![[번역]쿠버네티스 패킷의 삶 - #3](/assets/images/packet-life/landing03.png)
[번역]쿠버네티스 패킷의 삶 - #3
26 min read
쿠버네티스 패킷의 삶 #3에서는 Service 네트워크가 동작하는 방법에 대해 심층적으로 알아 봅니다.
쿠버네티스 패킷의 삶 시리즈
- 컨테이너 네트워킹과 CNI: 리눅스 네트워크 namespace와 CNI 기초
- Calico CNI: CNI 구현체 중 하나인, Calico CNI 네트워킹
- Service 네트워킹: Service, 클러스터 내/외부 네트워킹 설명(원글)
- Ingress: Ingress Controller에 대한 설명
쿠버네티스 패킷의 삶 3번째 시리즈입니다. 이번 글에서는 kube-proxy가 어떻게 iptables를 이용하여 트래픽을 전달하는지 낱낱히 살펴 보는 시간을 가져 보겠습니다. 쿠버네티스 네트워킹을 이해하기 위해서 kube-proxy와 iptables의 역할을 잘 아는 것이 중요합니다.
참고: 트래픽을 컨트롤하는 플러그인/툴은 많이 있습니다만 이번 글에서는 주로 kube-proxy + iptables 조합에 대해서 설명 드립니다.
쿠버네티스에서 제공하는 다양한 커뮤니케이션 모델에 대해서 먼저 살펴 보겠습니다. 혹시 Service, ClusterIP 그리고 NodePort에 대한 내용을 이미 알고 있다면 바로 kube-proxy/iptables 섹션으로 넘어가길 바랍니다.
Pod - Pod 통신
kube-proxy는 Pod to Pod 통신에는 관여하지 않습니다. CNI와 노드에서 Pod 통신간 필요한 라우팅 정보를 설정합니다. 모든 컨테이너는 NAT 없이 다른 컨테이너와 통신할 수 있습니다. 또한 모든 노드는 NAT 없이 모든 컨테이너와 통신할 수 있습니다.(반대로도 성립합니다.)
참고: Pod의 IP는 고정적이지 않습니다. (고정된 IP를 할당 받는 방법은 있지만 기본적으로는 고정 IP를 보장 받지 않습니다.) Pod 재시작 시, CNI는 새로운 IP를 해당 Pod에 할당합니다. 왜냐하면 CNI가 따로 IP와 Pod 간에 매핑 정보를 관리하지 않기 때문입니다. 또한 이미 알고 있듯이 Deployment 리소스를 사용하는 경우 Pod 이름 조차도 고정적이지 않습니다.
(역자주: ipam 플러그인에 따라서 다릅니다.)
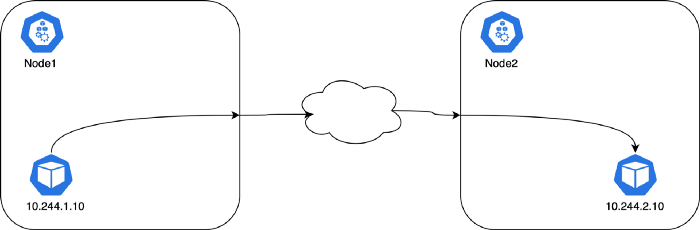
실무에서는 Deployment를 사용할 때, 앞단에 로드밸런서를 두고 어플리케이션을 노출 시킵니다. 그리고 한개 이상의 Pod를 사용하죠. 쿠버네티스에서 이 로드밸런서를 Service라고 부릅니다.
Pod - 외부 통신
Pod로부터 외부로 나가는 트래픽에 쿠버네티스는 SNAT를 사용합니다. 바로 Pod의 내부 IP:PORT를 호스트 서버의 IP:PORT로 치환하는 일을 수행하죠. 요청에 대해 응답이 오는 경우 그것을 다시 Pod의 IP:PORT로 바꿔서 원래의 Pod로 트래픽을 전달해 줍니다. Pod 입장에서는 이 모든 프로세스가 수행된지 전혀 모릅니다.
Pod- Service 통신
ClusterIP
쿠버네티스에는 “Service”라는 개념이 있습니다. 이것은 간단히 말해 Pod 앞단에 위치하는 L4 로드밸런서입니다. 몇 가지 종류의 Service가 있습니다. 그 중 가장 기본적인 종류로 ClusterIP가 있습니다. 이 서비스는 클러스터 내부에서 라우팅 가능한 고유의 VIP(가상 IP)를 가집니다.
Pod IP만으로는 특정 어플리케이션에 트래픽을 보내는 것은 쉽지 않습니다. 왜냐하면 쿠버네티스 환경에서는 Pod가 쉽게 이동하고, 재시작되고, 업그레이드되고 확장되고 사라지기 때문에 굉장히 동적입니다. 또한 replicas의 개수를 늘리게 되면 한개 이상의 Pod가 생성됨으로 이들간에 트래픽을 분산할 수 있는 방법이 있어야 합니다.
그래서 쿠버네티스에서는 Service라는 객체를 두어 이 문제를 해결했습니다. Service는 단일 가상IP(VIP)로 오는 트래픽을 특정 Pod들로 전달해 주는 끝점(Endpoint)입니다. 또한 Service의 이름은 DNS Name로써의 역할도 수행합니다. 이를 통해 쉽게 다른 서비스들의 Endpoint를 찾을 수 있습니다. (역자주: VIP를 몰라도 서비스의 이름만 알면 해당 이름으로 요청을 보낼 수 있기 때문입니다.)
VIP를 Pod IP로 매핑해 주는 작업은 각 노드의 kube-proxy에 의해 수행됩니다. kube-proxy는 iptables나 IPVS를 이용하여 트래픽이 호스트 노드를 떠나기 전에 VIP를 Pod IP로 매핑 시키는 작업을 수행합니다. 각각의 커넥션들은 상태 트래킹이 됩니다. 그렇기 때문에 요청된 패킷들이 응답될 때 적절하게 원래대로 변환되어 돌아옵니다. 또한 IPVS 혹은 iptables를 이용하여 VIP로 들어오는 트래픽을 여러 Pod IP로 분산합니다. 참고로 다양한 부하분산 알고리즘을 사용하기에는 IPVS가 더 좋습니다. 가상IP (VIP)는 살제로 시스템 네트워크 인터페이스에 존재하지 않습니다. 단지 iptable 안에서만 존재합니다.
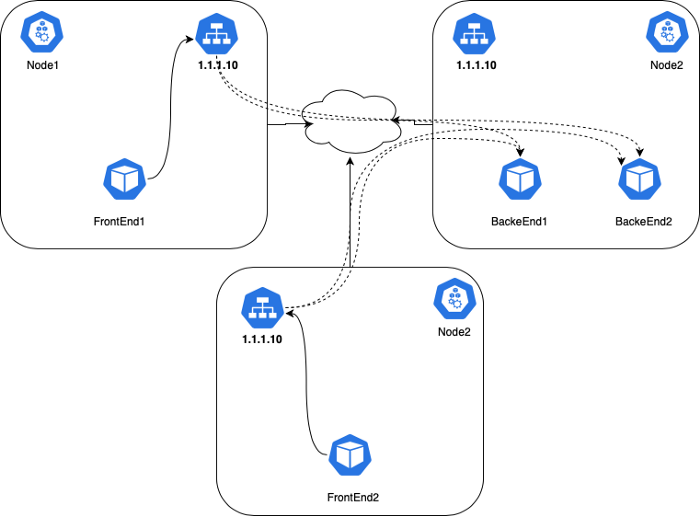
쿠버네티스 공식 페이지의
Service정의:Service는Pod를 네트워크 서비스로 어플리케이션을 노출 시키기 위한 추상화된 방법을 제공합니다. 쿠버네티스에서는 서비스 탐색(역자주: 서비스의 끝점을 알아내기 위한 방법)을 위해 특별한 방법을 사용하지 않아도 됩니다. 단지 서비스의 이름만 알고 있으면 됩니다. 쿠버네티스는 각Pod마다 고유의 IP주소를 제공하고 그곳들을 묶어서 단일한 DNS 이름을 부여하여 부하를 분산 시킵니다.
