![[번역] 쿠버네티스 네트워킹 이해하기#2: Services](/assets/images/k8s_network/landing02.png)
[번역] 쿠버네티스 네트워킹 이해하기#2: Services
12 min read
쿠버네티스 네트워킹 이해하기 시리즈 중 첫번째 포스트에서는 쿠버네티스가 가상 네트워크 device와 라우팅 규칙을 이용하여 한 Pod가 다른 Pod와 어떻게 통신하는지 알아봤습니다. 이번 글에서는 Service라는 리소스에 대해 알아보고 한 Pod가 어떻게 Service와 통신을 할 수 있는지 알아보도록 하겠습니다.
쿠버네티스 네트워킹 이해하기 시리즈
- #1 Pods 네트워크
- #2 Service 네트워크
- #3 Ingress 네트워크
첫번째 포스트에서는 클라이언트 Pod에서 서버 Pod의 IP를 알고 있는 상황을 가정하여 살펴 보았습니다. 만약 Pod끼리의 통신이 어떻게 작동하는지 정확하기 알지 못한다면 이전 글을 읽어볼 것을 권합니다. 클러스터 내에서의 Pod 네트워킹은 꽤나 잘 만들었습니다. 하지만 그것만으로는 내구성을 가진 시스템을 만들기에는 조금 부족합니다. 그 이유는 쿠버네티스에서 Pod는 쉽게 대체될 수 있는 존재이기 때문입니다. (pods are ephemeral) Pod IP를 어떤 서비스의 Endpoint로 설정하는 것은 가능합니다. 하지만 Pod가 새로 생성되었을 때 그 주소가 같을 것이라고는 보장하지 못합니다.
사실 이러한 문제는 예전 문제이고 이미 우리에겐 정해진 해결책이 있습니다. 바로 서비스 앞단에 reverse-proxy (혹은 load balancer)를 위치시키는 것이죠. 클라이언트에서 proxy로 연결을 하면 proxy의 역할은 서버들 목록을 관리하며 현재 살아있는 서버에게 트래픽을 전달하는 것입니다. 이는 proxy 서버가 몇가지 요구사항을 만족해야합니다. proxy 서버 스스로 내구성이 있어야 하며 장애에 대응할 수 있어야 합니다. 또한 트래픽을 전달할 서버 리스트를 가지고 있어야 하고 해당 서버가 정상적인지 확인할 수 있는 방법을 알아야 합니다. 쿠버네티스 설계자들은 이 문제를 굉장히 우아한 방법으로 풀었습니다. 그들은 기존의 시스템을 잘 활용하여 위의 3가지 요구사항을 만족하는 것을 만들었고 그것을 service 리소스 타입이라고 정의하였습니다.

Services
첫번째 포스트에서 가상의 클러스터 안에서 두개의 포드가 서로 다른 노드에 걸처 어떻게 통신하는지 살펴보았습니다. 이번 포스트에서는 첫 번째의 예시를 바탕으로 쿠버네티스 서비스가 클라이언트와는 상관 없이 어떻게 여러 포드에 걸처 로드밸런싱을 하는지 살펴보겠습니다. 서버 포드를 생성하기 위해서 deployment object를 다음과 같이 작성하면 됩니다.
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: service-test
spec:
replicas: 2
selector:
matchLabels:
app: service_test_pod
template:
metadata:
labels:
app: service_test_pod
spec:
containers:
- name: simple-http
image: python:2.7
imagePullPolicy: IfNotPresent
command: ["/bin/bash"]
args: ["-c", "echo \"<p>Hello from $(hostname)</p>\" > index.html; python -m SimpleHTTPServer 8080"]
ports:
- name: http
containerPort: 8080
위의 deployment는 두개의 간단한 http 서버 포드를 생성하고 8080 포트를 통해 각 포드의 hostname을 리턴해줍니다. kubectl apply를 통해 deployment를 생성한 이후, 포드가 클러스터에 돌고 있는 것을 확인할 수 있습니다. 그리고 다음과 같은 명령으로 포드의 네트워크 주소를 알 수 있습니다.
