![[번역] 쿠버네티스 네트워킹 이해하기#3: Ingress](/assets/images/k8s_network/landing03.png)
[번역] 쿠버네티스 네트워킹 이해하기#3: Ingress
12 min read
쿠버네티스 네트워킹 시리즈의 첫번째 포스트에서는 한 Pod가 다른 노드에 위치하는 다른 Pod들과 어떻게 서로 통신하는지 설명하였습니다. 두번째 포스트에서는 서비스 네트워크가 어떻게 포드들의 부하를 분산 시키는지 설명하였고 이를 통해 클러스터 내의 클라이언트가 안정적으로 각 포드들과 통신할 수 있었는 것을 확인할 수 있었습니다. 마지막 세번째 포스트에서는 앞서 설명 드린 네트워킹 개념들을 가지고 어떻게기술을 이용하여 클러스터 외부에서 각 Pod들로 트래픽을 전달하는지 알아보도록 하겠습니다.
쿠버네티스 네트워킹 이해하기 시리즈
- #1 Pods 네트워크
- #2 Service 네트워크
- #3 Ingress 네트워크
3가지 네트워크 모두 서로 연관되어 있기 때문에 이번 포스트를 이해하기 위해서는 앞서 설명드린 네트워크 개념들을 미리 숙지하셔야지만 제대로 이해할 수 있을 것입니다.
먼저 이번 오스틴에서 열린 kubecon 2017에서 막 돌아오면서 앞서 말씀 드린 것처럼 쿠버네티스는 정말 빠르게 성장하는 플랫폼인 것을 다시금 깨닫게 되는 시간이 되었습니다. 많은 아키텍처들은 조립 가능하며 (plugable) 이것은 네트워크 또한 마찬가지입니다. 제가 여기서 설명드린 것은 GKE의 기본 구현체입니다. 아직 Amazon의 Elastic Kubernetes Service (EKS)를 보진 못했지만 아마도 쿠버네티스 기본 구현체와 비슷할 것으로 생각됩니다. 여러 변형된 네트워킹 구현체가 있다하더라도 쿠버네티스 네트워킹을 구현할때 표준이 정의되어 있기 때문에 여기에 나와있는 내용들이 쿠버네티스 네트워킹을 이해할때 기본이 될 것입니다. 또한 이러한 컨셉을들 잘 알게 된다면 unified service meshes과 같은 다른 대안들을 생각할때도 도움이 될 것입니다. 자 이제 Ingress에 대해 얘기해 봅시다.

라우팅은 로드 밸런싱이 아니다.
마지막 포스트에서 우리는 Deployment를 이용하여 몇가지 Pod들을 만들었고 그것들에 “Cluster IP” 이름의 서비스 IP를 부여하였습니다. 그리고 각 포드들은 이 서비스 IP를 이용하여 request를 요청하였습니다. 이 예제를 이번 포스트에서도 지속적으로 사용하도록 하겠습니다. 먼저 ClusterIP 10.3.241.152는 Pod 네트워크나 node 네트워크와는 다르게 또 다른 네트워크라는 것을 기억하시기 바랍니다. 저는 이 네트워크 공간을 service 네트워크라고 얘기하겠습니다. 사실 이것은 네트워크라고 불리기에는 조금 무리가 있습니다. 왜냐하면 이 네트워크는 실제 어느 네트워크 device에 연결된 것이 아니라 네트워크 전체가 routing rule에 의해서 구성되어 있기 때문입니다. 예시에서, 우린 이것이 쿠버네티스 컴포넌트 중 하나인 kube-proxy가 리눅스 커널 모듈인 netfilter를 이용하여 ClusterIP로 보내어지는 패킷을 낚아채어 healthy Pod로 패킷을 보내는 것을 확인할 수 있었습니다.
