![[번역] 쿠버네티스 네트워킹 이해하기#1: Pods](/assets/images/k8s_network/landing01.png)
[번역] 쿠버네티스 네트워킹 이해하기#1: Pods
7 min read
해당 포스트는 제가 CKA 자격증 취득을 위해 쿠버네티스 network에 대해 공부할 때 굉장히 도움이 되었던 글로써, 많은 분들이 쿠버네티스를 공부하는데에 도움이 되길 바라는 마음에서 번역해 보았습니다.
쿠버네티스 네트워킹 이해하기 시리즈
- #1 Pods 네트워크
- #2 Service 네트워크
- #3 Ingress 네트워크
이 포스트에서는 쿠버네티스 클러스터에서 동작하는 여러 네트워크 layer에 대해서 파헤쳐 보겠습니다. 쿠버네티스는 많은 훌륭한 디자인을 품고 있는 강력한 플랫폼입니다. 그러나 그 동작 방식을 생각해 보는 것은 헷갈릴 수 있습니다. Pod 네트워크, Service 네티워크, Cluster IP, container ports, host ports, node ports.. 많은 분들이 힘들어하는 것을 봤습니다. 저희는 보통 이러한 얘기들을 회사에서 자주 얘기하죠. 어떤 문제가 발생하였을 때 전체 layer를 살펴 보며 문제의 원인을 파악하려고 합니다. 하지만 각 layer별로 어떤 역할을 하는지 쪼개어 이해한다면 보다 우아한 방법으로 전체를 이해할 수 있을 것입니다.
각 부분별로 명확하기 위해 3개 포스트로 나눠서 얘기드리겠습니다. 첫번째에서는 container와 pod에 대해서 설명하겠습니다. 두번째에서는 service에 대해서 설명 드리겠습니다. service는 pod들이 사용 중에 다른 pod로 교체되어도 문제 없게 만들어 줍니다. 마지막 포스트에서는 ingress에 대해서 설명 드리겠습니다. 이것은 cluster 외부에서 pod 안으로 트래픽이 어떻게 들어오는가에 대한 얘기가 되겠습니다. 몇가지 미리 말씀 드릴 사항이 있습니다. 해당 포스트는 컨테이너, 쿠버네티스 기초 내용에 대한 글이 아닙니다. 컨테이너가 어떻게 동작하는지에 대해 더 알고 싶다면 여기를 보시고 쿠버네티스에 대한 전반적인 개념에 대해서 원하신다면 여기를 참고하시고 Pod에 대한 상세 내용은 여기를 참고하시기 바랍니다. 마지막으로 기본적인 네트워킹 개념과 IP 주소 공간을 미리 아신다면 도움이 되실 겁니다.
Pods
그럼 Pod란 무엇일까요? Pod는 적어도 한개 이상의 컨테이너를 구성하고 같은 host와 network 스택을 공유하고 volume과 같은 리소스들을 공유할 수 있습니다. Pod는 쿠버네티스의 기장 기본이 되는 단위입니다. 그렇다면 “네트워크 스택을 공유한다”는 의미는 무엇일까요? 그것은 Pod 안의 모든 컨테이너가 localhost를 통해 서로에게 도달이 가능하다는 것을 의미합니다. 예를 들어, 80포트를 이용하고 있는 nginx 컨테이너가 있으면 scrapyd를 실행하고 있는 다른 컨테이너에서 http://localhost:80 으로 첫번째 컨테이너에 접근할 수 있습니다. 어떻게 동작하는 것일까요?
먼저 컨테이너 한개를 실행하게 되면 어떤 일이 벌어지는지 살펴보도록 보겠습니다.