- FrontEnd Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
labels:
app: webapp
spec:
replicas: 2
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
- Backend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth
labels:
app: auth
spec:
replicas: 2
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
- Service:
apiVersion: v1
kind: Service
metadata:
name: frontend
labels:
app: frontend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: webapp
---
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
app: backend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: auth
위와 같이 쿠버네티스 manifest를 생성하면 FrontEnd Pod들이 ClusterIP나 DNS 이름으로 BackEnd Pod들을 접근할 수 있게 됩니다. 클러스터 내에 존재하는 DNS 서버가 (예를 들어, CoreDNS) 쿠버네티스 API를 통해 Service를 관찰하고 있다가 새로운 Service가 생기게 되면 그에 해당하는 DNS record를 생성합니다. 클러스터 전체에 DNS가 활성화되어 있다면 모든 Pod들이 자동으로 Service를 이름으로 DNS 질의를 할 수 있습니다.
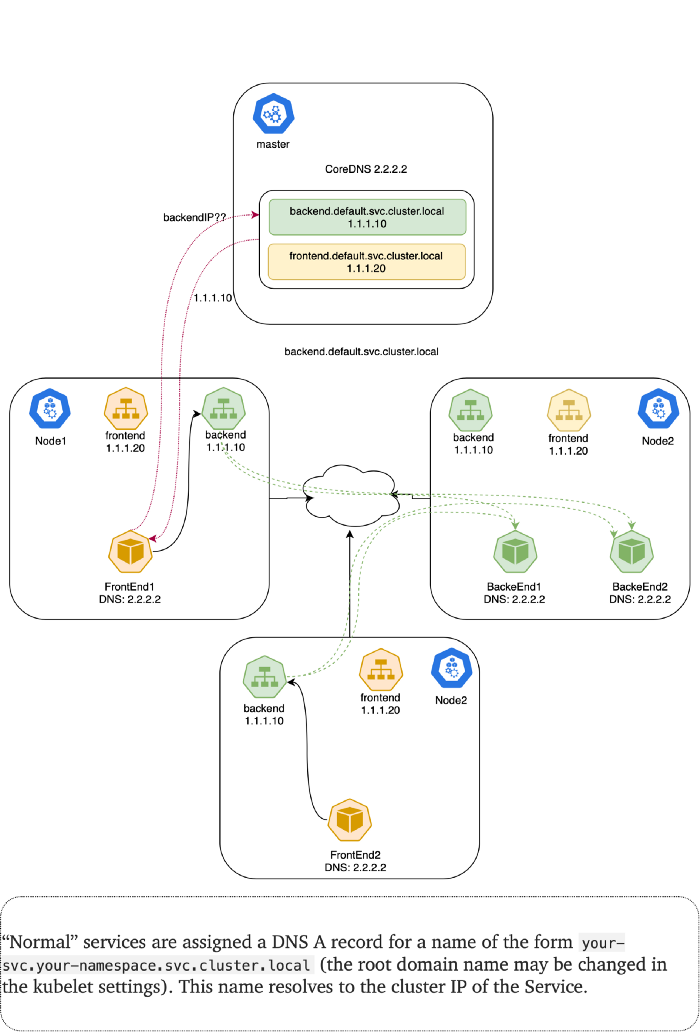
NodePort (외부 - Pod 통신)
쿠버네티스 내부적으로 DNS를 통해 서로 통신할 수 있는 메커니즘을 살펴 보았습니다. 하지만 클러스터 외부에서는 클러스터 내부에 존재하는 Service로 접근하지는 못합니다. 왜냐하면 Service가 제공하는 VIP는 가상 IP이고 클러스터 내부에 존재하는 IP이기 때문입니다.
외부 서버에서 frontEnd Pod IP로 접근을 시도해 봅시다.
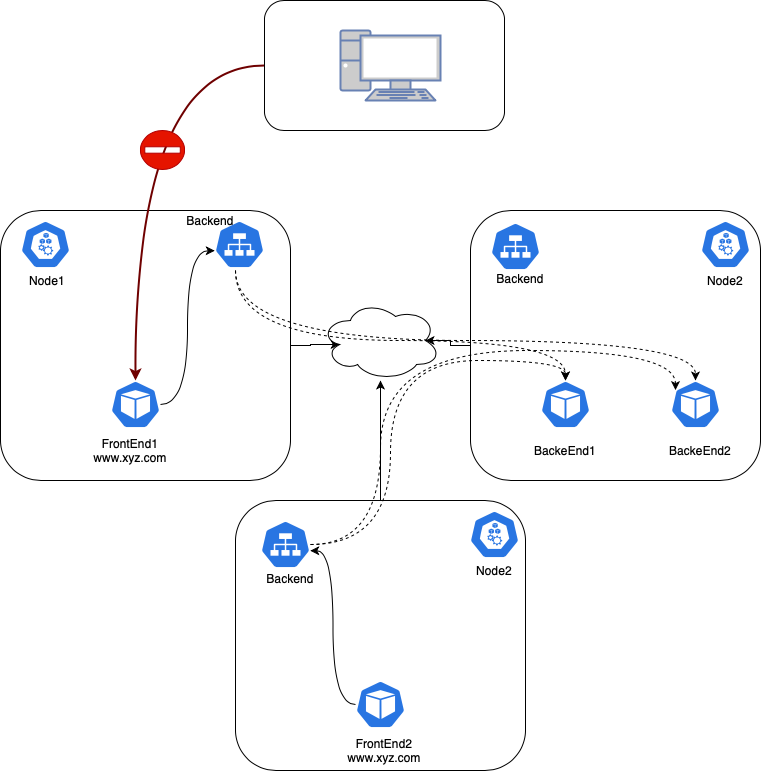
보시다시피, 클러스터 외부에 있는 클라이언트에서는 내부 IP주소인 FrontEnd 주소로 접근하지 못합니다.
그럼 FrontEnd를 외부로 노출 시키기 위해 NodePort 타입의 서비스를 생성해 봅시다. type 필드를 NodePort라고 수정하면 쿠버네티스는 --service-node-port-range 옵션에 의해 정해진 포트 대역대 안에서(기본적인 대역대: 30000-32767) 특정 포트를 하나 할당합니다. 그러면 모든 노드에서 해당 포트에 대해 Service로 트래픽을 라우팅합니다. Service는 해당 포트의 이름을 nodePort라 부르며 .spec.ports[*].nodePort 필드에 정의됩니다.
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
selector:
app: webapp
ports:
- port: 80
targetPort: 80
# nodePort를 생략하면 쿠버네티스가 대신 포트를 하나 할당해 줍니다.
nodePort: 31380
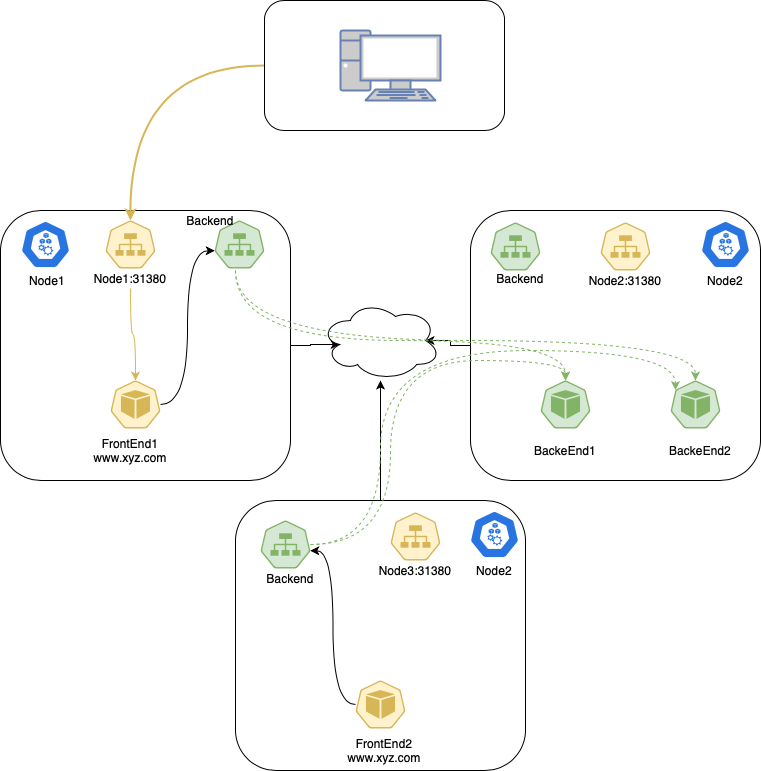
이제 FrontEnd 서비스를 <아무 NodeIP>:<nodePort>로 접근할 수 있게 되었습니다.(역자주: <아무 NodeIP>란 쿠버네티스 클러스터를 구성하고 있는 노드(마스터, 워커 노드 둘다) 중 아무 호스트 IP를 의미합니다.) 특정 포트를 지정하고 싶다면 nodePort 필드의 값을 직접 지정하면 됩니다. 쿠버네티스 마스터가 해당 포트를 할당해주거나 실패하면 에러 리포트를 줄 것입니다. 이 뜻은 Service간 node 포트 충돌을 유념해야 한다는 것입니다. 또한 NodePort에 사용되는 허용 가능한 포트 대역 안에서 포트 번호를 선택해야 합니다.(--service-node-port-range)
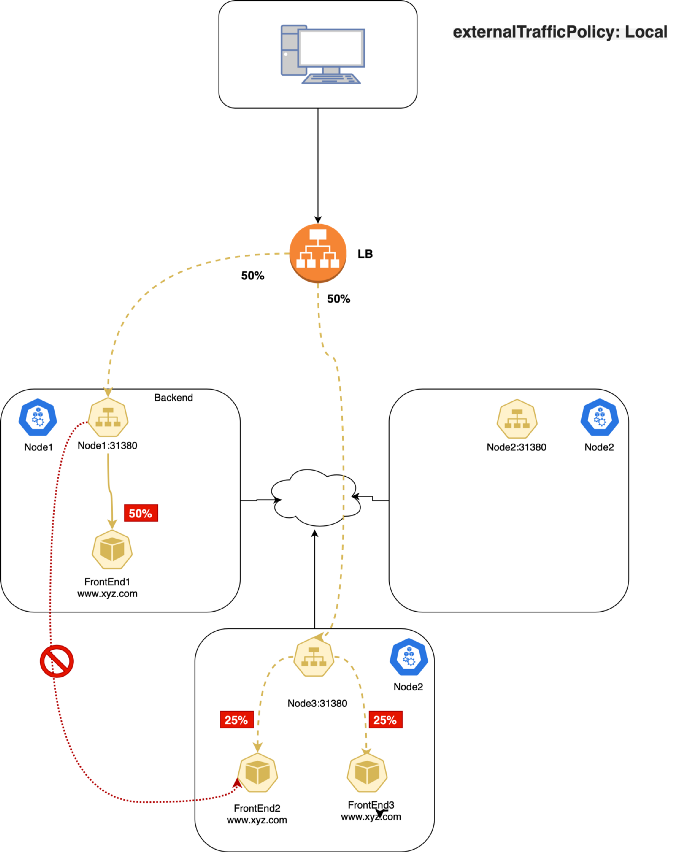
외부 트래픽 정책(ExternalTrafficPolicy)
외부 트래픽 정책(ExternalTrafficPolicy)이란 외부 트래픽에 대한 응답으로 Service가 노드 안(Local)에서만 응답할지 Cluster 전체(Cluster)로 나아가서 응답할지 결정하는 옵션입니다. “Local” 타입은 client 소스IP를 유지하고 네트워크 hop이 길어지지 않게 막아줍니다. 하지만 잠재적으로 트래픽 분산에 대한 불균형을 가져 올 수 있습니다. “Cluster” 타입은 client의 소스IP를 가리고 네트워크 hop을 길게 만들지만 전체적으로 부하가 분산되도록 해줍니다.
Traffic Policy: Cluster
이 옵션은 Service의 기본 옵션입니다. 이 옵션은 트래픽을 클러스터의 모든 노드 전반에 걸쳐 다 보내고 싶어한다는 것을 의미합니다. 그렇기에 부하가 고르게 분산됩니다.
이 옵션의 한가지 단점은 불필요한 네트워크 hop을 증가시킨다는 것에 있습니다. 예를 들어, NodePort를 통해 외부 트래픽을 받게 될 때, 운 없게도 NodePort 서비스의 트래픽을 전달 받는 Pod가 없는 노드로 요청이 갈 수 있습니다. 이런 경우에는 해당 노드에는 전달 받을 Pod가 없기 때문에 추가적인 hop을 걸쳐 다른 노드에 위치한 Pod로 트래픽이 전달되게 됩니다.
Cluster 타입에서의 패킷 흐름은 다음과 같습니다:
- 사용자가
node2_IP:31380으로 패킷을 보냅니다. node2는 출발지 IP주소를 자신의 노드 IP로 변경합니다.(SNAT)node2는 목적지 IP주소를 전달 받을PodIP로 변경합니다.- (
node2에 전달 받을Pod이 없을 경우)node1이나node3으로 hop을 건너게 됩니다. - 패킷을 전달 받은
Pod는node2로 다시 패킷을 응답합니다. node2를 통해서 사용자에게 패킷이 응답됩니다.
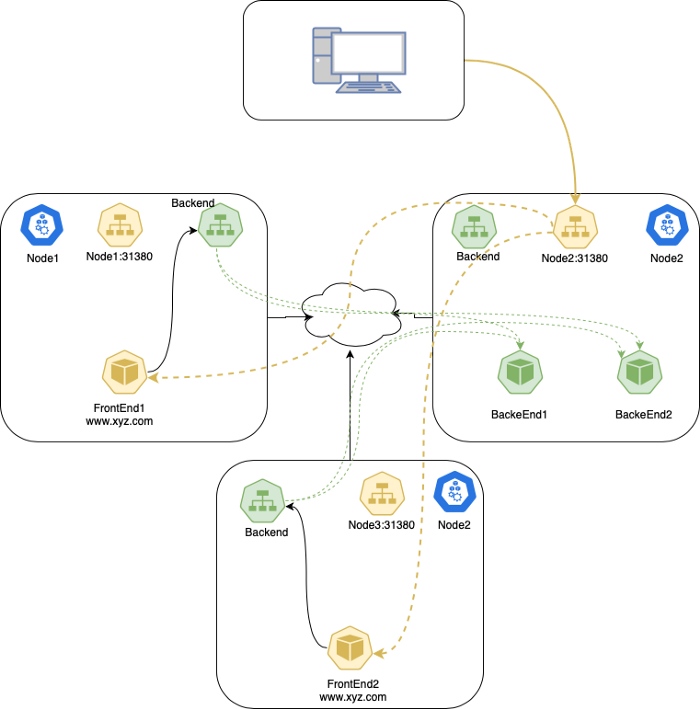
Traffic Policy: Local
이 옵션에서는 kube-proxy가 전달 받을 Pod가 있는 노드에만 NodePort를 엽니다. (역자주: 예를 들어 node1, node2에만 전달 받을 Pod가 있는 경우, 해당 노드에만 NodePort를 엽니다. 반대로 앞에서 본 Cluster 모드에서는 모든 노드에 NodePort가 열립니다.)
externalTrafficPolicy를 Local는 Service 타입이 NodePort이거나 LoadBalancer 일 때만 동작합니다. 외부 트래픽을 받을 때만 의미 있기 때문입니다.
이 옵션을 사용하게 되면 kube-proxy는 Pod가 있는 노드에만 포트를 열고 그 외에는 트래픽을 전달하지 않고 drop 시킵니다. 이로써, client의 소스IP가 보존될 수 있습니다.(역자주: 다른 노드로 네트워크 hop을 건너지 않기 때문에 클라이언트 IP가 보존됩니다.)