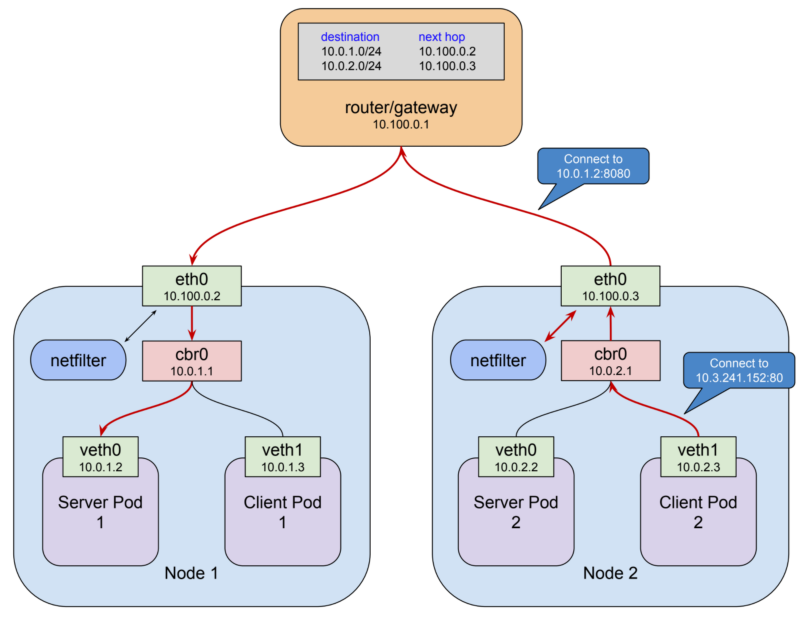
지금까지 저희는 네트워크를 설명할 때 “연결”(connections) 혹은 “요청”(requests)이나 더 모호하게 “traffic”이라는 단어를 사용하였습니다.. 쿠버네티스 ingress가 어떻게 동작하는 알기 위해서는 조금 더 자세히 알아볼 필요가 있습니다. 연결과 요청은 OSI layer 4 (tcp)나 layer 7 (http, rpc, etc)에서 동작합니다. Netfilter 라우팅 규칙은 IP packet 레벨인 layer 3에서 동작합니다. netfilter를 포함한 모든 라우터는 라우팅 결정을 IP packet 기준으로 합니다. 일반적으로 어디서부터 왔고 어디로 가야하는지 말이죠. 이것을 layer 3의 용어를 사용해서 설명 드리자면 10.3.241.152:80 서비스로 향하는 모든 패킷이 각 노드의 eth0 interface에 도착하게 되면 netfilter가 규칙에 따라 해당 패킷을 Pod로 전달합니다.
외부에서 클러스터 안으로 들어오는 클라이언트도 이와 똑같은 라우팅 방식을 이용해서 패킷을 전달해야 하는 것이 분명해 보입니다. 이것은 외부 클라이언트들도 똑같이 요청을 할때, ClusterIP나 Port를 이용하여 연결을 시도해야 합니다. 왜냐하면 ClusterIP가 각 Pod의 앞단에 위치하여 각 Pod들의 IP 주소를 알지 못해도 해당 Pod로 요청을 전달할 수 있게 해주는 역할을 해주기 때문입니다. 문제는 ClusterIP는 해당 노드의 네트워크 interface에서만 접근이 됩니다. 클러스터 외부에서는 해당 주소 대역에 대해서 전혀 알지 못합니다. 자 그럼, 어떻게 하면 외부 public IP endpoint에서 노드안에서 밖에 보이지 않는 네트워크 interfacen로 트래픽을 전달할까요?
만약에 외부에서 접근 가능한 어떤 Service IP가 있다고 가정해 봅시다. 이 Service IP는 next hop이 특정 Node로 라우팅 설정되어 있습니다. 그러면 이 Service IP(예시에서는 10.3.241.152:80)는 단지 내부 네트워크에 한정되어서 동작하지 않고 어디에서 왔는 트래픽인지 상관 없이 Node를 경유하여 원하는 Pod까지 정상적으로 패킷이 전달됩니다. 그럼 생각할 수 있는 해결책이 그냥 클라이언트에 Cluster IP를 그냥 전달하는 것은 어떨까요? 적절하게 사용자 친화적인 도메인 이름을 붙이고 해당 패킷이 어느 노드로 전달되어야 하는지에 대한 규칙과 함께 말이죠.