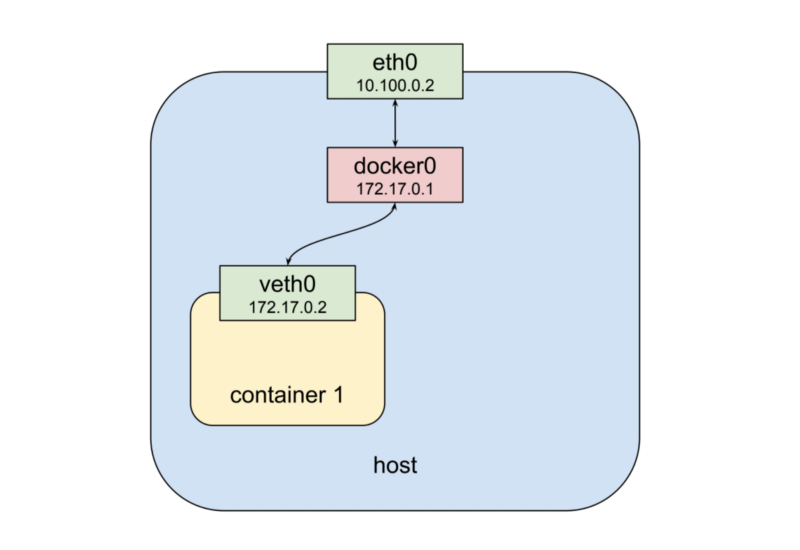
위에서부터 아래로 저희는 physical network interface인 eth0을 볼 수 있습니다. 거기에는 docker0이라는 bridge가 달려 있습니다. 그리고 docker0 bridge에는 다시 virtual network interface인 veth0이 연결되어 있습니다. 먼저 docker0과 veth0은 예시에서 172.17.0.0/24 처럼 같은 네트워크로 묶여 있는 것을 보실 수 있습니다. 해당 네트워크에서 docker0은 172.17.0.1로 설정이 되있고 veth0 (172.17.0.2)의 default gateway 역할을 합니다. 이때 docker가 컨테이너를 실행할 때 네트워크 namespace를 적절히 설정하여 컨테이너 안에서는 veth0만 보이게 됩니다. 그리고 컨테이너는 docker0와 eth0을 통해 바깥 세상과 통신을 하게 됩니다. 이제 두번째 컨테이너를 실행시켜 보겠습니다.
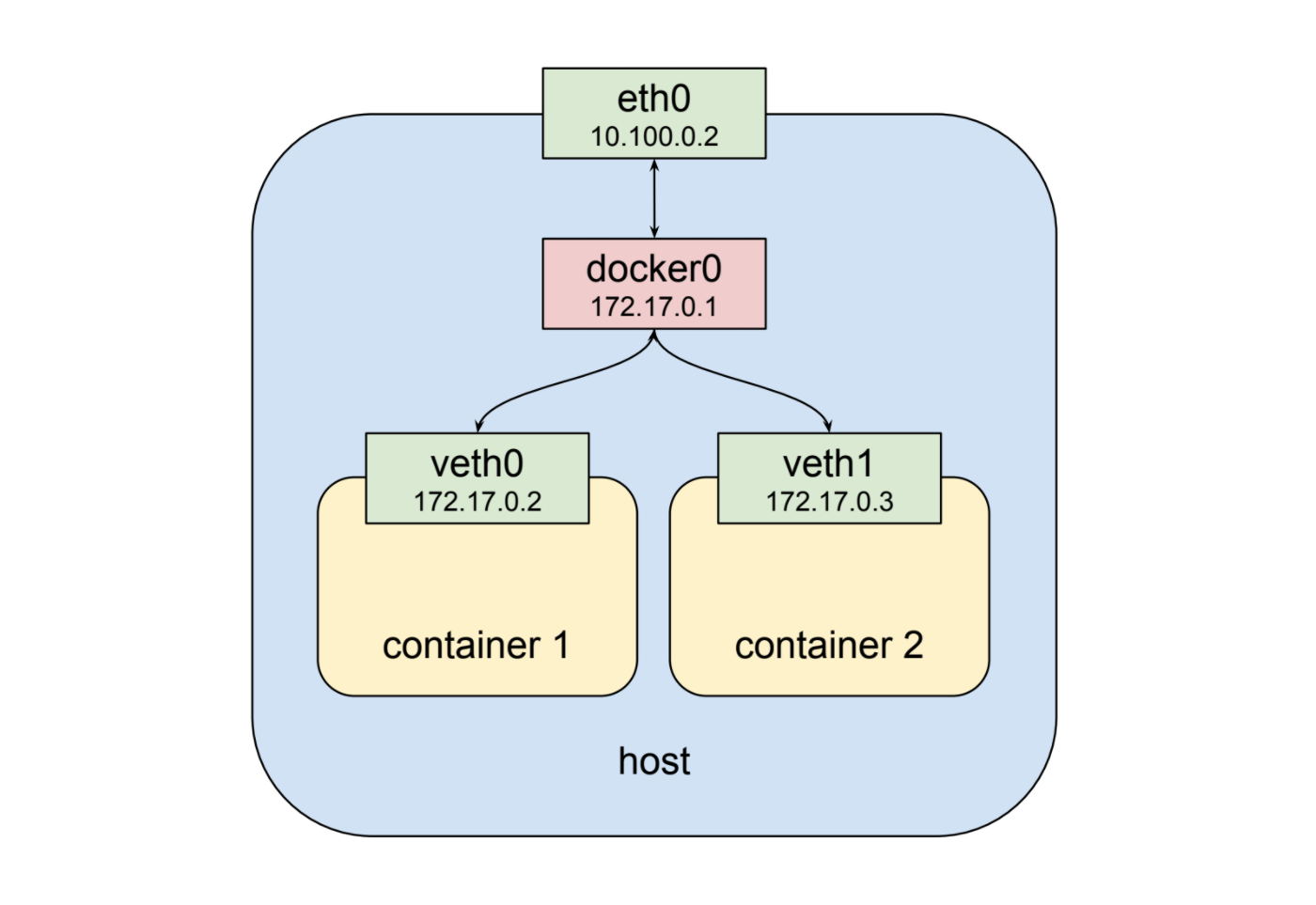
위에서 볼 수 있듯이 두번째 컨테이너는 veth1라는 새로운 가상 네트워크 인터페이스를 가집니다. 그리고 이것은 docker0 bridge에 연결이 됩니다. 새로 생선된 veth1에는 172.17.0.3으로 할당 되었고 이는 첫번째 컨테이너와 bridge와 같은 논리적 네트워크 대역입니다. 그렇기에 서로의 IP를 어떻게든 알 수만 있다면 (discover) bridge를 통해 서로 통신할 수 있습니다.