$ kubectl apply -f test-deployment.yaml
deployment "service-test" created
$ kubectl get pods
service-test-6ffd9ddbbf-kf4j2 1/1 Running 0 15s
service-test-6ffd9ddbbf-qs2j6 1/1 Running 0 15s**
$ kubectl get pods --selector=app=service_test_pod -o jsonpath='{.items[*].status.podIP}'
10.0.1.2 10.0.2.2**
이제 서버 포드가 제대로 동작하는 것을 확인해 보기 위해 서버에 요청을 날리고 결과를 output하는 클라이언트 포드를 하나 생성하겠습니다.
apiVersion: v1
kind: Pod
metadata:
name: service-test-client1
spec:
restartPolicy: Never
containers:
- name: test-client1
image: alpine
command: ["/bin/sh"]
args: ["-c", "echo 'GET / HTTP/1.1\r\n\r\n' | nc 10.0.2.2 8080"]
클라이언트 포드를 하나를 실행하고 난 뒤 포드를 살펴 보면 completed 상태로 된 것을 확인할 수 있고 kubectl logs 명령을 통해 실제 결과값을 확인할 수 있습니다:
$ kubectl logs service-test-client1
HTTP/1.0 200 OK
<!-- blah -->
<p>Hello from service-test-6ffd9ddbbf-kf4j2</p>
해당 예시에서 아무도 클라이언트 포드가 어느 노드에서 실행되었는지 알려주지 않지만 그것과는 상관 없이 클라이언트 포드가 서버 포드로 요청을 날려서 response를 받았다는 것을 알 수 있습니다. 이것은 바로 포드 네트워크 매카니즘 덕분입니다. 하지만 만약에 서버 포드가 죽거나 재시작하거나, 혹은 다른 노드로 재배치된다면 서버 포드의 IP가 아마도 바뀌고 될 것이고 클라이언트 포드에서는 이것을 알지 못하여 문제가 발생할 것입니다. 이러한 문제를 해결하기 위해 Service라는 것을 이용합니다.
Service 란 쿠버네티스 리소스 타입 중 하나로 각 포드로 traffic을 포워딩해주는 프록시 역할을 합니다. 이때 selector라는 것을 이용하여 traffic 전달을 받을 포드들을 결정합니다. 이것은 포드가 생성될 때 label을 부여하여 선택할 수 있게 합니다. service를 하나 생성하게 되면 해당 서비스에 IP 주소가 부여된 것을 알 수 있고 80 포트를 통해 요청을 받는 것을 알 수 있습니다.
$ kubectl get service service-test**
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-test 10.3.241.152 <none> 80/TCP 11s
service에 IP 주소로 직접 요청을 할 수도 있지만 DNS 이름을 이용하여 요청할 수 있으면 더 좋겠죠. 다행이 쿠버네티스에서는 이용하여 service 이름을 DNS 이름으로 사용할 수 있게 내부 클러스터 DNS를 제공해줍니다. 그럼 클라이언트 포드를 다음과 같이 조금 바꿔볼까요?
apiVersion: v1
kind: Pod
metadata:
name: service-test-client2
spec:
restartPolicy: Never
containers:
- name: test-client2
image: alpine
command: ["/bin/sh"]
args: ["-c", "echo 'GET / HTTP/1.1\r\n\r\n' | nc service-test 80"]
해당 포드를 실행하고 output을 보면 service가 클라이언트의 요청을 현재 http 포드 중 하나로 전달해 준 것을 확인할 수 있습니다.
$ kubectl logs service-test-client2
HTTP/1.0 200 OK
<!-- blah -->
<p>Hello from service-test-6ffd9ddbbf-kf4j2</p>
계속해서 클라이언트 포드를 실행하면 약 50% 비율로 각 http 포드가 response를 리턴하는 것을 확인할 수 있습니다. 대체 어떠한 방법으로 service가 동작하는지 궁금하다면 service IP가 할당된 방법에 대해서 먼저 알아보는게 제일 좋을 것 같습니다.
Service 네트워크
test service에 할당된 IP는 네트워크에 있는 주소인 것을 확인할 수 있습니다. 하지만 그 IP대역이 Pod들과는 조금 다르다는 것을 알 수 있습니다.
| 종류 | IP | Network |
|---|---|---|
| pod1 | 10.0.1.2 | 10.0.0.0/14 |
| pod2 | 10.0.2.2 | 10.0.0.0/14 |
| service | 10.3.241.152 | 10.3.240.0/20 |
실제 Pod network 대역대와 service network 대역대를 확인하려면 단순히 kubectl을 이용하여 알 수는 없으며 구축한 클러스터 방법마다 조금씩 상이합니다. 자세한 방법은 다음 페이지들을 참고해보시기 바랍니다.