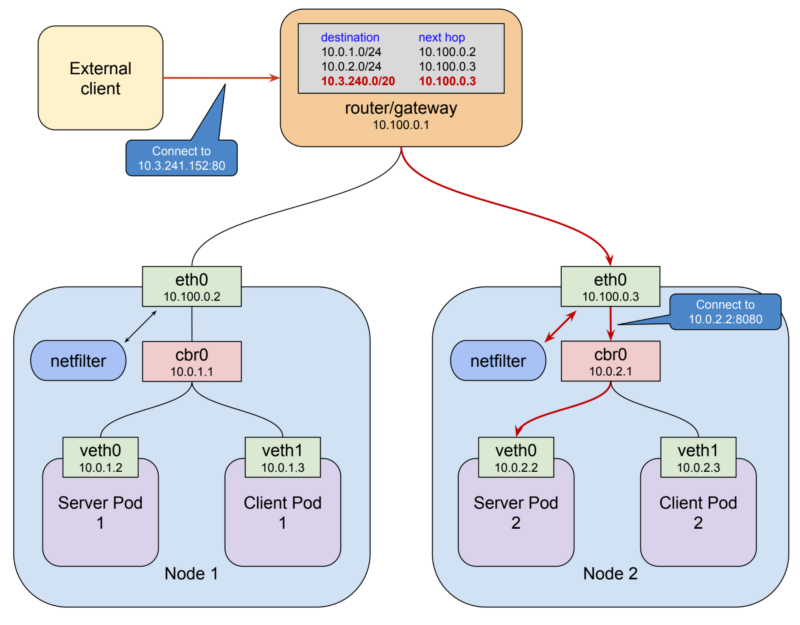
이렇게 설정한다면 실제로 잘 동작할 것입니다. 클라이언트에서 Service IP를 호출하면 정의된 라우팅 규칙에 따라 특정 노드에 전달이 되고 그 노드의 네트워크 interface에서는 기존과 같이 netfilter를 이용하여 원하는 pod로 전달이 될 것입니다. 이 방법은 괜찮아 보이지만(비록 가정이긴 하지만) 사실 큰 문제점을 가지고 있습니다. 가장 먼저 노드들 또한 마찬가지로 Pod와 같이 대체 가능한 자원(ephemeral)입니다. Pod 만큼은 아니지만 새로운 VM으로 대체될 수 있거나 클러스터가 scale up / down 할 수 있습니다. layer 3에서 동작하는 라우터들은 service가 healthy한지 아닌지 알 길이 없습니다. 그들은 단지 다음 목적지 (next hop)가 안정적으로 동작하고 정상 동작하길 바랄 뿐입니다. 만약에 노드가 더 이상 네트워크 내에 있지 않는다면 꽤 오래 시간 동안 라우팅 테이블에 문제가 생길 수 있습니다. 만약에 노드가 지속한다 하더라도 모든 트래픽이 한 노드를 거쳐가게 될 것이고 이것은 최적의(optimal) 선택이 될 수는 없습니다. (단일 장애점 발생 및 성능 측면 등)
만약에 클러스터 외부의 클라이언트 트래픽을 내부로 전달하고 싶다면 그 방법이 단일한 노드에 의한 방법이 되어서는 안될 것입니다. 이런 상황에서 단순히 라우터를 이용하여 문제를 해결할 수 있는 방법은 마땅히 없어 보입니다. 쿠버네티스의 역할을 클러스터 외부에 존재하는 라우터를 관리하는데까지 넓히는 방법에 대해서는 쿠버네티스 설계자들이 동의하지 않았습니다. 왜냐하면 클라이언트의 요청을 분산하여 노드들에게 전달해주는 존재가 이미 있기 때문입니다. 그 이름은 로드 밸런서입니다. 그리고 놀랍지 않게도 쿠버네티스에서는 이것을 이용하여 안정적으로 외부의 트래픽을 전달 받는데에 활용합니다. 이제 여러분과 layer 3 레벨을 떠나서 연결에 대해서 얘기할 시간이 되었습니다.