[* 2018-12-15: 저의 이전 포스트에서 lower level에서의 설명이 많이 잘못되었다는 것을 깨달았습니다. 컨테이너와 bridge간의 연결은 linked virtual ethernet device pair로 연결됩니다. 안에서는 컨테이너 network namespace와 바깥에서는 root network namespace를 가지고 말이죠. 더 좋은 overview는 ‘Kristen Jacobs’ “Container Networking From Scratch“를 참고하시기 바랍니다.]
여기까지도 좋습니다만 이것만으로는 Pod의 네트워크 스택을 공유해 주진 않습니다. 다행히 namespace는 매우 유연한 구조로 되어있습니다. 도커에서는 컨테이너를 실행할 때 새로운 virtual network interface를 생성하는 대신 기존에 생성된 interface를 이용할 수 있습니다. 이런 경우 그림으로 그리면 아래와 같이 됩니다.
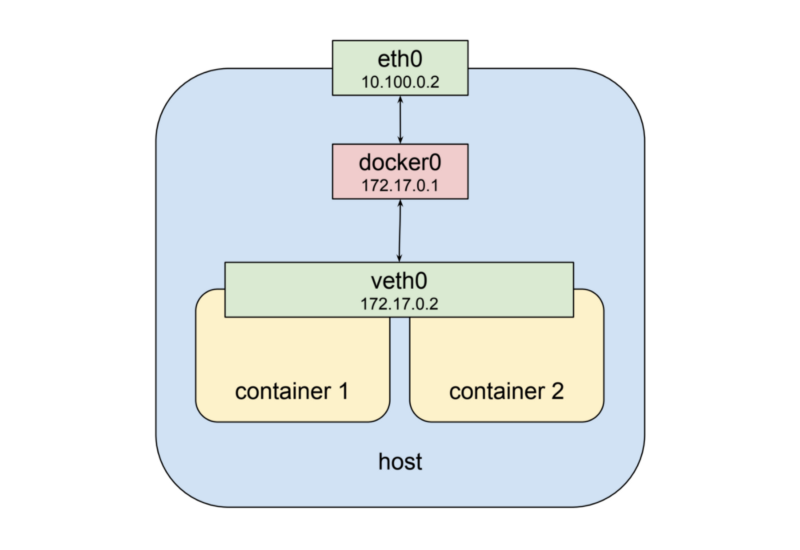
보시면 이제 두번째 컨테이너에서 새로운 veth1을 가지는게 아니라 veth0를 같이 사용하게 됩니다. 이것은 몇가지를 얘기해 줍니다.