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
externalTrafficPolicy: Local # <-- 기본적으로는 Cluster이지만 Local로 변경 가능합니다.
selector:
app: webapp
ports:
- port: 80
targetPort: 80
nodePort: 31380
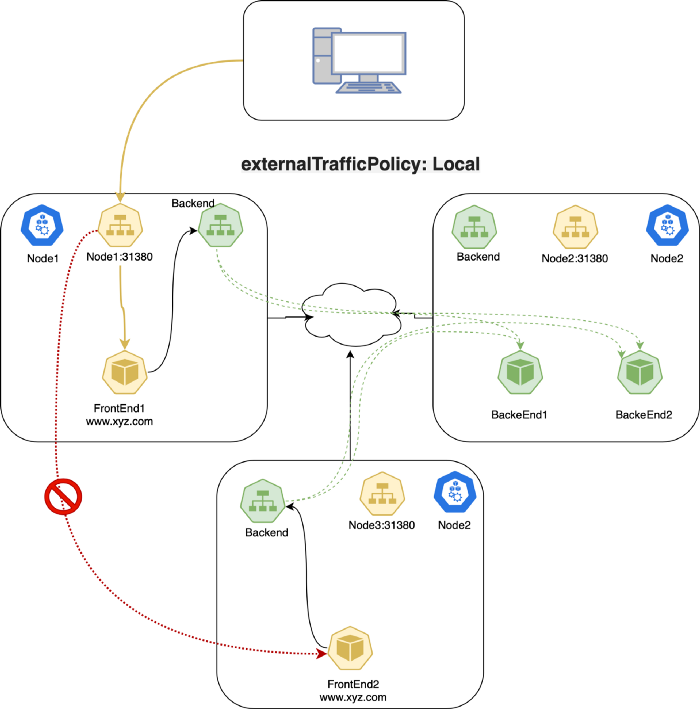
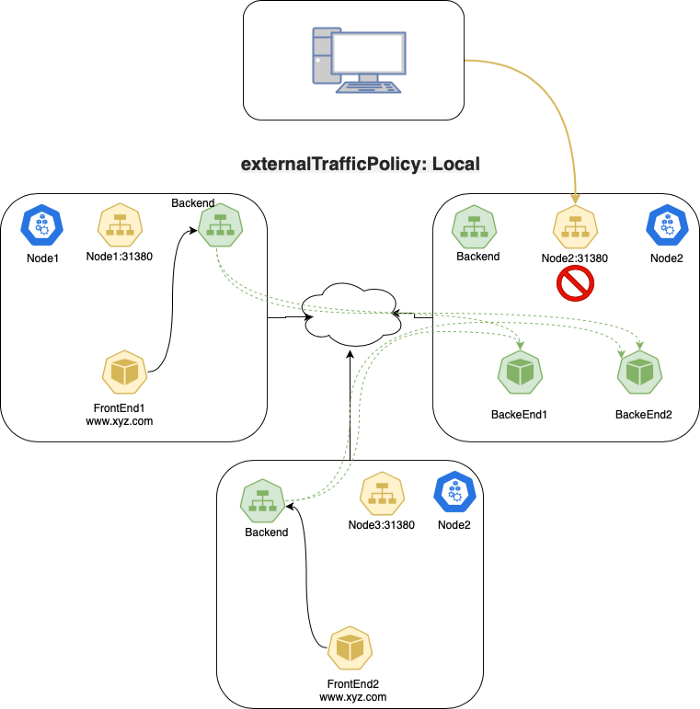
Local 타입에서의 패킷 흐름은 다음과 같습니다:
- 사용자가
Podendpoint가 존재하는node1서버의31380포트로 패킷을 전송합니다. node1서버는 해당 트래픽을 클라이언트의 소스 IP를 유지한채Pod로 전달합니다.node1은 해당 트래픽을 다른 곳으로 라우팅하지 않습니다. (Local로 설정했기 때문에)- 사용자가
node2:31380(Pod endpoint가 없는 노드)로 보내게 되는 경우에는 - 해당 패킷이 버려집니다.(dropped)
Local traffic policy와 LoadBalancer type과의 조합
만약 GCP나 AWS와 같이 클라우드 서비스 위에서 쿠버네티스를 운영하는 경우, externalTrafficPolicy값을 Local로 설정하면 클라우드에서 제공하는 로드밸런서의 health check가 실패하게 되어 명시적으로 해당 노드로 트래픽이 전달되지 않게 됩니다.(역자주: 전달 받을 Pod가 없는 노드인 경우 패킷이 drop됨으로 해당 노드의 health check가 실패하여 클라우드 로드밸런서가 해당 노드로 패킷을 전달하지 않게 됩니다.) 그렇기 때문에 서비스적으로 트래픽 drop 현상이 발생하지 않게 됩니다.(그전에 로드밸런서에서 트래픽을 해당 노드로 보내지 않기 때문에) 이런 구조는 외부 트래픽이 많은 어플리케이션에서 불필요한 네트워크 hop을 없애서 지연시간(latency)를 줄여줍니다. 또한 실제 사용자의 소스 IP를 보존해주고 노드에서 SNAT 수행을 필요하지 않아도 되게 만들어 줍니다.(네트워크 hop을 거치지 않기 때문에) 하지만 외부 트래픽 정책을 Local로 설정할 경우, 가장 큰 단점은, 앞서 말씀 드린 것처럼 트래픽을 고르게 분산하지 못한다는 점이 있습니다.
Kube-Proxy (iptable mode)
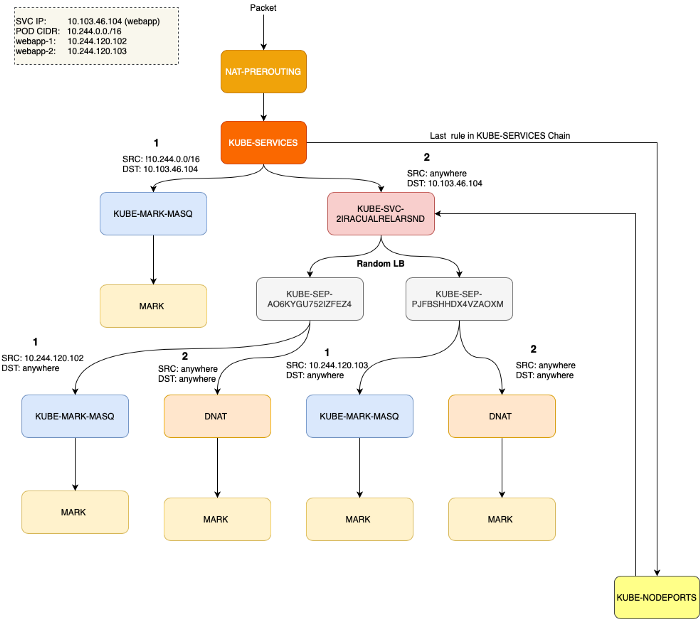
쿠버네티스에서 Service를 구현하는 컴포넌트는 바로 kube-proxy입니다. 모든 노드에서 실행되며 Pod와 Service간 통신에 필요한 각종 복잡한 필터링과 NAT를 수행합니다. 클러스터의 아무 노드에 들어가서 iptables-save라고 입력하면 쿠버네티스와 관련 컴포넌트들이 삽입한 여러 iptable 규칙들을 확인할 수 있습니다. 가장 중요한 chain으로 KUBE-SERVICES, KUBE-SVC-* 그리고 KUBE-SEP-*를 들 수 있습니다.
KUBE-SERVICES:Service패킷의 시작점입니다. 목적지 IP:Port를 확인하여 대응되는KUBE-SVC-*chain으로 전달합니다.KUBE-SVC-*: 해당 chain은 마치 로드밸런서처럼 동작하여KUBE-SEP-*chain으로 패킷을 전달합니다. 각각의KUBE-SVC-*은 동일한 개수의KUBE-SEP-*chain endpoint를 가지고 있습니다.KUBE-SEP-*: 이 chain은 Service Endpoint를 대표합니다.(Service EndPoint) DNAT를 수행합니다. 바로 Service의 IP:Port를 Pod의 IP:Port로 변환하는 역할을 수행합니다.
