델 파일을 예측 때 사용하는 방법도 어디서든 동일하게 로컬 파일 시스템을 접근 하듯이 모델에 접근할 수 있습니다.
지금까지 3개의 포스트를 활용하여 AWS Batch를 이용하여 분산 병렬 학습하는 방법에 대해서 작성하였습니다. 앞으로는 서버를 어떻게 사용해야하는지에 대한 세부적인 사항을 고민하지 말고 핵심 모델링에 좀 더 집중하여 원하는 모델을 더 빠르고 효율적으로 얻으시길 바랍니다.