- 두 컨테이너 모두 바깥에서 172.17.0.2로 접근을 할 수 있습니다. 그리고 안에서는 localhost를 통해서 port로 통신할 수 있습니다. 이것은 다시 말해 같은 포트를 동시에 열수 없다는 것을 얘기합니다. 이것은 제약사항이기도 하지만 여타 다른 mutiple process와 동일한 제약입니다. 이런 방법을 통해 두개의 process가 고립된 환경에서 서로의 결합을 가지지 않으면서도 같은 네트워크 환경을 공유할 수 있게 합니다.
쿠버네티스에서는 이러한 것을 특별한 컨테이너를 통해 구현합니다. 이 특별한 컨테이너는 각 Pod마다 존재하며 다른 컨테이너에게 network interface를 제공하는 역할만을 담당합니다. 만약 쿠버네티스 Pod가 실행되는 worker node에 들어가서 docker ps라고 검색을 하면 적어도 한개 이상의 pause라는 명령으로 실행된 컨테이너를 볼수 있습니다. pause 명령을 가진 컨테이너는 쿠버네티스가 SIGTERM 명령을 내리기 전까지 아무것도 하지 않고 sleep 상태로 존재합니다. 하는 일이 거의 없지만 이 pause 컨테이너가 서로 다른 컨테이너끼리, 바깥 세상과의 통신을 담다하는 Pod의 핵심이라고 볼 수 있습니다. 그래서 마지막 구조는 아래와 같게 생겼습니다.
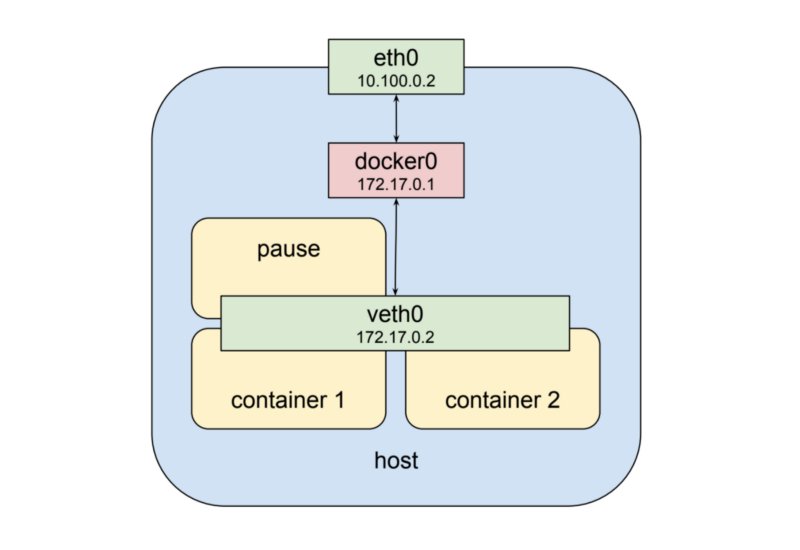
Pod 네트워크
지금까지 꽤 멋집니다. 하지만 한개 Pod 내에서 여러개의 컨테이너들이 서로 대화할 수 있다고 해서 시스템을 만들진 못합니다. 이러한 이유로 다음 포스트에서 얘기할 service는 쿠버네티스의 핵심 디자인 철학이며 서로 다른 Pod가 동일한 서버에 있든, 다른 서버에 위치하든 상관 없이 통신할 수 있게 해줍니다. 이것을 설명하기 위해 먼저 클러스터 레벨의 노드를 준비해야 합니다. 이번 섹션은 사람들이 별로 좋아하지 않는 네트워크 라우팅, 라우트에 대한 얘기를 조금 해볼까 합니다. 조금 더 명확하고 간단한 IP 라우팅 개념을 보고 싶다면 위키피디아를 참고해 보시기 바랍니다.