- 자체 구축시: kubelet에서 –pod-cidr 값 확인 kube-apiserver에서 –service-cluster-ip-range 값 확인
- GCP를 이용하였을 때
$ gcloud container clusters describe test | grep servicesIpv4Cidr - EKS를 이용하였을 때 현재(2018년 5월)까진 10.100.x.x/16 혹은 172.20.x.x/16 대역대만 가능1
여기에 정의된 네트워크 주소 공간을 쿠버네티스에서는 service network라고 합니다. 모든 service는 이러한 주소를 할당 받게 되어 있습니다. service에는 여러 타입의 service가 존재하고 ClusterIP가 가장 기본이 되는 타입입니다. ClusterIP의 뜻은 클러스터 내의 모든 Pod가 해당 Cluster IP 주소로 접근을 할 수 있다는 뜻입니다. kubectl describe service 라는 명령을 통해 더 자세한 정보를 확인할 수 있습니다.
$ kubectl describe services service-test
Name: service-test
Namespace: default
Labels: <none>
Selector: app=service_test_pod
Type: ClusterIP
IP: 10.3.241.152
Port: http 80/TCP
Endpoints: 10.0.1.2:8080,10.0.2.2:8080
Session Affinity: None
Events: <none>
Pod 네트워크와 동일하게 service 네트워크 또한 가상 IP 주소입니다. 하지만 Pod 네트워크와는 조금 다르게 동작합니다. 먼저 Pod 네트워크가 10.0.0.0/14의 대역대를 가진다고 생각해 봅시다. 만약 실제 host에 가서 직접 bridge와 interface를 확인하시면 device들이 존재하는 것을 확인할 수 있습니다. 이것은 가상 ethernet interfacen들이 pod끼리 통신하기 위해 bridge와 연결된 device입니다. 이제 service network를 확인해 보겠습니다. 예시에서는 service 네트워크의 대역대가 10.3.240.0/20입니다. 직접 노드에서 ifconfig 명령을 내리더라도 이와 관련된 아무런 네트워크 device도 나오지 않는 것을 볼 수 있습니다. 아니면 각 노드들을 전부 연결하는 게이트웨이의 routing 테이블을 확인해 보아도 아무런 service 네트워크에 대한 라우팅 정보가 없는 것을 확인할 수 있습니다. service 네트워크는 적어도 이런 방식을 통해서 구성되어 있지 않을 것을 알 수 있습니다. 그럼에도 불구하고 위의 예시에서 service IP로 요청을 하게 되면 어떠한 방법을 통해서인지는 몰라도 그 요청이 pod 네트워크에 존재하는 Pod로 전달되는 것을 확인할 수 있었습니다. 이제부터 어떤 방법이 통하여 이것을 가능하게 했는지 확인해 보도록 하겠습니다.
먼저 다음과 같은 Pod 네트워크가 구성되어 있다고 생각해 봅시다.
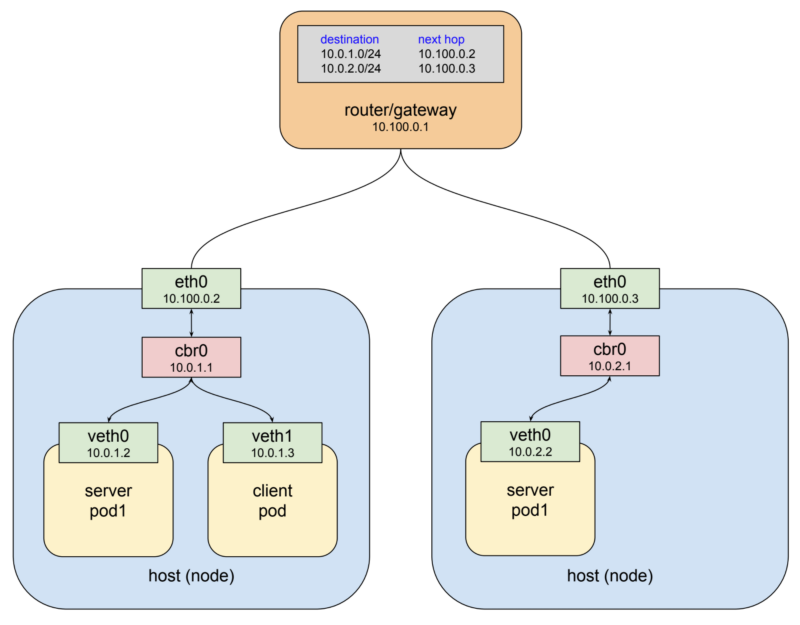
위의 도표를 보시면 두개의 노드가 있고 게이트웨이를 통해 서로 연결되어 있습니다. 게이트웨이의 라우팅 테이블에는 Pod 네트워크를 위한 정보가 적혀져 있습니다. 총 3개의 Pod가 있는데 1개의 클라이언트 Pod와 1개의 서버 Pod가 한쪽 노드에, 다른 노드에서는 1개의 서버 Pod가 존재합니다. 클라이언트가 http request를 service-test라는 DNS 이름으로 요청합니다. 클러스터 DNS 서버가 해당 이름을 service IP(예시로 10.3.241.152)로 매핑 시켜 줍니다. http 클라이언트는 DNS로부터 IP를 이용하여 최종적으로 요청을 보내게 됩니다.