로드 밸런서를 이용하여 클라이언트의 트래픽을 각 노드로 분산 시키기 위해서는 먼저 클라이언트가 접속할 수 있는 공인 IP가 필요합니다. 또한 로드 밸런서에서 각 노드로 트래픽을 전달할 수 있게 각 노드의 주소들이 필요합니다. 이러한 이유 때문에 Cluster IP를 이용해서는 안정적인 라우팅 규칙을 만들어 낼 수 없습니다. 이런 service 네트워크를 제외하고 사용할 수 있을만한 네트워크는 각 노드들의 ethernet interface인 10.100.0.0/24 대역을 사용하는 것 외에는 없습니다. 노드 네트워크에 위치한 gateway 라우터에서는 이미 패킷을 각 노드로 어떻게 보낼 수 있는지 알고 있습니다.(역자주: 네트워크 관리자에 의해 제공되는 default gateway를 말합니다.) 그렇기 때문에 로드 밸런서로 보내진 패킷은 정확히 알맞는 노드로 전달될 것입니다. 그렇지만 Service 네트워크에서 80포트를 사용하고 싶다고 하더라도 직접 노드 네트워크에서 80 포트를 사용할 수는 없습니다. 그렇게 했을 경우 에러가 발생합니다.
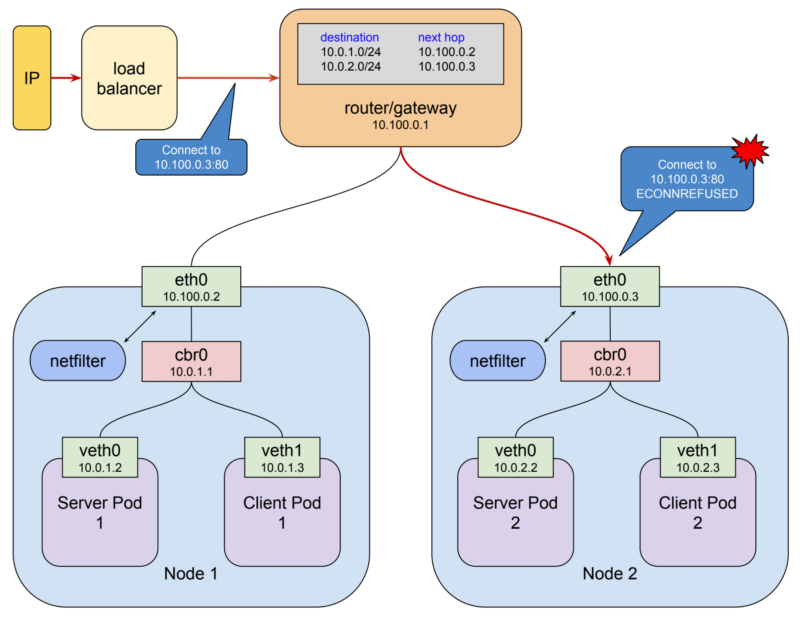
에러가 발생하는 이유는 당연합니다. 왜냐하면 실제로 해당 노드에서 80 포트를 듣고 있는 프로세스가 없기 때문입니다. (예시에서는 10.100.0.3:80 - 혹여나 있다하더라도 그것은 원래 우리가 의도한 프로세스가 아닙니다.) 또한 노드 주소를 그대로 사용한다면 netfilter에 의해서 우리가 원하는 Pod로 패킷을 전달할 수 없기 때문입니다. netfilter는 Service IP(10.3.241.152:80)를 바라보고 있지 노드의 IP를 바라보지 않습니다. 그렇기 때문에 해당 노드 interface에 도착한 패킷은 제대로 원하는 목적지에 전달되지 못하고 커널에 의해 ECONNREFUSED 에러가 발생합니다. 이것은 우리에게 딜레마를 안깁니다. netfilter에 의해 동작하는 네트워크는 노드 네트워크에서 잘 동작하지 않고 반대로 노드 네트워크에서 잘 동작하는 네트워크는 netfilter에 의해 패킷이 잘 전달되지 않습니다. 이 문제를 해결하기 위해서 이 두 네트워크를 연결해주는 bridge를 생성하는 것 외에는 방법이 없어 보입니다. 그리고 쿠버네티스에서는 바로 이 역할을 담당해주는 녀석이 존재합니다. 그 이름은 NodePort라 합니다.