쿠버네티스 클러스터는 한개 이상의 노드를 가지고 있습니다. 노드란 물리적이든 가상이든 컨테이너 런타임을 탑재하고 있고 쿠버네티스 컴포넌트들이 들어 있는 host 시스템을 말합니다. 그리고 쿠버네티스 컴포넌트들이 다른 노드와 통신할 수 있게 만듭니다. 간단한 두개의 노드를 갖는 클러스터는 다음과 같은 모양일 것입니다.
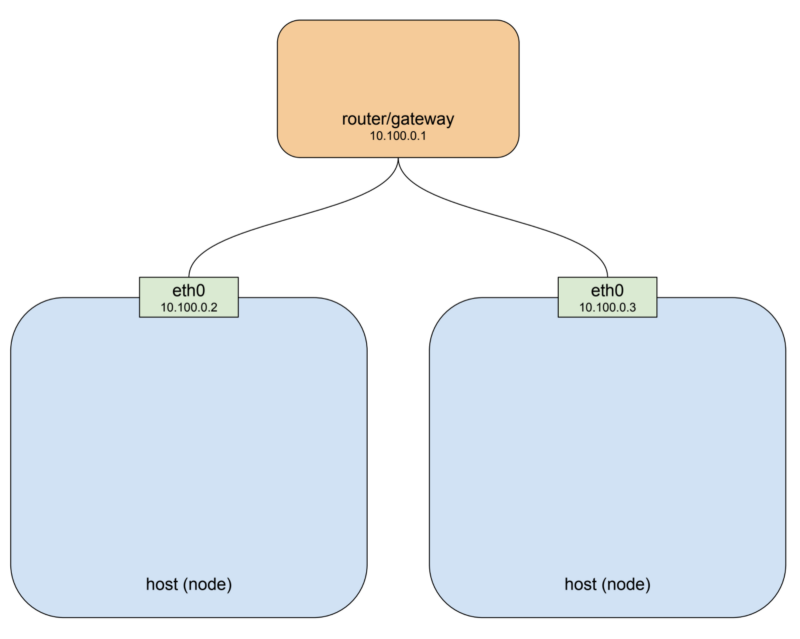
만약 당신이 GCP나 AWS 클라우드 플랫폼을 사용한다면 위의 그림은 기본 네트워크 구조와 꽤나 비슷한 것을 알 수 있습니다. 여기 예시에서는 private network 대역을 10.100.0.0/24로 설정하였고 라우터를 10.100.0.1, 나머지 두개 노드를 각각 10.100.0.2와 10.100.0.3으로 설정하였습니다. 이러한 설정으로 본다면 각 노드들은 다른 노드를 eth0를 통하여 통신할 수 있습니다. 여기까지 좋습니다. 하지만 앞서 보았다시피 Pod들은 해당 private network 대역과 맞지 않습니다. Pod들은 bridge를 통해 전혀 다른 네트워크 대역을 가지고 있고 그것들은 가상으로 생성이 되어있으며 특정 노드에만 존재합니다. 이것을 조금 더 명확하게 설명하기 위해 위의 그림에서 Pod를 추가해 봅시다.