IP 네트워크는 보통 자신의 host에서 목적지를 찾지 못하게 되면 상위 게이트웨이로 전달하도록 동작합니다. 예시에서 보자면 Pod안에 들어있는 첫번째 가상 ethernet interface에서 IP를 보게 되고 10.3.241.152라는 주소에 대해 전혀 알지 못하기 때문에 다음 게이트웨이(bridge cbr0)로 패킷을 넘기게 됩니다. Bridge의 역할을 꽤나 단순합니다. bridge로 오고 가는 패킷을 단순히 다음 network node의 interface로 전달하는 역할만을 합니다.
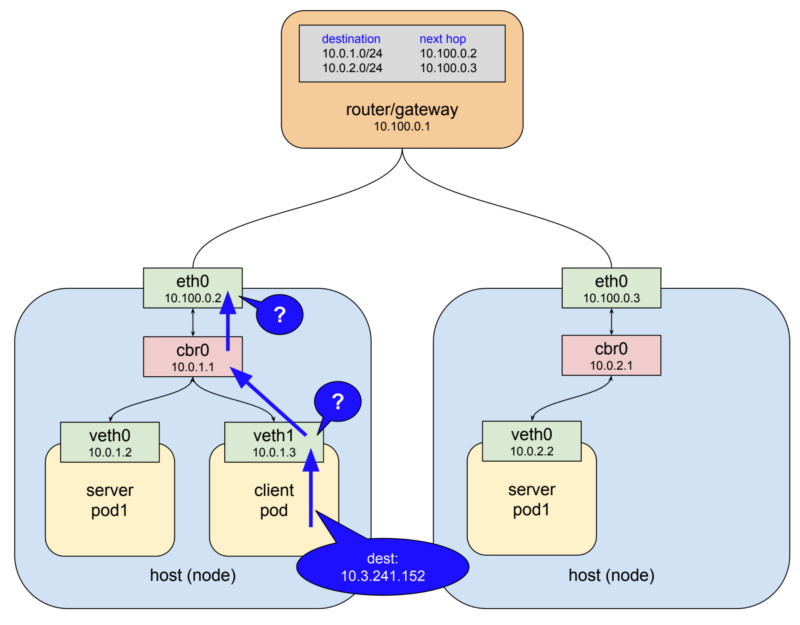
예시에서, 노드의 ethernet interface의 대역대는 10.100.0.0/24입니다. 마찬가지로 노드에서도 10.3.241.152의 주소에 대해서 알지 못하기 때문에 보통이라면 최상위에 존재하는 게이트웨이로 전달될 것입니다. 하지만 여기서는 특별하게 갑자기 패킷의 주소가 변경되어 server Pod 중 하나로 패킷이 전달되게 됩니다. (굳이 같은 host인 server Pod(10.0.1.2) 뿐만 아니라 다른 host에 존재하는 Pod(10.0.2.2)로도 전달이 가능합니다.)