NodePort Service
지난 포스트에서 service를 생성할때 특별히 서비스 타입을 지정하지 않았습니다. 그렇기 때문에 default 타입인 ClusterIP로 서비스가 생성되었습니다. 몇가지 다른 타입을 설정할 수가 있는데 여기서는 NodePort에 대해서 설명하고자 합니다. 아래의 NodePort 예시를 보시죠.
kind: Service
apiVersion: v1
metadata:
name: service-test
spec:
type: NodePort
selector:
app: service_test_pod
ports:
- port: 80
targetPort: http
NodePort 타입의 서비스는 기본적으로 ClusterIP 타입과 동일하지만 몇가지 기능들을 더 가지고 있습니다. NodePort 타입 서비스는 노드 네트워크의 IP를 통하여 접근을 할 수 있을 뿐만 아니라 ClusterIP로도 접근이 가능합니다. 이것이 가능한 이유는 매우 간단합니다. 쿠버네티스가 NodePort 타입의 서비스를 생성하면 kube-proxy가 각 노드의 eth0 네트워크 interface에 30000-32767 포트 사이의 임의의 포트를 할당합니다. (그렇기 때문에 이름이 NodePort 입니다.) 그리고 할당된 포트로 요청이 오게 되면 이것을 매핑된 ClusterIP로 전달합니다. 위의 예시 service를 생성하고 kubectl get svc service-test라고 입력하면 다음과 같이 Node에 Port가 할당된 것을 볼 수 있습니다.
$ kubectl get svc service-test
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-test 10.3.241.152 <none> 80:32213/TCP 1m
해당 예시에서는 NodePort가 32213으로 할당되었습니다. 이제 클라이언트가 10.100.0.2:32213 노드나 10.100.0.3:32213 노드 중 아무 노드에 요청을 날리게 되면 이것이 ClusterIP로 전달되게 됩니다. 이러한 방법으로 클러스터 외부의 요청이 내부의 ClusterIP까지의 전달되는 것을 알 수 있었습니다.
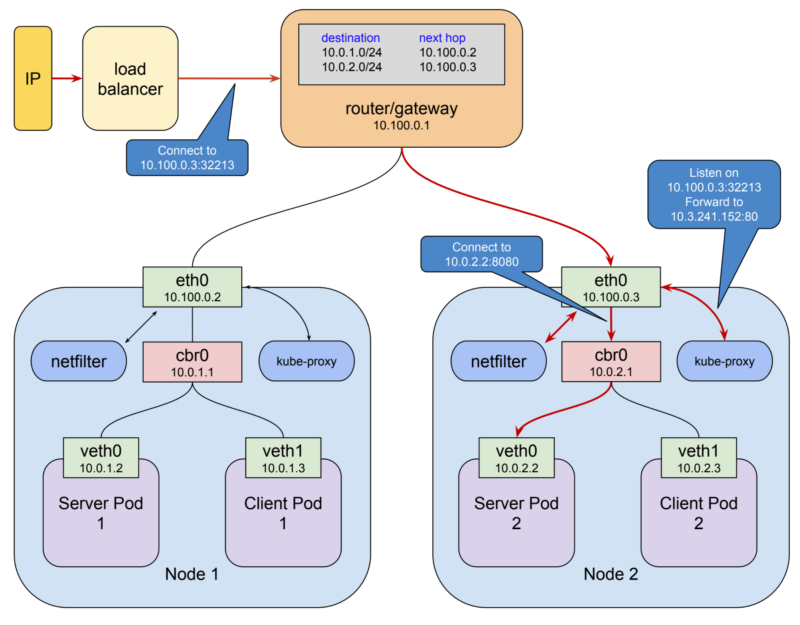
위의 그림에서 클라이언트는 로드 밸런서의 공인 IP로 연결을 합니다. 로드 밸런서는 노드 하나를 선택하여 32213 포트로 패킷을 전달합니다.(10.100.0.3:32213) kube-proxy는 해당 연결은 받아서 그것을 ClusterIP 10.3.241.152:80로 전달합니다. 그리고 이제 netfilter가 규칙이 매칭되는 것을 확인하고 최종적으로 해당 service IP를 실제 Pod IP (10.0.2.2:8080)로 바꾸어 전달합니다. 이런 일련의 과정이 조금 복잡해 보일 수도 있고 실제로도 복잡한 면이 없잖아 있습니다. 하지만 멋진 쿠버네티스의 네트워킹 기능들을 가능하게 할려면 이러한 방법 외에는 다른 간단한 방법이 있어보진 않습니다.
