![[번역]쿠버네티스 패킷의 삶 - #1](/assets/images/packet-life/landing01.png)
[번역]쿠버네티스 패킷의 삶 - #1
21 min read
쿠버네티스 네트워킹은 언제나 맘 한구석의 숙제 같은 녀석입니다. 제대로 공부해야지 하면서도 그 방대한 양과 내용에 쉽게 시작하질 못합니다. 이번 번역 포스트는 예전 글, 쿠버네티스 네트워킹 이해하기 시리즈와는 조금 다르게 직접 예제를 따라해 볼 수 있는 방법으로 진행이 됩니다. 혹시나 쿠버네티스 네트워킹, CNI에 대해서 처음 공부하시는 단계라면 먼저 예전 네트워킹 이해하기 시리즈부터 보시기를 추천드립니다. 내용이 어느 정도 겹치긴 하나, 예전 글이 조금 더 큰 그림에서의 개괄론적인 내용이 주로 있고 이번 포스트는 조금 더 상세한 방법에 대해 소개합니다.
쿠버네티스 클러스터 네트워킹은 꽤나 복잡합니다. 심지어 가상 네트워크와 라우팅에 경험 많은 엔지니어들 조차도 헷갈려 합니다. 이 글은 쿠버네티스 네트워킹의 근본을 이해하기 위한 것입니다. 원래는 쿠버네티스의 복잡한 네트워킹을 클러스터로 향하는 HTTP 요청을 따라가며 설명 드릴려고 하였습니다. 하지만 리눅스 namespace, CNI와 calico에 대한 내용 없이는 쿠버네티스의 네트워킹에 대해 완벽히 이해하기 어려울 것으로 생각하며 먼저 해당 주제에 대해 다뤄보도록 하겠습니다. 이 글은 다음과 같이 큰 주제로 나눠봤습니다.
쿠버네티스 패킷의 삶 시리즈
1탄 컨테이너 네트워킹과 CNI
- 리눅스 namespaces
- 컨테이너 네트워킹
- CNI란 무엇인가?
- Pod 네트워크 namespace
2탄 Calico CNI
- Calico CNI
3탄 Service 네트워킹
- Pod - Pod 통신
- Pod - 외부 통신
- Pod - Service 통신
- 외부 통신
- 외부 트래픽 정책
- Kube-Proxy
- iptable rules 처리 흐름
- Network 정책
4탄 Ingress
- Ingress Controller
- Ingress 예제
- Nginx
- Envoy + Contour
- Ingress와 MetalLB
리눅스 Namespaces
리눅스 namespace는 현대 컨테이너 구현에 있어서 근간이 되는 기술입니다. 큰 그림에서 살펴 보자면, 이 기술을 이용하여 전체 시스템 리소스로부터 개별 프로세스를 격리 시켜 줍니다. 예를 들어, PID namespace는 프로세스의 PID를 전체 process ID 공간으로부터 분리 시켜줍니다. 이 뜻은 두개의 다른 프로세스가 한 호스트에서 동일한 PID를 가질 수 있다는 것을 의미합니다!
이러한 고립화 기술은 컨테이너 세계에서 아주 유용합니다. namespace 기술이 없다면, 같은 호스트에서 실행되고 있는 컨테이너 A가 컨테이너 B의 파일시스템을 unmount할 수도 있고 컨테이너 C의 hostname을 마음대로 바꿀 수도 있습니다. 또는 컨테이너 D의 네트워크 인터페이스를 함부로 제거할 수도 있습니다. 이러한 리소스들을 개별적으로 제한함으로써(namespacing) 컨테이너 A는 다른 B, C, D 컨테어너의 존재 조차 모르게 합니다. (역자주: namespacing이란, 자바에서 같은 클래스 이름을 가져도 패키지 이름이 다르면 상관 없듯이 동일한 리소스를 namespacing함으로써 서로 구분하는 것을 의미합니다.)
