AWS Batch를 이용한 분산 병렬 딥러닝 학습 #1
4 min read
AWS Batch 서비스를 이용하여 쉽고 빠르게 분산 병렬 딥러닝 학습 환경을 구축해 봅시다.
제가 대학원을 다닐 당시에는 RNN에 attention mechanism을 적용한 벤지오 교수님의 모델이 인기가 있었고 저도 attention을 이용하여 text classification 모델을 공부하였습니다. 연구실에는 GPU 서버, 일반 서버 다 합쳐서 약 7대 정도의 서버가 있었고 눈치껏 사용하지 않는 서버를 사용하였습니다. 그때도 여러 서버에서 조금 더 쉽게 딥러닝 학습 분산하여 빠른 시간내에 결과를 얻을 수 없을까 고민하였었고 제 나름대로 간단한 솔루션을 만들어 사용하였습니다.
- miniconda: requirements.txt 파일을 만들어서 각 서버의 user path에 각자 필요한 패키지들을 설치하였습니다.
- git & github: 딥러닝 모델 소스코드와 hyper parameter list를 만들어 github에 private repository에 push합니다.
- ansible: ansible을 이용하여 각각 지정된 host로 명령어를 날렸습니다. git pull & run python 등
- slack API: 각 서버에서 학습이 끝나면 학습 평가 결과와 함께 어느 서버의 어떤 모델이 끝이 났는가 알려줍니다. 그러면 실제 해당 서버로 들어가서 자세한 log 기록들을 살펴보며 개선점을 찾아나갔습니다.
그 당시의 방법도 그리 나쁘지는 않았습니다. 사용하는 서버가 10대 이하였기 때문에 ssh 설정만 미리 편하게 해놓으면 간단한 명령어는 물론 직접 접속하여 확인하는 것이 그리 어려운 일은 아니였습니다.
ssh host1 'cat $HOME/logs/2015-01-12-03.log' # 로그 기록 확인
ssh host1 # 직접 접속하여 확인
하지만 서버가 10대 이상을 넘어가게 된다면 얘기가 달라지기 시작합니다. 새로운 패키지를 하나 설치하려고 하더라도 굉장한 시간과 막노동이 필요로하게 됩니다. 그렇다면 어떻게 하면 좋을까요? 저는 AWS Batch 서비스를 이용한 방법을 소개하려고 합니다. 제가 대학원 시절에 이런 것들을 알았었더라면 (혹은 서비스가 나왔었더라면) 조금 더 편하게, 빠르게 결과를 낼 수 있었을텐데, 아쉽습니다. (사실 설령, 서비스가 이미 나왔었고 방법을 알고 있었다 하더라도 가격 때문에 쉽게 사용하진 못했을 것 같기도 합니다ㅋㅋ)
그럼 먼저 AWS Batch가 어떤 서비스인지에 대해서 알아보겠습니다.
What is AWS Batch?

AWS 공식 홈페이지에 가보면 ‘개발자, 과학자 및 엔지니어가 AWS에서 수많은 배치 컴퓨팅 작업을 효율적으로 실행할 수 있다’고 나와있습니다. 배치 컴퓨팅 작업은 비단 AWS만의 특별한 개념이 아닙니다. 우리가 흔히 배치 작업이라고 한다면, 미리 정의된 작업 을 어떤 컴퓨팅 환경 위에서 원하는 순서와 수량을 스케줄링 할 수 있으며 그 작업이 성공적으로 완료하였는지 현황 확인 하는 것을 말합니다.
AWS Batch에서도 각각 동일한 개념을 사용합니다.
- Job Definition: 작업을 어떻게 실행할지 미리 정의를 합니다.
- Job: 미리 정의한 작업이 실제로 어떻게 동작할지를 정하고 (scheduling) 작업 결과를 보여줍니다. (monitoring)
- Job Queue: 실행할 작업을 잡 큐에 적재합니다. 각 Queue는 Compute Environment와 연결되어 있습니다.
- Compute Environment: 실제 작업이 이루어지는 환경입니다. (내부적으로 ECS를 사용합니다.)
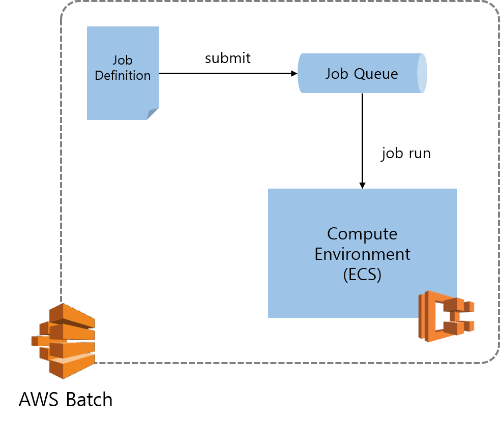
먼저 Job Definition부터 보겠습니다.