이러한 네트워킹 방법에 문제가 전혀 없는 것은 아닙니다. NodePort를 사용하게 되면 클라이언트 측에 non-standard 포트를 열어주어야 합니다. 하지만 로드 밸런서를 사용하게 되면 보통 이런 문제는 해결이 됩니다. 왜냐하면 로드 밸런서에서는 일반적인 포트를 열어주고 실제 NodePort의 포트는 사용자로부터 안보이게 만들어 버리면 되기 때문입니다. 하지만 Google Cloud의 내부 로드 밸런싱과 같은 경우에는 어쩔 수 없이 NodePort를 보이게끔 설정해야 할 수도 있습니다. NodePort는 또한 한정된 자원입니다. 2768개 포트는 사실 아무리 큰 클러스터에도 충분한 포트 수이긴 하지만요. 대부분의 경우에 쿠버네티스로 하여금 랜덤하게 아무 포트를 지정하게 만들어도 상관 없습니다. 하지만 필요한 경우 사용자가 직접 포트를 지정할 수도 있습니다. 마지막으로 요청자의 source IP를 의도치 않게 가린다는 제약 사항이 생깁니다. 이러한 이슈에 대해 다음 문서를 참고해 보실 수 있습니다.
NodePort는 외부 트래픽이 쿠버네티스 안으로 들어오기 위한 기초가 되는 매커니즘입니다. 하지만 그것 자체로 완전한 솔루션이 될 수 없습니다. 위와 같은 이유로 항상 로드 밸런서를 앞단에 두게 됩니다. 그것이 외부로부터든 내부로부터 오는 트래픽에 상관 없이 말이죠. 쿠버네티스 플랫폼 설계자들은 이러한 사용성을 깨닫게 되고 2개의 다른 방법을 통해 쿠버네티스를 설정할 수 있게 만들었습니다. 자, 이제 다음 내용으로 빠르게 넘어가시죠.
LoadBalancer Services and Ingress Resources
마지막 두개 컨셉은 쿠버네티스 네트워킹 중에서 가장 복잡한 기능을 담당하긴 하지만 그리 많은 시간을 들려서 설명하진 않을 것입니다. 그것은 이미 지금까지 우리가 얘기한 쿠버네티스 네트워킹 기법들을 기반하여 동작하기 때문입니다. 모든 외부 트래픽은 NodePort를 통해 클러스터 내부로 들어오게 됩니다. 쿠버네티스 설계자들은 여기까지만 만들었어도 충분했지만 로드 밸런서 API 지원이 가능한 환경에서는 쿠버네티스가 직접 이 모든 것을 담당하게 만들 수 있습니다.