- Mount — 파일시스템 마운트포인트 격리
- UTS — hostname와 도메인 이름 격리
- IPC — IPC(프로세스간 통신) 리소스 격리
- PID — PID 주소공간 격리
- Network — 네트워크 인터페이스 격리
- User — UID/GID 공간 격리
- Cgroup — cgroup 디렉토리 격리
대부분의 컨테이너 구현체들은 컨테이너 격리를 구현하기 위해 위와 같은 namespace 기술들을 사용합니다. 단, cgroup namespace는 다른 것들이 비해 최근의 기술이고 아직까진 전반적으로 사용되진 않습니다.
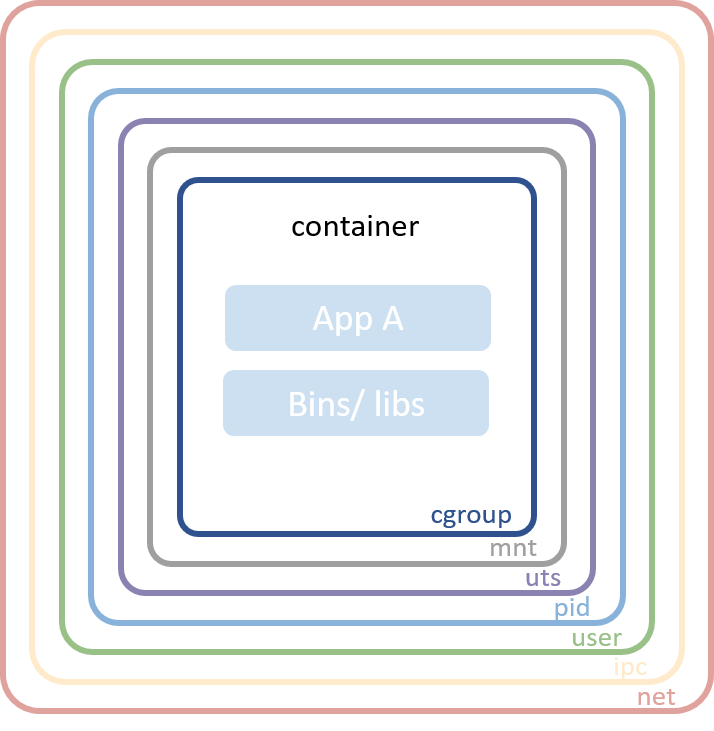
컨테이너 네트워킹 (Network Namespace)
CNI와 도커의 여러 옵션들을 살펴보기 전에, 컨테이너 네트워킹을 가능케하는 핵심 기술에 대해서 이해하는 시간을 가져 봅시다. 리눅스 커널은 멀티테넌시를 제공하기 위한 여러가지 기능들을 가지고 있습니다. Namespace는 다양한 리소스의 격리를 위한 기능을 제공합니다. 그 중에서 네트워크 namespace는 네트워크 격리를 제공합니다.
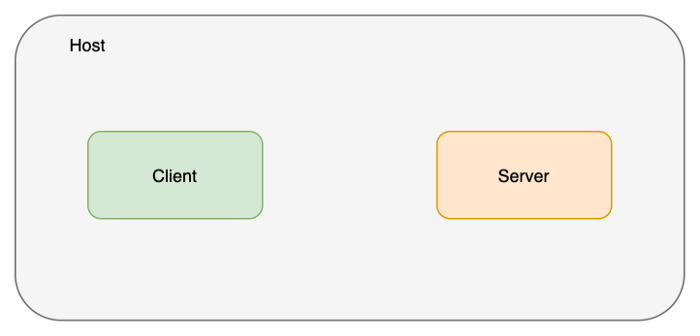
네트워크 namespace를 사용하는 것은 굉장히 쉽습니다. 대부분의 리눅스에서 제공하는 ip 명령을 이용합니다. 아래와 같이 두개(client와 server)의 네트워크 namespace를 만들어 보겠습니다.
