
딥러닝 학습을 위한 AWS ECS용 GPU AMI 만들기
4 min read
AWS ECS용 GPU instance AMI를 만들어 AWS 컨테이너 서비스에서 (ECS, Batch) 딥러닝 학습을 해 봅시다.
예전의 포스트에서는 tensorflow를 host에 직접 설치하는 방법에 대해서 알아 봤습니다. 이번 포스트에서는 docker container에서 GPU 자원에 접근할 수 있도록 설정하여 도커 안에서 딥러닝 학습을 할 수 있도록 서버를 세팅하고 AWS ECS 및 Batch에서 사용할 수 있도록 사용할 수 있도록 AMI를 구성해 보겠습니다.
도커를 사용하는 이유가 뭔가요?
제가 처음 도커를 접했을 때 처음 든 생각은, “좋은 것 같긴 한데 나랑은 별 상관이 없을 것 같다” 였습니다. AWS cloud instance이든 local machine이든 NVIDIA 드라이버를 설치하고 그 위에 cuda를 설치하고 그 위에 딥러닝을 위한 적절한 라이브러리를 설치하면 (tensorflow-gpu, keras) 그리 어렵지 않게 딥러닝 환경을 구성할 수 있었고, AWS instance를 사용할 때는 딥러닝용 AMI가 존재하기 때문에 해당 AMI를 선택해서 instance를 생성하면 (거의) 바로 학습을 시작할 수 있었습니다. (GPU instance의 가격이 비싸서 많이 사용하지는 못했지만..) 그렇다고 도커를 이용한다고 더 빠르게 학습을 시키거나 더 많이 시킬 수 있는게 아니였습니다.
그렇다면 도커를 이용하면 어떤 점이 좋을까요? 제가 생각했을 때는 “대규모 분산 학습을 쉽게 할 수 있어서”가 될 것 같습니다. 도커 이미지 하나만 만들어 놓으면 도커 엔진만 설치가 되어 있으면 어느 서버이든지 쉽게 학습을 돌릴 수 있기 때문입니다. 그렇게 되면 hyper-parameter 리스트를 만들어 놓고 여러 서버에서 병렬로 학습을 시킨 다음, 최적의 해를 찾을 수도 있고 여러 모델을들 동일한 데이터셋을 가지고 분산 병렬 학습을 시킬 수도 있게 됩니다.
도커 이미지만 있으면 되지 않나요?
(이론상) 맞습니다. 도커 이미지만 있으면 도커 엔진이 있는 곳 어디라면 바로 실행할 수 있습니다. 하지만 도커가 GPU 자원을 이용하려면 얘기가 조금 달라집니다. 도커에서 직접 host 머신의 GPU 자원을 이용하기 위해서는 host 머신에 nvidia-docker라는 것을 설치해줘야 하며, ECS cluster의 instance로 활용하려면 ecs-init을 따로 설치해 줘야 합니다. 이러한 이유로 Deep learning 학습을 위한 AMI를 따로 만들어 보려고 합니다.
설치 방법
기본적으로 AWS Document에서 설명하는 방법을 많이 참고하여 설치를 진행할 예정입니다. 하지만 해당 도큐먼트의 가이드대로 한다면 컨테이너를 시작할 때마다 명시적으로 nvidia 디렉토리를 마운트 시켜줘야 합니다.
docker run --privileged -v /var/lib/nvidia-docker/volumes/nvidia_driver/latest:/usr/local/nvidia nvidia/cuda:9.0-cudnn7-devel nvidia-smi
우리는 그럴 필요 없이 도커에서 default로 nvidia 드라이버를 사용할 수 있게 조금 수정하도록 하겠습니다.
# 매번 마운트를 하지 않아도 되어서 편하겠죠?
docker run nvidia/cuda:9.0-cudnn7-devel nvidia-smi
가장 먼저 AWS에서 제공하는 Deep learning용 AMI를 생성합니다.
Deep Learning AMI CUDA 9 Amazon Linux Version 기본적으로 NVIDIA driver, CUDA 9가 설치되어 있어 편하게 사용할 수 있습니다.