DNAT에는 conntrack이 state machine을 이용하여 connection의 상태를 유지합니다. 이 상태는 목적지 주소를 변환하고 응답할 때 다시 원래 주소로 되돌리기 위해서 필요합니다. iptables 또한 conntrack 상태를 이용하여 목적지 패킷을 결정합니다. 다음 4가지 conntrack 상태에 대해 살펴 봅시다:
NEW: conntrack은 해당 패킷에 대해 알고 있는 것이 전혀 없습니다. SYN 패킷이 전달 되었을 때의 상태입니다.ESTABLISHED: conntrack이 해당 패킷이 어느 connection에 속하는지 아는 상태입니다. handshake가 완료되었을 때의 상태입니다.RELATED: 패킷이 어느 connection에도 속하지 않지만 다른 connection과 연계되었을 때의 상태입니다.FTP와 같은 프로토콜에서 유용하게 사용할 수 있습니다.INVALID: 패킷에 어떤 이상이 있을 때의 상태입니다. conntrack이 이 패킷을 어떻게 처리해야 할지 모를 때 사용됩니다. 쿠버네티스에서는 이 상태를 매우 유용하게 사용합니다.
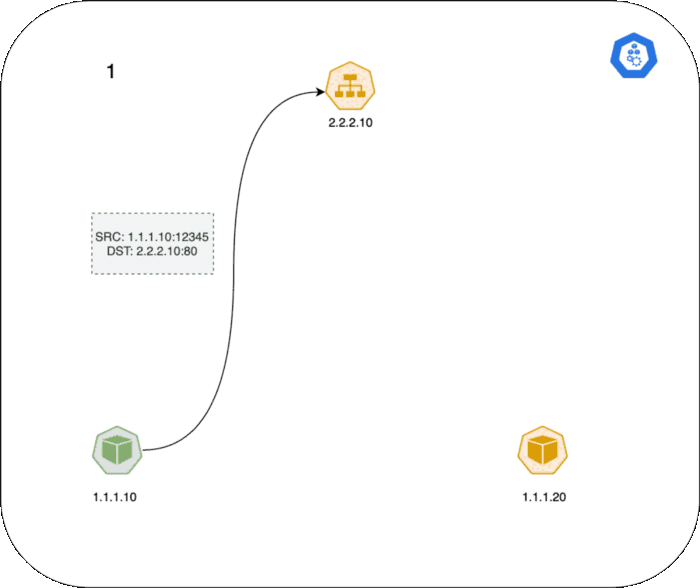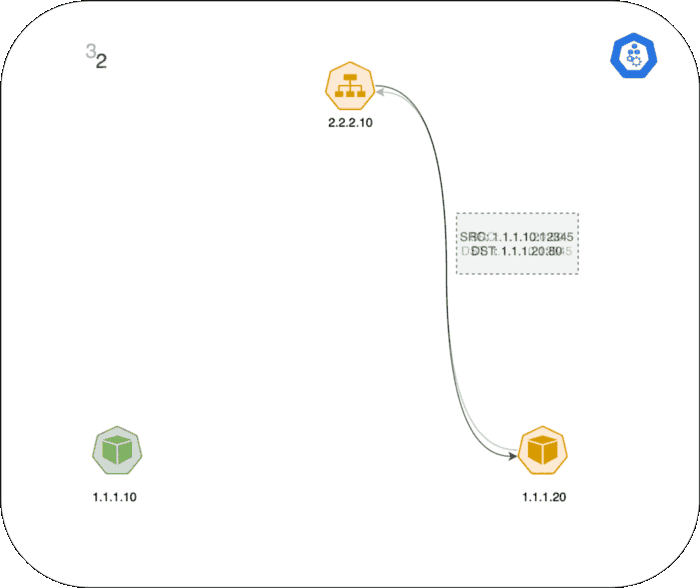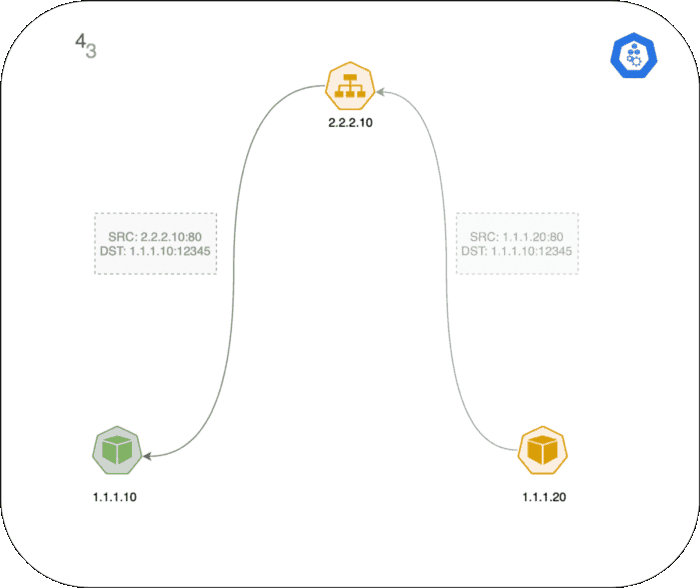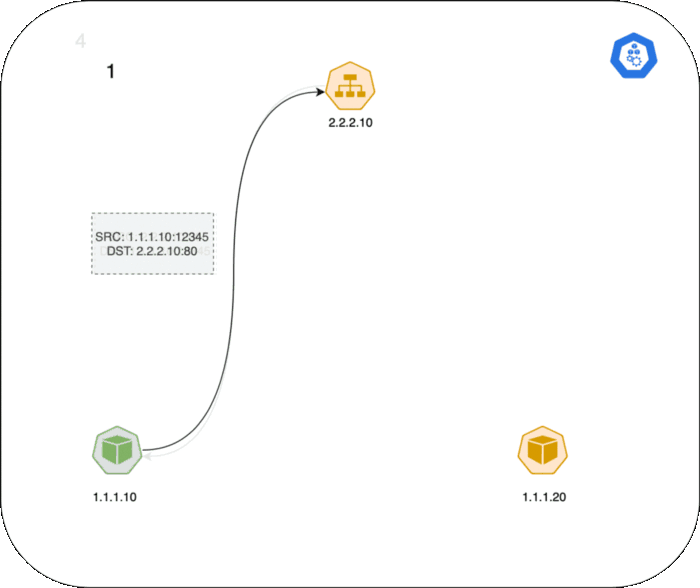
다음은 Pod와 Service간의 TCP connection이 어떻게 동작하는지 설명합니다.
- 왼쪽에 있는 Client Pod가
2.2.2.10:80IP를 가진 Service로 패킷을 보냅니다. - Client 노드에 있는 iptables 규칙에 따라 목적지 IP가 Pod IP로 변환됩니다.
1.1.1.20:80 - Server Pod는 패킷을 처리하여 목적지 주소
1.1.1.10(Client Pod IP)으로 응답합니다. - Client 노드로 패킷이 다시 전달되고
conntrack가 해당 패킷을 인식하고 source 주소를2.2.2.10:80으로 변환합니다. - Client Pod가 패킷을 응답 받게됩니다.
GIF 설명:
iptables
리눅스 운영체제에서는 netfilter를 이용하여 방화벽을 수행합니다. netfilter는 리눅스 커널 모듈로써, 어떤 패킷이 들어올 수 있고 나갈 수 있는지를 결정합니다. iptables는 바로 이 netfilter의 인터페이스 역할을 합니다. 그래서 보통 이 두개를 동일하게 생각하기도 합니다. 간단하게 생각해서 iptable을 프론트엔드, netfilter를 백엔드로 생각하면 좋습니다.
chains
iptables에는 chain이라는 것이 있는데 이것은 각각 다음과 같은 역할을 수행합니다.