master# ip netns add client
master# ip netns add server
master# ip netns list
# server
# client
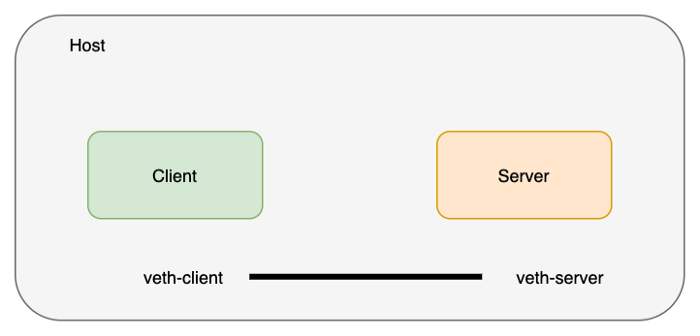
네트워크 namespace를 연결하기 위해 veth 페어를 생성합니다. veth 페어는 두개의 장비를 이어주는 네트워크 케이블라고 생각하시면 이해하기 쉽습니다.
master# ip link add veth-client type veth peer name veth-server
master# ip link list | grep veth
# 4: veth-server@veth-client: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
# 5: veth-client@veth-server: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
vetch 페어 (케이블)은 호스트 네트워크 namespace에 존재합니다. 이것을 각 namespace(client와 server)로 옮깁니다.
master# ip link set veth-client netns client
master# ip link set veth-server netns server
# 호스트 네트워크에는 더이상 veth이 보이지 않습니다.
master# ip link list | grep veth
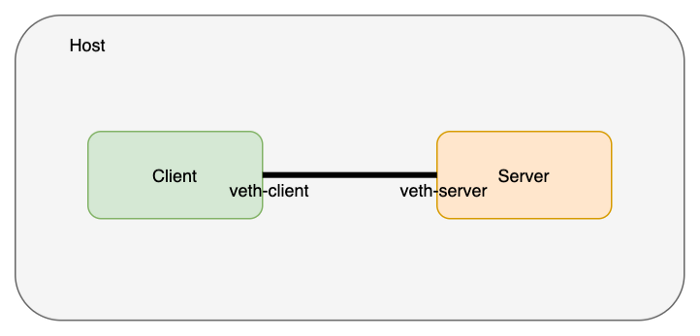
Let’s verify the veth ends actually exist in the namespaces. We’ll start with the client namespace
veth가 각 namespace에 존재하는지 확인해 봅시다. client namespace부터 확인합니다.
master# ip netns exec client ip link
# 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 5: veth-client@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
# link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1
이번에는 server namespace를 확인합니다.
master# ip netns exec server ip link
# 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 4: veth-server@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
# link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
이제 이 네트워크 인터페이스들에 IP를 할당하고 동작(up) 시킵니다.
master# ip netns exec client ip address add 10.0.0.11/24 dev veth-client
master# ip netns exec client ip link set veth-client up
master# ip netns exec server ip address add 10.0.0.12/24 dev veth-server
master# ip netns exec server ip link set veth-server up
master#
master# ip netns exec client ip addr
# 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 5: veth-client@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
# link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1
# inet 10.0.0.11/24 scope global veth-client
# valid_lft forever preferred_lft forever
# inet6 fe80::c8e8:30ff:fe2e:f9d2/64 scope link
# valid_lft forever preferred_lft forever
master#
master# ip netns exec server ip addr
# 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# 4: veth-server@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
# link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# inet 10.0.0.12/24 scope global veth-server
# valid_lft forever preferred_lft forever
# inet6 fe80::4096:f0ff:feae:f0c5/64 scope link
# valid_lft forever preferred_lft forever
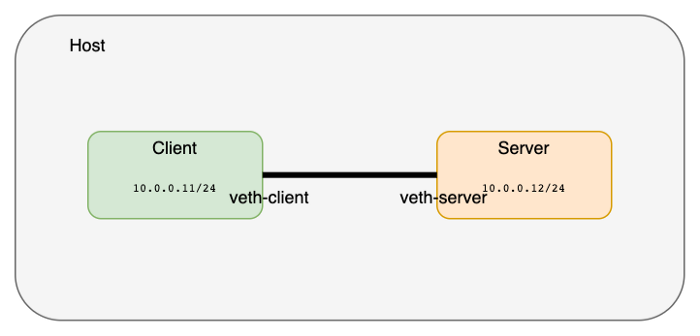
ping 명령을 이용하여 두개의 네트워크 namespace가 연결되어 접근이 되는지 확인합니다.