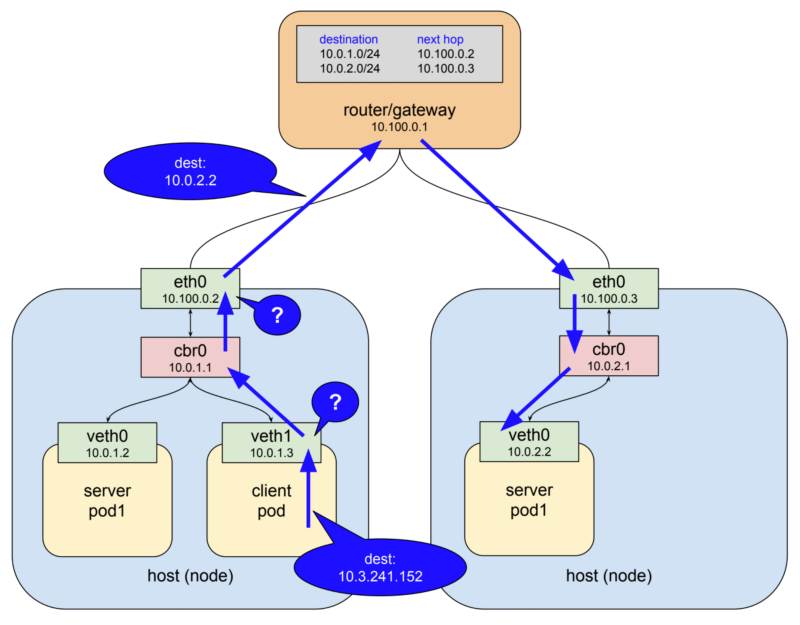
3년 전 쿠버네티스를 막 사용하기 시작했을 때 위와 같은 네트워킹 방식에 대해서 꽤나 신기해 했었습니다. 대체 어떤 방법인지는 몰라도 클라이언트 Pod가 service IP에 대한 interface device가 없음에도 불구하고(물리이든 가상이든) server Pod와 정확하게 통신할 수 있었습니다. 나중에 알게된 것은 이러한 방식이 가능하게 했던 것은 바로 쿠버네티스의 컴포넌트 중 하나인 kube-proxy라는 녀석 때문이라는 것을 알게 되었습니다.
kube-proxy
쿠버네티스의 다른 모든 것과 마찬가지로 service 또한 하나의 쿠버네티스 resource에 불과합니다. 그것은 어떤 소프트웨어를 어떻게 설정해야 하는지에 대한 정보가 저장되어 있는 리소스였습니다. 사실 serivce를 하나 등록하게 되면 쿠버네티스의 여러 컴포넌트들에 영향을 미치게 되는데 오늘 여기에서는 위의 예시를 가능하게 만들었던 kube-proxy에 대해서만 살펴보도록 하겠습니다. 많은 분들은 kube-proxy라는 이름에서 벌써 어떤 녀석인지를 유추할 수 있을텐데요, kube-proxy는 haproxy 나 linkerd와 같이 보통의 reverse-proxy와는 조금 다른 부분들이 있습니다.
proxy의 일반적인 역할은 서로 열린 connection을 통해 클라이언트와 서버의 트래픽을 전달하는데 있습니다. 클라이언트는 service port로 inbound 연결을 하게 되고 proxy에서 서버로 outbound 연결을 합니다. 이런 종류의 proxy 서버들은 전부 user space에서 동작하기 때문에 모든 패킷들은 user space를 지나 다시 kernel space를 거쳐서 proxy됩니다. kube-proxy도 마찬가지로 user space proxy로 구현되어 있는데 기존의 proxy와는 약간 다른 방법으로 구현되어 있습니다. proxy는 기본적으로 interface device가 필요합니다. 클라이언트와 서버 모두 연결을 맺을 때 필요합니다. 이때 우리가 사용할 수 있는 interface는 host에 존재하는 ethernet interface이거나 Pod내에 존재하는 가상 ethernet interface 두개 뿐입니다.
그 두가지 네트워크 중 하나를 이용하는 건 어떨까요? 필자가 쿠버네티스의 내부 지식에 대해 많이 알지는 못하지만 제가 생각하기로는, 초기 프로젝트에서 이러한 방식으로 네트워크를 구성하는 것은 나중에 라우팅 규칙을 굉장히 복잡하게 만든다는 것을 깨달았기 때문이라고 생각합니다. 왜냐하면 이러한 네트워크 구조는 Pod나 Node처럼 쉽게 대체될 수 있는 개체를 위해 설계되었기 때문입니다. Service는 이와 다르게 조금 더 독립적이고 안정적이며 기존의 네트워크 주소 공간과는 겹치지 않는 네트워크 구조가 필요했고 가상 IP 구조가 가장 적합했습니다. 하지만 앞서 보았듯이 실제 device들이 존재하지 않았습니다. 우리는 가상의 device를 이용하여 포트를 열고 커넥션을 맺을 수 있습니다만 아예 존재하지 않는 device를 이용할 수는 없습니다.