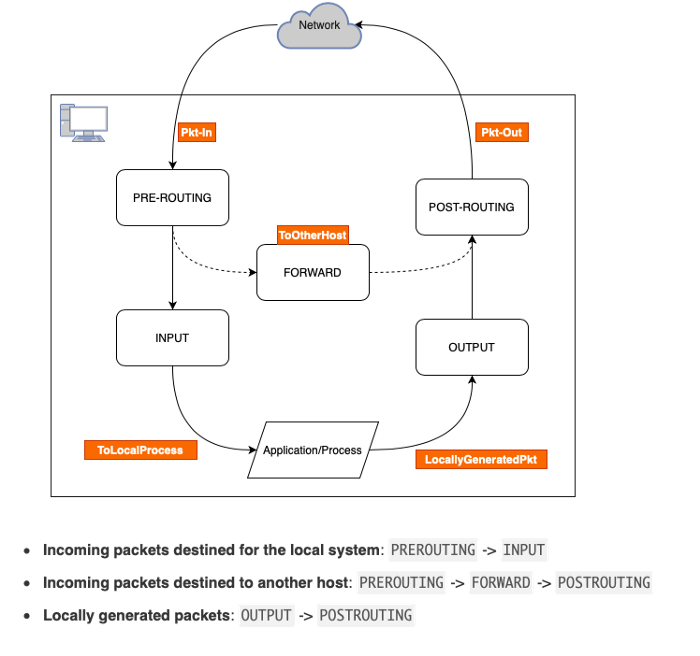
PREROUTING: 이 chain은 패킷이 네트워크 인터페이스에 도착하자마자 어떤 일을 수행할지를 정하는 chain입니다. 예를 들어NAT를 수행하는 경우 패킷을 수정하는 경우가 있고 패킷을 아예 버리거나(drop) 아무 일도 하지 않고 그 다음 chain으로 넘길 수도 있습니다.INPUT: 이 chain은 인터넷으로부터 오는 침입자를 막기 위해 사용하는 chain으로 굉장히 많이 사용합니다. 특정 포트를 열거나 막고 싶을 경우 바로 이 chain을 사용합니다.OUTPUT: 이 chain은 당신이 웹 브라우징을 하거나 그외 다양한 것들을 할 때 필요한 chain입니다. 이 chain에서 허락하지 않는다면 단 하나의 패킷도 외부로 전달할 수 없게 됩니다. 외부의 특정 포트와 통신할 수 있을지 없을지를 결정합니다. 그래서 개별 어플리케이션이 각각 어떤 포트와 통신하는지 모르는 경우 이 chain을 이용하여 전반적으로 outbound 트래픽을 관리할 수 있습니다.POSTROUTING: 이 chain은 패킷이 마지막으로 컴퓨터를 떠나기 직전에 실행됩니다. 우리가 원하는 곳으로 잘 라우팅이 되는지 확인하기 위해 많이 사용됩니다.FORWARD: 이 chain은 오직ip_forward가 활성화 되었을 때만 동작합니다. 그렇기 때문에 쿠버네티스를 구축할 때 다음 명령을 실행하는 것이 중요합니다.
$ node-1# sysctl -w net.ipv4.ip_forward=1
# net.ipv4.ip_forward = 1
$ node-1# cat /proc/sys/net/ipv4/ip_forward
# 1
참고로 위의 명령은 일시적으로만 적용됩니다. 서버 재시작 이후에도 해당 설정이 적용될 수 있게 완벽히 설졍 변경을 저장하려면 /etc/sysctl.conf 파일에 다음 설정을 입력해야 합니다.
net.ipv4.ip_forward = 1
tables
NAT 테이블을 한번 살펴 봅시다. 다음과 같은 테이블이 존재합니다.
Filter: default 테이블입니다. 패킷이 컴퓨터로 들어올 수 있는지, 나갈 수 있는지를 결정합니다. 특정 포트로 패킷이 들어오는 걸 막고 싶다면 여기에 설정합니다.Nat: 두번째로 가장 유명한 테이블입니다. 새로운 커넥션을 만드는 역할을 수행합니다. 이것을 네트워크 주소 변환(Network Address Translation)이라고 합니다. 아래의 예시에서 조금 더 자세히 설명 드립니다.Mangle: 특정 패킷을 위해 존재합니다. 패킷이 컴퓨터로 들어오거나 나갈 때, 패킷의 특정 부분을 수정할 때 사용합니다.Raw: 이름에서 알 수 있듯이 raw 패킷을 처리할 때 사용됩니다. 주로 커넥션의 상태를 추척할 때 사용됩니다.Security: filter 테이블 이후에 컴퓨터를 보호하기 위해 사용됩니다. 현대 리눅스 배포판의 강력한 보안툴로 많이 활용됩니다.(SELinux)
iptables에 관련 더 자세한 정보를 원하신다면 다음 페이지를 참고하시기 바랍니다.
쿠버네티스 iptable 설정
minkube를 이용하여 2개의 replica로 구성된 Nginx 어플리케이션을 배포해 봅시다.
- ServiceType:
NodePort
$ master# kubectl get svc webapp
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# webapp NodePort 10.103.46.104 <none> 80:31380/TCP 3d13h
$ master# kubectl get ep webapp
# NAME ENDPOINTS AGE
# webapp 10.244.120.102:80,10.244.120.103:80 3d13h
ClusterIP를 찾아보아도 어디에도 실제로 존재하는 IP가 아닙니다. 이것은 가상IP로, 쿠버네티스 iptables로 존재하고 쿠버네티스 내부 DNS(CoreDNS)로 질의할 수 있습니다.
$ master# kubectl exec -i -t dnsutils -- nslookup webapp.default
# Server: 10.96.0.10
# Address: 10.96.0.10#53
# Name: webapp.default.svc.cluster.local
# Address: 10.103.46.104
쿠버네티스가 패킷 필터링과 NAT를 수행하기 위해, iptables에 KUBE-SERVICES라는 사용자 정의 chain을 생성합니다. 이것은 모든 PREROUTING과 OUTPUT 트래픽을 KUBE-SERVICES로 보내게 합니다. 다음 예시를 살펴 보시죠.
$ sudo iptables -t nat -L PREROUTING | column -t
# Chain PREROUTING (policy ACCEPT)
# target prot opt source destination
# cali-PREROUTING all -- anywhere anywhere /* cali:6gwbT8clXdHdC1b1 */
# KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
# DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
KUBE-SERVICES chain을 이용하여 쿠버네티스는 Service로 향하는 모든 트래팩을 검사(inspect)하여 SNAT/DNAT를 알맞게 수행할 수 있습니다.
역자주: 쿠버네티스는 Service IP를 Pod IP로 매핑을 시켜 (기술적으로는 DNAT/SNAT) Service를 구현하고 있고 그것에 대한 iptables 내용을 설명하고 있습니다. 더 자세한 내용은 커피고래의 Service 네트워크 이해하기를 참고하시기 바랍니다.
KUBE-SERVICES chain 끝에서는 KUBE-NODEPORTS라는 또 다른 사용자 정의 chain가 있어 특정 NodePort의 트래픽을 처리할 때 사용됩니다.
아래 예시에서 ClusterIP의 경우, KUBE-SVC-2IRACUALRELARSND라는 이름의 chain을 통해 트래픽을 처리하고 그 외에는 그 다음 chain인 KUBE-NODEPORTS가 처리합니다.
$ sudo iptables -t nat -L KUBE-SERVICES | column -t
# Chain KUBE-SERVICES (2 references)
# target prot opt source destination
# KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
# KUBE-SVC-2IRACUALRELARSND tcp -- anywhere 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
# KUBE-NODEPORTS all -- anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
KUBE-NODEPORTS에 어떤 chain이 있는지 확인해 봅시다.
$ sudo iptables -t nat -L KUBE-NODEPORTS | column -t
# Chain KUBE-NODEPORTS (1 references)
# target prot opt source destination
# KUBE-MARK-MASQ tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
# KUBE-SVC-2IRACUALRELARSND tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
이것으로 보아, ClusterIP와 NodePort 둘다 결국에는 동일하게 처리되는 것을 알 수 있습니다(KUBE-SVC-XXX). 다음 iptables 흐름도를 살펴 봅시다. (가독성을 위해 일부 결과만 표시하였습니다.)