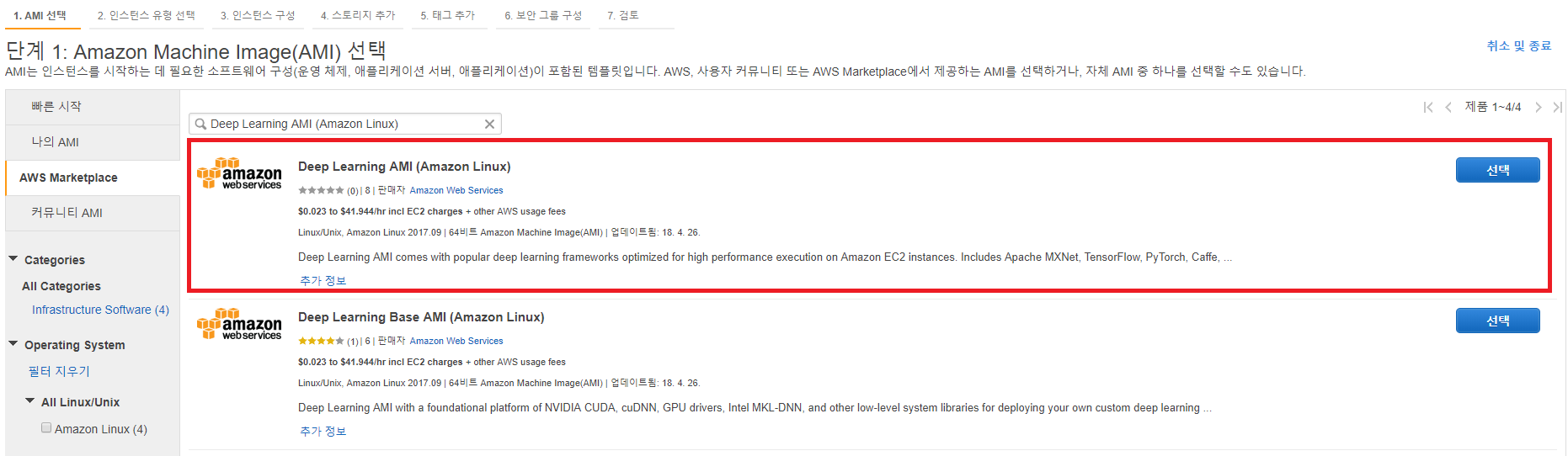
AMI를 생성할 때, 도커 컨테이너에서 GPU 연결이 잘되는 것만 확인하면 되기 때문에 Instance type은 가장 값싼 p2.xlarge로 선택하겠습니다. port는 22번만 열려 있으면 됩니다.
만약, scratch부터 시작하고 싶으시면 저의 예전의 포스트를 참고하시기 바랍니다. (좀 오래 전 포스트라 지금과는 많이 다를 수 있습니다.) instance 생성이 완료 되었으면 해당 ssh로 접속하여 이제 필요한 패키지들을 설치해 보겠습니다.
ecs-init 설치
sudo yum install -y ecs-init
>> Complete!
sudo service docker start
>> Starting docker... [OK]
sudo docker version
>> # 버전이 출력이 된다면 정상적으로 설치되었습니다.
# docker를 sudo 권한 없이 실행할 수 있게 docker group에 자신의 계정을 등록합니다.
# login을 새롭게 해야 적용이 됩니다.
sudo gpasswd -a $USER docker
nvidia-docker2 설치
nvidia에서 제공하는 NVIDIA Container Runtime for Docker를 설치합니다. 도커에서 nvidia driver를 접근할 수 있게합니다.
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
>> nvidia-smi 결과가 잘 출력된다면 설치를 성공하였습니다.
혹시 에러 메시지가 출력된다면 /usr/bin/nvidia-container-runtime 위치에 디렉토리가 정상적으로 생성되었는지 확인해보시기 바랍니다.
해당 디렉토리가 없다면 nvidia runtime 모듈이 제대로 설치되지 않았을 가능성이 높습니다.
저는 ecs-init을 설치할 당시, nvidia-docker와의 version 문제로 명시적으로 1.14.4-1 버전을 설치하였습니다. (sudo yum install ecs-init-1.14.4-1.amzn1) ecs-init에서 사용하는 docker 버젼과 nvidia-docker에서 요구하는 docker 버젼을 동일하게 맞춰서 설치하시면 됩니다.
yum search --showduplicates ecs-inityum search --showduplicates nvidia-docker2
default로 nvidia runtime 사용하기
--runtime=nvidia 옵션을 명시적으로 입력하지 않아도 되게 nvidia를 디폴트 runtime으로 수정합니다.
sudo vi /etc/docker/daemon.json
{
"default-runtime": "nvidia", # 새롭게 추가
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
:wq # 저장 후, 나가기
# 재시작 한번 해주세요
sudo service docker restart
이제 runtime 옵션을 빼고 다시 nvidia-smi 명령어를 실행해 봅시다.
docker run --rm nvidia/cuda nvidia-smi
이상없이 잘 출력된다면 AMI 만들기 준비는 거의 끝났습니다.
마지막으로 ECS container instance로 사용할 수 있게 필요 없는 것들을 전부 지워 줍니다.
# AMI를 생성하기 위해 돌고 있는 container를 모두 삭제합니다.
sudo docker rm $(sudo docker ps -aq)
# Image들 또한 삭제합니다.
sudo docker rmi $(sudo docker images -q)
# ECS container agent를 멈춥니다.
sudo stop ecs
# 마지막으로 persistent data checkpoint 파일을 삭제합니다.
sudo rm -rf /var/lib/ecs/data/ecs_agent_data.json
이제 끝났습니다! 해당 instance에 대해서 스냅샵을 만드시면 Docker에서 GPU 자원을 접근할 수 있게 세팅한 ECS instance AMI를 얻을 수 있습니다!
다음 포스트에서는 해당 AMI를 이용하여 AWS Batch에서 어떻게 분산 병렬 모델 학습을 쉽게 할 수 있을지 알아보도록 하겠습니다. 크게 세가지로 나눠 보자면 첫번째, AWS Batch가 어떤 서비스인지 개념적으로 살펴 보겠습니다. 두번째, 어떻게 하면 AWS Batch를 이용하여 쉽게 분산 병렬 처리를 할 수 있는지 간단한 코드와 함께 확인해 보겠습니다. 마지막으로, 각 서버에서 생기는 학습된 모델 weight들을 (tensorflow checkpoint, keras h5 file 등) 어떻게 통합적으로 관리할 수 있을지 알아보겠습니다.