첫번째로 가장 간단하게 이것을 가능하게 만들어 주는 방법이 바로 세번째 service type인 LoadBalancer 타입을 사용하는 것입니다. 말그대로 LoadBalancer 타입 서비스는 기존 NodePort 기능을 더하여 로드 밸런서를 통한 접근까지 완벽하게 해결하는 기능을 가집니다. 이것은 GCP나 AWS와 같이 API를 통하여 로드 밸런서를 생성할 수 있는 클라우드 환경을 사용한다는 것을 가정합니다.
kind: Service
apiVersion: v1
metadata:
name: service-test
spec:
type: LoadBalancer
selector:
app: service_test_pod
ports:
- port: 80
targetPort: http
기존의 Service를 지우고 위와 같은 형식의 service를 GKE에 다시 생성하여 kubectl get svc service-test 명령을 내리게 되면 다음과 같이 외부 공인 IP가 생성된 것을 바로 확인할 수 있습니다. (35.184.97.156)
$ kubectl get svc service-test
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
openvpn 10.3.241.52 35.184.97.156 80:32213/TCP 5m
제가 “바로”라고 했지만 사실 외부 공인 IP가 할당되기 위해서 수분이 걸릴 수도 있습니다. 이는 생성되어야 할 리소스들의 양에 비하면 그리 놀랄 일이 아닙니다. GCP를 예로 들자면, 먼저 forwarding rule이 설정되어야 하고 target proxy, 백엔드 서비스와 instance group, 마지막으로 외부 공인 IP가 생성되어야 합니다. (전부 GCP에서 사용하는 용어들입니다 - On GCP, for example, this requires the system to create an external IP, a forwarding rule, a target proxy, a backend service, and possibly an instance group.)
일단 공인 IP가 만들어졌다면 해당 IP를 통해서 서비스에 접속할 수 있습니다. 해당 IP에 도메인 네임을 지정하고 사용자에게 전달할 수 있습니다. 그렇게 되면 서비스가 삭제되거나 새롭게 만들어지지 않는 이상, IP가 바뀔리가 없습니다.
LoadBalancer 서비스 타입에는 몇가지 제약 사항이 있습니다. 먼저 TLS termination 설정이 불가능 합니다. 또한 virtual host나 path-base routing (L7 layer routing)이 불가능합니다. 그렇기 때문에 한개의 로드 밸런서를 이용하여 여러 서비스에 연결을 하는 것이 불가능합니다. 이러한 제약 사항 때문에 쿠버네티스 1.2 버젼에서는 Ingress라는 서비스 타입을 제공하기 시작했습니다. LoadBalancer 서비스 타입은 단지 한개의 내부 서비스를 외부 사용자들에게 접근 가능하도록 만드는 일을 담당합니다. 반대로 Ingress 서비스 타입은 여러개의 서비스가 한개 로드 밸런서를 통해 유연한 설정을 할 수 있게 만듭니다. Ingress API는 TLS termination이나 virtual hosts, path-based routing을 가능하게 합니다. Ingress를 이용하면 쉽게 한개의 로드 밸런서로 여러개의 backend 서비스들을 연결할 수 있게 만들어 줍니다.
Ingress API는 너무 양이 방대하여 여기에서 모든 것을 얘기하는 것은 힘들 것 같습니다. 또한 Ingress 자체는 우리가 배운 쿠버네티스 네트워크와 크게 더 더해지는 것이 없습니다. 그 구현 자체는 지금까지 배운 쿠버네티스의 패턴과 크게 다르지 않습니다. 리소스 타입과 그 리소스 타입을 관리하는 컨트롤러가 존재합니다. 여기서 리소스는 Ingress이고 그것을 Ingres-controller가 관리합니다. 아래의 코드가 Ingress 리소스 예시입니다.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
annotations:
kubernetes.io/ingress.class: "gce"
spec:
tls:
- secretName: my-ssl-secret
rules:
- host: testhost.com
http:
paths:
- path: /*
backend:
serviceName: service-test
servicePort: 80
Ingress-controller는 위의 방식대로 들어오는 요청을 적절한 서비스로 전달해야 하는 역할을 담당합니다. Ingress를 사용할 때, 요청 받을 서비스를 NodePort 타입으로 설정을 하고 Ingress-controller로 하여금 어떻게 요청을 각 노드에 전달할지 파악하게 합니다. 각 클라우드 플랫폼 마다의 Ingress-controller 구현체가 있습니다. GCP에서는 cloud load balancer가 있고 AWS에서는 elastic load balancer가 있고 오픈소스로는 nginx나 haproxy 등이 있습니다. 한가지 주의해야 할 점은, 어떤 환경에서는 LoadBalancer 타입과 Ingress를 같이 쓰면 작은 이슈가 생각는 것을 유의하시기 바랍니다. 대부분의 경우 이상 없이 동작하겠지만 일반적으로는 간단한 서비스에도 Ingress만 사용하길 권장 드립니다.