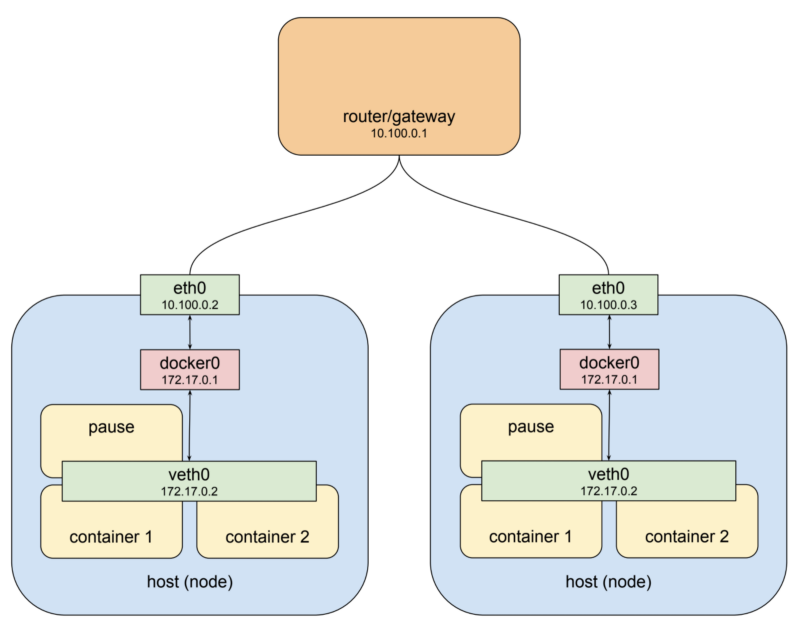
먼저 default gateway가 10.100.0.1로 설정 되어있습니다. 왼쪽의 host는 인터페이스 eth0가 10.100.0.2로 설정되어 있고 그것은 docker0과 연결되어 있고 해당 주소는 172.17.0.1로 되어 있고 그것과 맞물린 veth0은 172.17.0.2로 설정되어 있습니다. veth0 인터페이스는 pause 컨테이너를 통해 생성되었고 나머지 컨테이너들이 전부 네트워크 스택을 공유하고 있습니다. host내에 들어 있는 지역 라우팅 rule 설정으로 인해 eth0 인터페이스에 172.17.0.2의 목적지를 가진 패킷은 bridge로 전달되고 그것은 veth0으로 다시 전달 됩니다. 여기까지 좋습니다. 이제 우리가 172.17.0.2 Pod가 이 host에 있다는 것을 알면 10.100.0.2의 타겟을 해당 주소로 라우터 rule을 설정하면 됩니다. 그렇게 되면 최종적으로 veth0으로 가게 되겠죠. 멋지네요. 이제 다른 host를 살펴보죠.
오른쪽의 host에도 eth0이 있고 10.100.0.3으로 설정되어 있습니다. 또한 같은 default gateway를 사용합니다. 그리고 똑같이 docker0 bridge가 172.17.0.1로 eth0과 연결되어 있습니다. 음.. 문제가 조금 되겠네요. 어쩌면 왼쪽 host에 있는 bridge와는 다른 주소로 설정될 수도 있습니다. 여기서는 제가 일부러 최악의 상황을 만들었습니다. 하지만 이러한 일은 꽤나 쉽게 일어날 수 있습니다. 만약 당신이 도커를 그냥 설치하고 바로 사용한다면 이렇게 세팅될 확률이 높습니다. 어찌되었든 이러한 문제는 근본적인 문제를 보여줍니다. 바로 한쪽 노드에서 다른 노드의 bridge에 어떠한 내부 주소를 할당 받았는지 모르는 문제가 있습니다. 왜냐하면 우리가 그곳으로 패킷을 보내야할지 말지를 알아야 하기 때문입니다. 새로운 구조가 필요한 것이 명확해 보입니다.
쿠버네티스에서는 2가지 방법으로 이 문제를 해결합니다. 가장 먼저 쿠버네티스는 각 노드 bridge의 IP가 서로 겹치지 않게 전체를 아우르는 주소 대역을 할당합니다. 그리고 난 뒤 각 bridge에 실제 주소를 해당 주소 대역 안에서 할당합니다.(역자주: 이와 같은 상황을 피하려면 각 호스트별로 subnet을 나눕니다. 그렇게 되면 각 호스트마다 클러스터 전체에서 유일한 IP가 할당될 수 있습니다. 예를 들어 10.100.0.2 호스트는 172.17.1.0/24 주소대역만을 사용하도록 하고 10.100.0.3 호스트에서는 172.17.2.0/24 주소대역만을 사용하도록 하는 경우, 서로 IP가 겹치는 상황이 발생하지 않게 됩니다.)
두번째로 10.100.0.1에 있는 gateway에 어떤 패킷이 어떤 bridge로 가야하는지에 대해 라우팅 테이블을 설정합니다. 어떤 노드의 eth0를 통해 해당 bridge를 접근할 수 있는가 말이죠. 이렇게 가상 네트워크 인터페이스와 bridge와 라우팅 rule의 조합을 일컬어 overlay network라고 합니다. 쿠버네티스 네트워크에 대해 얘기할때 저는 주로 이것을 Pod 네트워크라고 부릅니다. 왜냐하면 overlay network를 이용하여 pod들이 서로 정보를 주고 받기 때문입니다. 아래에 그림이 쿠버네티스 네트워크의 모습입니다.