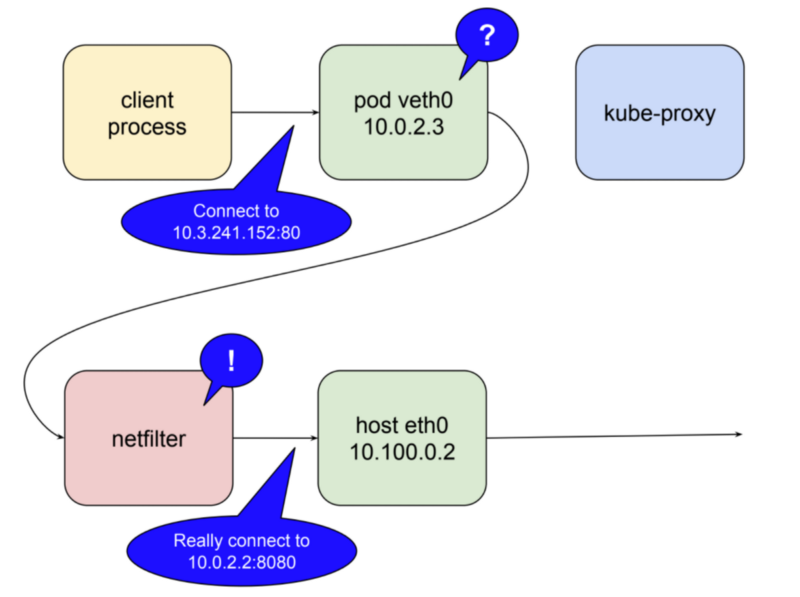
쿠버네티스는 리눅스 커널의 기능 중 하나인 netfilter와 user space에 존재하는 interface인 iptables라는 녀석들을 이용하여 해결합니다. 이 포스트에서는 그 두가지를 자세히 다루지는 않을 것입니다만 조금 더 깊게 알아보고 싶으시다면 netfilter page 페이지가 시작하기에 좋을 것입니다. 짧게 요약하자면, netfilter란 Rule-based 패킷 처리 엔진입니다. kernel space에 위치하며 모든 오고 가는 패킷의 생명주기를 관찰합니다. 그리고 규칙에 매칭되는 패킷을 발견하면 미리 정의된 action을 수행합니다. 많은 action들 중에 특별히 destination의 주소를 변경할 수 있는 action도 있습니다. 바로 그렇습니다. netfilter란 kernel space에 존재하는 proxy입니다. 아래 도표는 kube-proxy가 user space proxy로 실행될때 netfilter의 역할에 대해서 설명합니다.
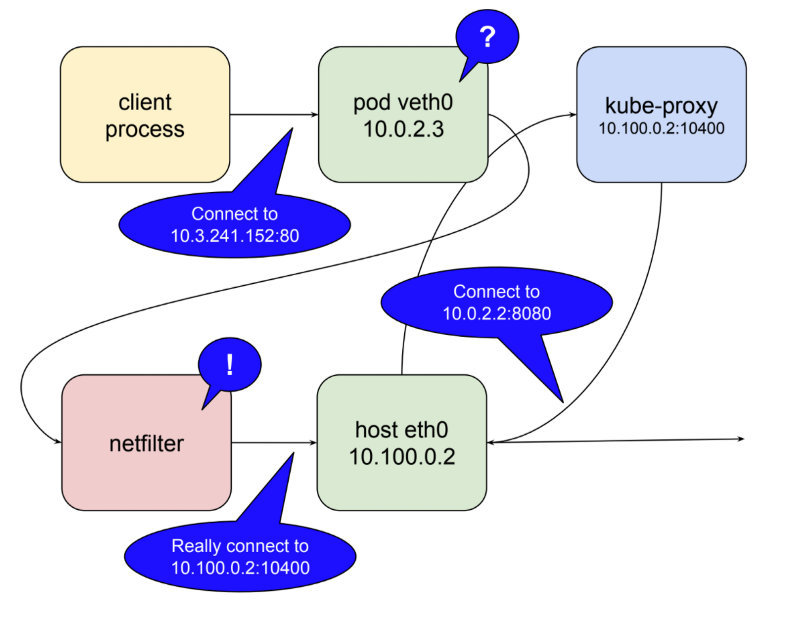
kube-proxy가 user space mode2로 동작할 때,
- kube-proxy가 localhost interface에서
service의 요청을 받아내기 위해 10400 포트(예제 기준)를 엽니다. - netfilter로 하여금
serviceIP로 들어오는 패킷을 kube-proxy 자신에게 라우팅 되도록 설정을 합니다. - kube-proxy로 들어온 요청을 실제 server Pod의 IP:Port로 요청을 전달합니다. (예제에서는 10.0.2.2:8080)
이러한 방법을 통해 service IP 10.3.241.152:80로 들어온 요청을 마법처럼 실제 server Pod가 위치한 10.0.2.2:8080로 전달할 수 있습니다. netfilter의 능력을 보자면, 이 모든 것을 하기 위해서는 단지 kube-proxy가 자신의 포트를 열고 마스터 api 서버로 부터 전달 받은 service 정보를 netfilter에 알맞는 규칙으로 입력하는 것 외엔 다른 것이 필요 없습니다.