HostPort and HostNetwork
마지막 두개 소개하고 싶은 내용은 실질적으로 사용하는 방법이라기 보다는 실험용입니다. 사실 99.99%의 경우 anti-pattern으로 사용될 것이고 실제로 사용하는 곳이 있다면 전체적으로 아키텍처 디자인 리뷰를 다시 받아 봐야할 것입니다. 그렇기 때문에 아예 설명에서 빠트릴까도 생각했지만 이러한 방법 또한 네트워킹 방법 중 하나이기에 간단하게나마 설명 들릴까 합니다.
첫번째는 HostPort입니다. 이것은 컨테이너의 기능 중 하나입니다. 만약 특정 포트 번호를 노드에 열게 되면 해당 노드의 해당 포트로 들어오는 요청은 곧바로 컨테이너로 직접 전달이 됩니다. proxying 되지 않으며 해당 컨테이너가 위치한 노드의 포트만 열립니다. 쿠버네티스에 DaemonSets과StatefulSets과 같은 리소스가 존재하지 않았을 때 사용하던 기법으로 오직 한개의 컨테이너만 어느 한개의 노드 위에 실행되길 바랄 때 사용하였습니다. 예를 들어 elasticsearch 클러스터를 생성할 때 HostPort를 9200으로 설정하고 각 컨테이너들이 마치 elasticsearch의 노드처럼 인식되게 만들었습니다. 현재는 이러한 방법을 사용하지 않기 때문에 쿠버네티스 컴포넌트를 개발하는 사람이 아닌 이상 사용할 일이 거의 없습니다.
두번째 HostNetwork는 더 이상한 방법입니다. 이것은 Pod의 기능 중 하나인데요, 해당 필드의 값을 true로 설정하면 도커를 실행할 때 --network=host로 설정한 것과 똑같은 효과를 얻을 수 있습니다. 이것은 Pod안에 들어있는 모든 컨테이너들이 노드의 네트워크 namespace와 동일한 네트워크를 사용하게끔 만듭니다. (모두가 eth0를 접근할 수 있다는 것이지요.) 제 생각에는 아마도 이것을 사용할 일이 없을 것 같습니다. 혹여나 사용 한다고 하더라도 그것은 아마 여러분이 이미 쿠버네티스 전문가일 가능성이 높고 그렇다면 저의 도움이 필요하지 않을 것 같습니다.
마무리하며
이것으로 쿠버네티스 네트워크 3편의 시리즈를 마무리하겠습니다. 저는 개인적으로 쿠버네티스 플랫폼이 어떻게 동작하는지 배우고 알아가는 것이 즐거웠습니다. 여러분도 제 글을 읽으면서 그것을 느꼈길 바랍니다. 제 생각에는 쿠버네티스가 사람들로 하여금 손쉽게 컨테이너 orchestration을 할 수 있게 만들었다고 생각합니다. 많은 경우, 쿠버네티스는 정말로 데이터센터를 위한 기술인 것 같습니다. 그렇기 때문에 그 아래에는 약간의 복잡한 부분이 있지 않은가 생각합니다. 제가 이 포스트들을 작성한 이유는 한번 쿠버네티스 네트워크가 어떻게 동작하는지 이해할 수 있게 된다면 모든 것이 꽤나 자연스럽게 연결되는 것을 알 수 있기 때문입니다. 제 글을 통해서 많은 사람들이 조금 더 쉽게 쿠버네티스를 이해하는데 도움이 되었길 바랍니다.