$ sudo iptables -t nat -L KUBE-SVC-2IRACUALRELARSND | column -t
# Chain KUBE-SVC-2IRACUALRELARSND (2 references)
# target prot opt source destination
# KUBE-SEP-AO6KYGU752IZFEZ4 all -- anywhere anywhere /* default/webapp */ statistic mode random probability 0.50000000000
# KUBE-SEP-PJFBSHHDX4VZAOXM all -- anywhere anywhere /* default/webapp */
$ sudo iptables -t nat -L KUBE-SEP-AO6KYGU752IZFEZ4 | column -t
# Chain KUBE-SEP-AO6KYGU752IZFEZ4 (1 references)
# target prot opt source destination
# KUBE-MARK-MASQ all -- 10.244.120.102 anywhere /* default/webapp */
# DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.102:80
# /* 10.244.120.102:80 로 DNAT 되어 있는 것을 확인할 수 있습니다. */
$ sudo iptables -t nat -L KUBE-SEP-PJFBSHHDX4VZAOXM | column -t
# Chain KUBE-SEP-PJFBSHHDX4VZAOXM (1 references)
# target prot opt source destination
# KUBE-MARK-MASQ all -- 10.244.120.103 anywhere /* default/webapp */
# DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.103:80
# /* 10.244.120.103:80 로 DNAT 되어 있는 것을 확인할 수 있습니다. */
$ sudo iptables -t nat -L KUBE-MARK-MASQ | column -t
# Chain KUBE-MARK-MASQ (24 references)
# target prot opt source destination
# MARK all -- anywhere anywhere MARK or 0x4000
둘다 KUBE-SERVICES로 시작하여,
- ClusterIP의 경우:
KUBE-SERVICES→KUBE-SVC-XXX→KUBE-SEP-XXX - NodePort의 경우:
KUBE-SERVICES→KUBE-NODEPORTS→KUBE-SVC-XXX→KUBE-SEP-XXX
(참고: NodePort Service의 경우도, 내/외부 트래픽을 처리하기 위해 ClusterIP가 존재합니다.)
이것을 도식화하면 다음과 같습니다.
ExtrenalTrafficPolicy: Local
앞서 살펴본 바와 같이, externalTrafficPolicy: Local은 source IP를 유지 시켜주고, localhost에 Pod IP에 대한 끝점(endpoint)이 없는 경우, 패킷을 drop 시킵니다. local endpoint 없는 노드의 iptables을 한번 살펴 봅시다.
$ master# kubectl get nodes
# NAME STATUS ROLES AGE VERSION
# minikube Ready master 6d1h v1.19.2
# minikube-m02 Ready <none> 85m v1.19.2
Nginx를 externalTrafficPolicy: Local 으로 배포 합니다.
$ master# kubectl get pods nginx-deployment-7759cc5c66-p45tz -o wide
# NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
# nginx-deployment-7759cc5c66-p45tz 1/1 Running 0 29m 10.244.120.111 minikube <none> <none>
$ master# kubectl get svc webapp -o wide -o jsonpath={.spec.externalTrafficPolicy}
# Local
$ master# kubectl get svc webapp -o wide
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
# webapp NodePort 10.111.243.62 <none> 80:30080/TCP 29m app=webserver
Nginx Pod가 존재하지 않는 minikube-m02 노드의 iptables를 확인해 봅시다. 해당 노드에는 Nginx Pod가 없기 때문에 local endpoint가 존재하지 않고 그렇기에 DROP 규칙이 존재할 것입니다.
$ sudo iptables -t nat -L KUBE-NODEPORTS
# Chain KUBE-NODEPORTS (1 references)
# target prot opt source destination
# KUBE-MARK-MASQ tcp — 127.0.0.0/8 anywhere /* default/webapp */ tcp dpt:30080
# KUBE-XLB-2IRACUALRELARSND tcp — anywhere anywhere /* default/webapp */ tcp dpt:30080
KUBE-XLB-2IRACUALRELARSND chain을 살펴 봅시다.
$ sudo iptables -t nat -L KUBE-XLB-2IRACUALRELARSND
# Chain KUBE-XLB-2IRACUALRELARSND (1 references)
# target prot opt source destination
# KUBE-SVC-2IRACUALRELARSND all — 10.244.0.0/16 anywhere /* Redirect pods trying to reach external loadbalancer VIP to clusterIP */
# KUBE-MARK-MASQ all — anywhere anywhere /* masquerade LOCAL traffic for default/webapp LB IP */ ADDRTYPE match src-type LOCAL
# KUBE-SVC-2IRACUALRELARSND all — anywhere anywhere /* route LOCAL traffic for default/webapp LB IP to service chain */ ADDRTYPE match src-type LOCAL
# KUBE-MARK-DROP all — anywhere anywhere /* default/webapp has no local endpoints */
# /* KUBE-MARK-DROP 이 존재하는 것을 확인할 수 있습니다. */
minikube 노드의 iptables도 살펴 봅시다.
$ sudo iptables -t nat -L KUBE-NODEPORTS
# Chain KUBE-NODEPORTS (1 references)
# target prot opt source destination
# KUBE-MARK-MASQ tcp — 127.0.0.0/8 anywhere /* default/webapp */ tcp dpt:30080
# KUBE-XLB-2IRACUALRELARSND tcp — anywhere anywhere /* default/webapp */ tcp dpt:30080
$ sudo iptables -t nat -L KUBE-XLB-2IRACUALRELARSND
# Chain KUBE-XLB-2IRACUALRELARSND (1 references)
# target prot opt source destination
# KUBE-SVC-2IRACUALRELARSND all — 10.244.0.0/16 anywhere /* Redirect pods trying to reach external loadbalancer VIP to clusterIP */
# KUBE-MARK-MASQ all — anywhere anywhere /* masquerade LOCAL traffic for default/webapp LB IP */ ADDRTYPE match src-type LOCAL
# KUBE-SVC-2IRACUALRELARSND all — anywhere anywhere /* route LOCAL traffic for default/webapp LB IP to service chain */ ADDRTYPE match src-type LOCAL
# KUBE-SEP-5T4S2ILYSXWY3R2J all — anywhere anywhere /* Balancing rule 0 for default/webapp */
$ sudo iptables -t nat -L KUBE-SVC-2IRACUALRELARSND
# Chain KUBE-SVC-2IRACUALRELARSND (3 references)
# target prot opt source destination
# KUBE-SEP-5T4S2ILYSXWY3R2J all — anywhere anywhere /* default/webapp */
minikube 노드에는 Service Endpoint(KUBE-SEP-5T4S2ILYSXWY3R2J)가 존재하는 것을 확인할 수 있습니다.
Headless Services
쿠버네티스 공식 홈페이지의 설명을 그대로 가져왔습니다.
간혹 단일 Service IP에 대해서 로드 밸런싱이 필요하지 않는 경우가 있습니다. 이럴 때, ClusterIP를 “None”으로 명시하여 “headless” 라는 서비스를 만들 수 있습니다.(.spec.clusterIP) 쿠버네티스 네트워크 구현에 엮이지 않고 다른 Service Discovery 메커니즘을 사용할 때 활용할 수 있는 방법입니다.
headless Service를 사용하면 Cluster IP가 할당되지 않고 kube-proxy에 의해 Service 트래픽이 처리되지 않습니다. 그렇기에 기본적으로 제공되는 로드밸런싱 기능도 동작하지 않습니다.
다음 두가지 selector 방식에 따라 DNS가 설정됩니다:
With selectors
selector가 있는 경우, endpoint controller에 의해 각 Pod마다 Endpoint가 생성되고 Service에 대해 DNS 질의를 하는 경우, 모든 Endpoint IP들이 반환됩니다.
$ master# kubectl get svc webapp-hs
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# webapp-hs ClusterIP None <none> 80/TCP 24s
$ master# kubectl get ep webapp-hs
# NAME ENDPOINTS AGE
# webapp-hs 10.244.120.109:80,10.244.120.110:80 31s
Without selectors
selector가 없는 경우, Endpoint 조차 만들어지지 않습니다. 단지 DNS 시스템이 다음 둘중 하나로 DNS를 설정합니다:
- ExternalName 타입일 경우, CNAME 레코드를 반환합니다.