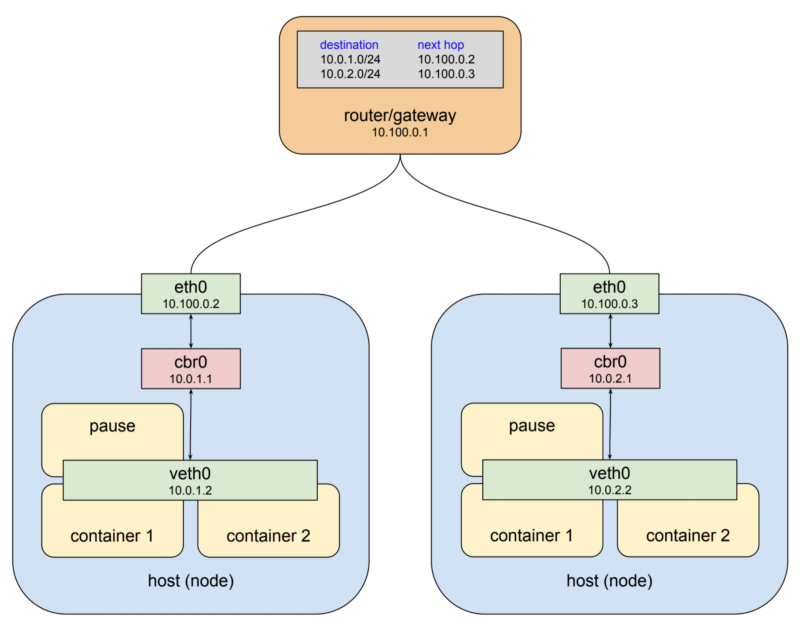
한가지 짚고 넘어가고 싶은 것은, bridge의 이름을 docker0에서 cbr0으로 바꿨습니다. 쿠버네티스는 도커 표준 bridge device를 사용하지 않고 자체 bridge를 사용합니다. “cbr”이라는 것 자체가 custom bridge의 약자입니다. 내부적으로 어떤 부분을 수정했는지 전부는 모르지만 이것이 쿠버네티스가 동작하는 방법과 기본 도커 설치했을 때의 중요한 차이라고 볼 수 있습니다. 또 한가지 말씀드리자면 예시로 사용된 bridge의 주소 대역인 10.0.0.0/14는 실제 Google Cloud의 staging 클러스터에서 참고한 것으로 실사용 예제라고 보시면 됩니다. 다른 클러스터는 완전히 다른 주소 대역으로 할당 받을 수도 있습니다. 불행히도 아직까지는 kubectl 툴을 이용해서 컨트롤할 수 있는 방법이 없습니다. 하지만 GCP에서는 gcloud container clusters describe <cluster> 명령어를 이용하여 clusterIpv4Cidr 정보를 볼 수 있습니다.
일반적으로는 이러한 네트워크가 어떻게 동작하는지 생각할 필요는 없습니다. 보통 하나의 Pod가 다른 Pod와 통신할 때, service라는 추상화된 layer를 통하여서 통신합니다. 일종의 software 정의 proxy (software-defined proxy) 역할을 합니다. 이것은 다음 포스트에서 설명 드리겠습니다. 하지만 간혹 Pod의 네트워크 주소로 어떤 문제를 디버깅할때 필요할 것이고 그럴 경우 명시적으로 해당 주소로 네트워크를 라우팅해야 합니다. 예를 들어, 쿠버네티스 Pod를 떠나는 트래픽 중 10.0.0.0/8 대역은 기본적으로 NAT 변환 되지 않습니다. 그렇기 때문에 해당 대역대로 다른 내부 네트워크와 통신하려 한다면 다시 해당 Pod로 라우팅되게 라우트 rule을 설정해야 할 것입니다. 부디 이 블로그 글이 도움 되길 바랍니다.