master# ip netns exec client ping 10.0.0.12
# PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data.
# 64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.101 ms
# 64 bytes from 10.0.0.12: icmp_seq=2 ttl=64 time=0.072 ms
# 64 bytes from 10.0.0.12: icmp_seq=3 ttl=64 time=0.084 ms
# 64 bytes from 10.0.0.12: icmp_seq=4 ttl=64 time=0.077 ms
# 64 bytes from 10.0.0.12: icmp_seq=5 ttl=64 time=0.079 ms
지금까지 두개의 서로 다른 네트워크 namespace를 연결해 보았습니다. namespace가 두개 밖에 없는 경우에는 큰 문제가 아니지만 매번 네트워크 namespace가 늘어날때 마다 이런 방식을 사용하는 것은 확장성 관점에서 비효율적입니다. namespace가 늘어나는 만큼 모든 namespace를 연결하기 위한 조합이 기하급수적으로 늘어나기 때문입니다.(n*(n-1)/2) 대신 리눅스 bridge를 만들어서 모든 네트워크 namespace들을 전부 이 bridge에 연결할 수 있습니다. 이것이 바로 도커가 같은 호스트에서 컨테이너 네트워크를 연결하는 방식입니다.
이번에는 namespace들을 만들어서 bridge에 연결해 봅시다.
# All in one
BR=bridge1
HOST_IP=172.17.0.33
ip link add client1-veth type veth peer name client1-veth-br
ip link add server1-veth type veth peer name server1-veth-br
ip link add $BR type bridge
ip netns add client1
ip netns add server1
ip link set client1-veth netns client1
ip link set server1-veth netns server1
ip link set client1-veth-br master $BR
ip link set server1-veth-br master $BR
ip link set $BR up
ip link set client1-veth-br up
ip link set server1-veth-br up
ip netns exec client1 ip link set client1-veth up
ip netns exec server1 ip link set server1-veth up
ip netns exec client1 ip addr add 172.30.0.11/24 dev client1-veth
ip netns exec server1 ip addr add 172.30.0.12/24 dev server1-veth
ip netns exec client1 ping 172.30.0.12 -c 5
ip addr add 172.30.0.1/24 dev $BR
ip netns exec client1 ping 172.30.0.12 -c 5
ip netns exec client1 ping 172.30.0.1 -c 5
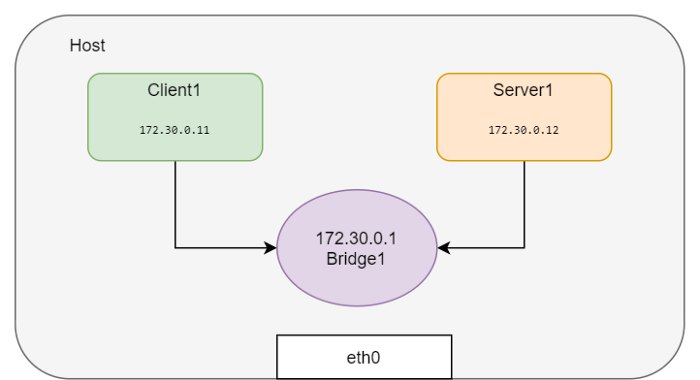
bridge를 이용한 방법도 동일하게 두개의 namespace가 연결된 것을 확인할 수 있습니다.