- Service와 같은 이름을 가진 아무 Endpoint의 A 레코드를 반환합니다. (역자주: 다음 stackoverflow를 참고하시기 바랍니다.)
만약 클러스터 외부로 라우팅되는 external IP가 있는 경우 이 방법을 이용할 수 있습니다. headless Service로 오는 트래픽이 external IP로 라우팅이 될 것입니다. 이 external IP는 쿠버네티스에 의해 관리되지 않으며 직접 관리해야 합니다.
Network Policy
지금쯤 쿠버네티스에서 네트워크 정책이 어떻게 구현되었는지 어느 정도 짐작할 수 있을 것입니다. 네, 그렇습니다. 네트워크 정책도 마찬가지로 iptables로 구현되어 있습니다. 단, 이번에는 CNI에 의해 구현되어 있습니다. (역자주: 쿠버네티스 공통으로 사용하는 kube-proxy에서 구현된 것이 아닌, 각 CNI마다 구현되어 있기 때문에 CNI에 따라서 구현 방식이 다를 수도 있습니다.)
먼저 3가지 서비스를 생성해 봅시다 — frontend, backend, db
기본적으로 Pod들의 트래픽은 전부 열려 있습니다. (accept from any source)
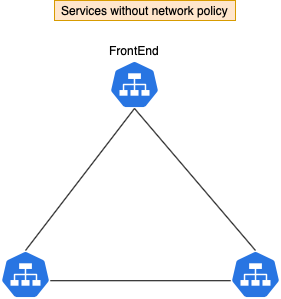
하지만 frontend에서 직접적으로 DB에 접근하는 것을 막기 위해 db Pod의 트래픽을 제한할 필요가 있습니다.
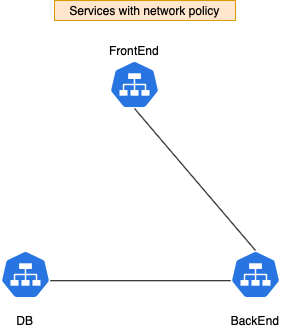
쿠버네티스 네트워크 정책 설정 방법을 이해하기 위해서 다음 내용을 참고하길 추천 드립니다. 이번 블로그에서는 네트워크 정책 설정 방법 보다는 어떻게 구현되어 있는지에 대해 집중해 볼 예정입니다.
(역자주: 다음 블로그 내용도 참고하시면 이해하는데 도움이 될 것 같습니다.)
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-db-access
spec:
podSelector:
matchLabels:
app: "db"
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
networking/allow-db-access: "true"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
networking/allow-db-access: "true"
spec:
volumes:
- name: workdir
emptyDir: {}
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
initContainers:
- name: install
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', "echo $HOSTNAME > /work-dir/index.html"]
volumeMounts:
- name: workdir
mountPath: "/work-dir"
# ...
NetworkPolicy를 통해 db Pod를 frontend Pod로부터 분리하였습니다.
참고: 위의 그림은 이해를 돕기 위해 Service 아이콘으로 표현하였지만 실제 구현은 각 Pod마다 규칙이 적용됨을 유의하시기 바랍니다.
$ master# kubectl exec -it frontend-8b474f47-zdqdv -- /bin/sh
$ curl backend
# backend-867fd6dff-mjf92
$ curl db
# curl: (7) Failed to connect to db port 80: Connection timed out
backend에서는 아무런 문제 없이 db로 접근할 수 있습니다.
$ master# kubectl exec -it backend-867fd6dff-mjf92 -- /bin/sh
$ curl db
# db-8d66ff5f7-bp6kf
위의 NetworkPolicy에서 볼 수 있듯이 allow-db-access: true 라벨을 가진 Pod만 접근이 가능하게 만들었습니다.
Calico는 쿠버네티스 NetworkPolicy 리소스를 그들만의 형식으로 변환하여 적용합니다.
$ master# calicoctl get networkPolicy --output yaml
# apiVersion: projectcalico.org/v3
# items:
# - apiVersion: projectcalico.org/v3
# kind: NetworkPolicy
# metadata:
# creationTimestamp: "2020-11-05T05:26:27Z"
# name: knp.default.allow-db-access
# namespace: default
# resourceVersion: /53872
# uid: 1b3eb093-b1a8-4429-a77d-a9a054a6ae90
# spec:
# ingress:
# - action: Allow
# destination: {}
# source:
# selector: projectcalico.org/orchestrator == 'k8s' && networking/allow-db-access
# == 'true'
# order: 1000
# selector: projectcalico.org/orchestrator == 'k8s' && app == 'db'
# types:
# - Ingress
# kind: NetworkPolicyList
# metadata:
# resourceVersion: 56821/56821
여기서 iptables이 네트워크 정책을 수행하는데 있어서 중요한 역할을 합니다. 다만 Calico에서 ipset과 같이 고급 기술을 사용하여 완벽하게 리버스 엔지니어링을 하는 것은 힘들지만 iptables 규칙을 보면서 어떻게 구현이 되어 있는지 간단하게 살펴 봅시다.
calicoctl을 이용하여 개별 endpoint를 찾습니다.
$ master# calicoctl get workloadEndpoint
# WORKLOAD NODE NETWORKS INTERFACE
# backend-867fd6dff-mjf92 minikube 10.88.0.27/32 cali2b1490aa46a
# db-8d66ff5f7-bp6kf minikube 10.88.0.26/32 cali95aa86cbb2a # <-- db Pod interface
# frontend-8b474f47-zdqdv minikube 10.88.0.24/32 cali505cfbeac50
cali95aa86cbb2a: 이것은 dp Pod가 사용하는 veth pair의 host쪽 네트워크 인터페이스입니다. (역자주: 기억이 잘 나지 않는다면 쿠버네티스 패킷의 삶#1를 다시 읽어보시길 바랍니다.)
해당 네트워크 인터페이스에 적용된 iptables을 살펴 봅시다.
$ sudo iptables-save | grep cali95aa86cbb2a
# :cali-fw-cali95aa86cbb2a - [0:0]
# :cali-tw-cali95aa86cbb2a - [0:0]
# -A cali-from-wl-dispatch -i cali95aa86cbb2a -m comment --comment "cali:R489GtivXlno-SCP" -g cali-fw-cali95aa86cbb2a
# -A cali-fw-cali95aa86cbb2a -m comment --comment "cali:3XN24uu3MS3PMvfM" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
# ....
# -A cali-tw-cali95aa86cbb2a -m comment --comment "cali:pm-LK-c1ra31tRwz" -m mark --mark 0x0/0x20000 -j cali-pi-_tTE-E7yY40ogArNVgKt # 이 부분 참고
# ...
$ sudo iptables-save -t filter | grep cali-pi-_tTE-E7yY40ogArNVgKt
# :cali-pi-_tTE-E7yY40ogArNVgKt - [0:0]
# -A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:M4Und37HGrw6jUk8" -m set --match-set cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge src -j MARK --set-xmark 0x10000/0x10000
# -A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:sEnlfZagUFRSPRoe" -m mark --mark 0x10000/0x10000 -j RETURN
cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge 부분을 ipset으로 찾아보면 오직 backend Pod IP(10.88.0.27)에 대해서만 열려 있는 것을 확인할 수 있습니다.
[root@minikube /]# ipset list
# Name: cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge
# Type: hash:net
# Revision: 6
# Header: family inet hashsize 1024 maxelem 1048576
# Size in memory: 408
# References: 3
# Number of entries: 1
# Members:
# 10.88.0.27
References:
마치며
쿠버네티스 네트워킹은 공부하면 할수록 어렵고 공부할 것이 더 많아지는 것 같습니다. 번역하는 글의 모든 기술적 내용을 충분히 다 이해하지 못한 상황에서 번역을 진행하는 것이 맞을까 고민하였지만 일단 공부하는 차원에서 번역을 진행해 보았습니다. 쿠버네티스 네트워킹을 공부하시는 많은 분들에게 조금이나마 도움 되었기를 바라고 혹시나 오역이나 잘못된 정보가 있다면 언제든지 피드백 부탁 드리겠습니다. 그러면 오늘도 즐겁게 쿠버네티스 공부 하시길 바랍니다!