Job Definition
AWS Batch 위에서 어떤 작업을 실행할지 정의하는 곳입니다. 많은 파라미터들이 있지만 몇가지 중요하게 생각하는 부분에 대해서 얘기하겠습니다. 더 자세한 내용은 Job Definition 도큐먼트를 참고 바랍니다.
- Job definition name: 작업 정의 이름을 넣습니다. 저는
train이라고 적겠습니다. - Container image: 모델 학습을 하는 도커 이미지를 넣습니다.
- vCPUs: 해당 작업을 실행하기 위해 어느 정도의 CPU가 필요한지 명시적으로 적습니다. 여기서 중요한 것은 한 서버당 한개의 training만을 돌리고 싶으시면 해당 서버의 CPU만큼 적으시면 됩니다.(e.g. p2.xlarge 타입 경우 vCPU 4) 아직까지 GPU 자원을 명시적으로 요구하는 파라미터는 없는 것 같습니다.
- Environment variables: container에 정보를 넘길 때 사용합니다. AWS Batch에서는 한개의 Job definition을 이용하여 여러개의 job을 병렬로 실행할 수 있는데 이때
AWS_BATCH_JOB_ARRAY_INDEXenv variable을 이용하여 해당 작업이 몇번째 Job으로 실행되고 있는지 알 수 있습니다. 이 변수를 이용하면 hyper parameter 리스트를 S3와 같은 원격 스토리지에 저장해 놓고 각각의 Job에서 index 순에 맞게 모델 파라미터들을 들고와서 병렬로 학습을 수행할 수 있게 됩니다. Array Job 참고 - Volumes & Mount points: 학습한 모델 파일 (checkpoint, h5 등)을 Host에서 접근할 수 있게 volume을 만듭니다. 이때 각각의 host에서 volume을 mount시키는 것이 아니라
ssh volume을 이용하여 원격 저장소에 바로 저장하려고 합니다. 참고 docker ssh volume
Compute Environment
그 다음으로 작업이 실행될 환경을 생성해 봅시다. AWS Batch의 compute environment는 내부적으로 ECS를 사용합니다. 그래서 compute environment를 하나 생성하면 ECS cluster가 자동적으로 생성됩니다. 도커 컨테이너에서 컴퓨터의 GPU 자원을 이용하려면 몇가지 수정이 필요합니다. 매번 instance를 만들어서 수정할 필요 없이 custom AMI를 생성하여 사용하시면 편리합니다. 저의 예전 포스트를 참고하여 custom AMI를 생성하시기 바랍니다.
- Compute environment type:
Managed - Compute environment name: 컴퓨트 환경의 이름을 적습니다. 저는
deeplearning_cluster라고 적겠습니다. - Allowed instance types: 돈이 많이 없으므로
p2.xlarge를 선택하겠습니다. - Minimum vCPUs: 실행하지 않을 때에는 instance를 전부 내리기 위해
0을 넣겠습니다. 자주 사용한다면 어느정도 유지하는게 나을 것 같습니다. - Maximum vCPUs: 최대 5대가 넘지 않게
20(4 vCPU X 5 instance)이라고 설정하겠습니다. - Enable user-specified Ami ID:
checked - AMI ID: 도커 컨테이너에서 Host의 GPU를 사용할 수 있게 수정한 AMI ID 입력
Job Queue
Job Queue는 Job Definition과 Compute Environment를 연결해 주는 통로라고 생각하시면 됩니다. 작업을 하나 정의하고 그것을 어떠한 컴퓨트 환경에서 실행 시키고 싶을 때, 해당하는 Job Queue의 대기열에 집어 넣으시면 됩니다. 일반적으로도 배치 작업을 병렬로 돌리고 싶을 때, 여러개의 worker를 생성하여 하나의 queue를 바라보게 하고 실행 시키고 싶은 작업을 대기열에 넣으면 놀고 있는 worker 중에 하나가 작업을 처리하는 것과 동일하다고 보시면 됩니다. 한가지 특정이 있다면 AWS Batch Job Queue에는 priority 설정을 할 수 있어서 여러 Job queue에 연결된 컴퓨트 환경 중에 해당 Job queue에 연결된 작업을 먼저 컴퓨터 환경에서 처리할 수 있도록 해줍니다.
Job
마지막으로 Job에 대해서 설명 드리자면, Job은 Job Definition의 instantiate된 객체라고 생각하시면 편합니다. Job Definition을 실제로 실행할 때, 몇개의 Job을 어느 정도의 cpu와 memory를 사용하여 어떤 Job Queue에 넣을 지를 결정하여 생성된 객체입니다. 또한 Job은 현재 실행되고 있는 작업의 상태를 보여줍니다. (running, failed, succeeded 등) job id를 이용하여 running하고 있는 작업을 취소할 수도 있습니다.
지금까지 AWS Batch 서비스에 대해서 알아봤습니다. 이제 어떻게 AWS Batch 서비스를 이용하여 효율적으로 분산 병렬 처리할 수 있을지 코드와 함께 살펴 보겠습니다.