controlplane $ ip netns exec client1 ping 172.30.0.12 -c 5
# PING 172.30.0.12 (172.30.0.12) 56(84) bytes of data.
# 64 bytes from 172.30.0.12: icmp_seq=1 ttl=64 time=0.138 ms
# 64 bytes from 172.30.0.12: icmp_seq=2 ttl=64 time=0.091 ms
# 64 bytes from 172.30.0.12: icmp_seq=3 ttl=64 time=0.073 ms
# 64 bytes from 172.30.0.12: icmp_seq=4 ttl=64 time=0.070 ms
# 64 bytes from 172.30.0.12: icmp_seq=5 ttl=64 time=0.107 ms
client1 namespace에서 호스트로 ping을 날려 봅시다.
controlplane $ ip netns exec client1 ping $HOST_IP -c 2
# connect: Network is unreachable
Network is unreachable라고 나오는데요, 이것은 정상입니다. 왜냐하면 새롭게 생성한 namespace에는 라우팅 정보가 설정되어 있지 않기 때문입니다. 기본 라우팅 정보를 입력합니다.
# default G/W를 bridge로 향하게 합니다.
controlplane $ ip netns exec client1 ip route add default via 172.30.0.1
controlplane $ ip netns exec server1 ip route add default via 172.30.0.1
controlplane $ ip netns exec client1 ping $HOST_IP -c 5
# PING 172.17.0.23 (172.17.0.23) 56(84) bytes of data.
# 64 bytes from 172.17.0.23: icmp_seq=1 ttl=64 time=0.053 ms
# 64 bytes from 172.17.0.23: icmp_seq=2 ttl=64 time=0.121 ms
# 64 bytes from 172.17.0.23: icmp_seq=3 ttl=64 time=0.078 ms
# 64 bytes from 172.17.0.23: icmp_seq=4 ttl=64 time=0.129 ms
# 64 bytes from 172.17.0.23: icmp_seq=5 ttl=64 time=0.119 ms
# --- 172.17.0.23 ping statistics ---
# 5 packets transmitted, 5 received, 0% packet loss, time 3999ms
# rtt min/avg/max/mdev = 0.053/0.100/0.129/0.029 ms
외부로 나가는 기본 라우팅 정보를 bridge로 향하게 만들었습니다. 그렇기 때문에 이제 각 namespace들이 외부로 연결이 가능하게 되었습니다.
controlplane $ ping 8.8.8.8 -c 2
# PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
# 64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=3.40 ms
# 64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=3.81 ms
# --- 8.8.8.8 ping statistics ---
# 2 packets transmitted, 2 received, 0% packet loss, time 1001ms
# rtt min/avg/max/mdev = 3.403/3.610/3.817/0.207 ms
외부에서 내부 네트워크로 접근하는 방법
이제부터는 docker가 호스트에 이미 설치되어 있다고 가정하고 진행합니다. 보시다시피 아래와 같이 호스트에는 docker0이라는 bridge가 있습니다. 이 도커 bridge를 이용하여 앞으로의 데모를 진행하도록 하겠습니다.
docker0 Link encap:Ethernet HWaddr 02:42:e2:44:07:39
inet addr:172.18.0.1 Bcast:172.18.0.255 Mask:255.255.255.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
간단한 nginx 컨테이너를 실행하고 몇가지 정보를 추출합니다.
controlplane $ docker run -d --name web --rm nginx
# efff2d2c98f94671f69cddc5cc88bb7a0a5a2ea15dc3c98d911e39bf2764a556
controlplane $ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
controlplane $ docker inspect web --format "{{ .NetworkSettings.SandboxKey }}"
# /var/run/docker/netns/c009f2a4be71
도커는 netns를 기본 디렉토리 위치에 생성하지 않기 때문에 ip netns list 명령으로는 도커 생성한 네트워크 namespace를 볼 수 없습니다. (역자주: netns 명령을 사용하면 내부적으로 특정 디렉토리 위치에 관련 메터 정보를 저장합니다. 도커의 경우, 기본 디렉토리가 아닌 도커만의 다른 위치를 사용하기 때문에 기본 ip netns list 명령으로도 namespace를 볼 수 있도록 심볼릭 링크를 생성해야 합니다.) 이를 해결하기 위해 심볼릭 링크를 생성해 봅시다.