한가지 조금 더 설명드릴 것이 있습니다. 앞서 설명 드렸듯이 user space에서 proxying을 하는 것은 모든 패킷을 user space에서 kernel space로 변환을 해야하기 때문에 그만큼 비용이 듭니다. 쿠버네티스 1.2 kube-proxy에서는 이것을 해결하기 위해 iptables mode가 생겼습니다. 이 모드에서는 kube-proxy가 직접 proxy의 역할을 수행하지 않고 그 역할을 전부 netfilter에게 맡겼습니다. 이를 통해 service IP를 발견하고 그것을 실제 Pod로 전달하는 것은 모두 netfilter가 담당하게 되었고 kube-proxy는 단순히 이 netfilter의 규칙을 알맞게 수정하는 것을 담당할 뿐입니다3.
마무리하기 전에, 이러한 방식이 맨 처음에 언급하였던 요구사항인 reliable한 proxy인지 생각해 보겠습니다.
1. 과연 kube-proxy가 내구성 있는 시스템일까요?
kube-proxy는 기본적으로 systemd unit으로 동작하거나 daemonset으로 설치가 됩니다. 그렇기 때문에 프로세스가 죽어도 다시 살아날 수 있습니다. kube-proxy가 user space 모드로 동작할 때는 단일 지점 장애점이 될 수 있습니다. 하지만 iptables 모드로 동작할 때는 꽤나 안정적으로 동작할수 있습니다. 왜냐하면 이는 netfilter를 통해 동작하고 서버가 살아있는 한 netfilter도 동작하는 것을 보장 받을 수 있기 때문입니다.
2. servicce proxy가 healthy server pod를 감지할 수 있을까요?
위에 언급했듯이 kube-proxy는 마스터 api 서버의 정보를 수신하기 때문에 클러스터의 변화를 감지합니다. 이를 통해 지속적으로 iptables을 업데이트하여 netfilter의 규칙을 최신합니다. 새로운 service가 생성되면 kube-proxy는 알림 받게 되고 그에 맞는 규칙을 생성합니다. 반대로 service가 삭제되면 이와 비슷한 방법으로 규칙을 삭제합니다. 서버의 health check는 kubelet을 통하여 수행합니다. kubelet은 또다른 서버에 설치되는 쿠버네티스의 컴포넌트 중 하나입니다. 이 kubelet이 서버의 health check을 수행하여 문제를 발견시 마스터 api 서버를 통해 kube-proxy에게 알려 unhealthy Pod의 endpoint를 제거합니다.
이러한 방법을 통해 각 Pod들이 proxy를 통해 서로 통신할때 고가용한 시스템을 구축할 수 있게 합니다. 반대로 이러한 시스템의 단점이 아예 없는 것은 아닙니다. 가장 먼저 생각할 수 있는 부분은 이러한 방식을 이용하면 클러스터 안의 Pod에서 요청한 request만 위와 같은 방식으로 동작합니다. 다음으로는 netfilter를 사용하는 방식 때문에 외부에서 들어온 요청에 대해서는 원 요청자의 origin IP가 수정되어 들어오게 됩니다. 이러한 문제는 여러 활발한 토론의 대상이 됩니다. 다음 포스트에서 ingress에 대해서 설명 드릴때 이러한 문제에 대해서 조금 더 깊게 짚고 넘어가겠습니다.