controlplane $ container_id=web
controlplane $ container_netns=$(docker inspect ${container_id} --format "{{ .NetworkSettings.SandboxKey }}")
controlplane $ mkdir -p /var/run/netns
controlplane $ rm -f /var/run/netns/${container_id}
controlplane $ ln -sv ${container_netns} /var/run/netns/${container_id}
# '/var/run/netns/web' -> '/var/run/docker/netns/c009f2a4be71'
controlplane $ ip netns list
# web (id: 3)
# server1 (id: 1)
# client1 (id: 0)
web namespace안에서의 IP주소를 확인해 봅시다.
controlplane $ ip netns exec web ip addr
# 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
# link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# inet 127.0.0.1/8 scope host lo
# valid_lft forever preferred_lft forever
# 11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
# link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# inet 172.18.0.3/24 brd 172.18.0.255 scope global eth0
# valid_lft forever preferred_lft forever
이번에는 도커 컨테이너의 IP주소를 확인합니다.
controlplane $ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
controlplane $ echo $WEB_IP
# 172.18.0.3
이를 통해 도커가 리눅스 namespace를 이용하여 호스트 서버로부터 컨테이너의 네트워크를 격리한다는 것을 알 수 있습니다. 이제 호스트 서버에서 web namespace 안에서 실행되고 있는 nginx에 접근해 보겠습니다.
controlplane $ curl $WEB_IP
# <!DOCTYPE html>
# <html>
# <head>
# <title>Welcome to nginx!</title>
# <style>
# body {
# width: 35em;
# margin: 0 auto;
# font-family: Tahoma, Verdana, Arial, sans-serif;
# }
# </style>
# </head>
# <body>
# <h1>Welcome to nginx!</h1>
# <p>If you see this page, the nginx web server is successfully installed and
# working. Further configuration is required.</p>
# <p>For online documentation and support please refer to
# <a href="http://nginx.org/">nginx.org</a>.<br/>
# Commercial support is available at
# <a href="http://nginx.com/">nginx.com</a>.</p>
# <p><em>Thank you for using nginx.</em></p>
# </body>
# </html>
정상적으로 접근이 되는 것을 확인했습니다. 그렇다면 이번에는 같은 호스트 서버가 아닌 외부에서 컨테이너 안에 있는 nginx로 접근이 가능할까요? 네, 가능합니다. 바로 포트포워딩 방식을 이용해서 말이죠.
# 호스트 서버 80포트로 들어오는 트래픽을 nginx의 80포트로 포워딩합니다.
controlplane $ iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination $WEB_IP:80
controlplane $ echo $HOST_IP
# $ 172.17.0.23
다른 서버에서 원래 호스트 IP로 웹서버를 접근해 봅시다.
node01 $ curl 172.17.0.23
# <!DOCTYPE html>
# <html>
# <head>
# <title>Welcome to nginx!</title>
# <style>
# body {
# width: 35em;
# margin: 0 auto;
# font-family: Tahoma, Verdana, Arial, sans-serif;
# }
# </style>
# </head>
# <body>
# <h1>Welcome to nginx!</h1>
# <p>If you see this page, the nginx web server is successfully installed and
# working. Further configuration is required.</p>
# <p>For online documentation and support please refer to
# <a href="http://nginx.org/">nginx.org</a>.<br/>
# Commercial support is available at
# <a href="http://nginx.com/">nginx.com</a>.</p>
# <p><em>Thank you for using nginx.</em></p>
# </body>
# </html>
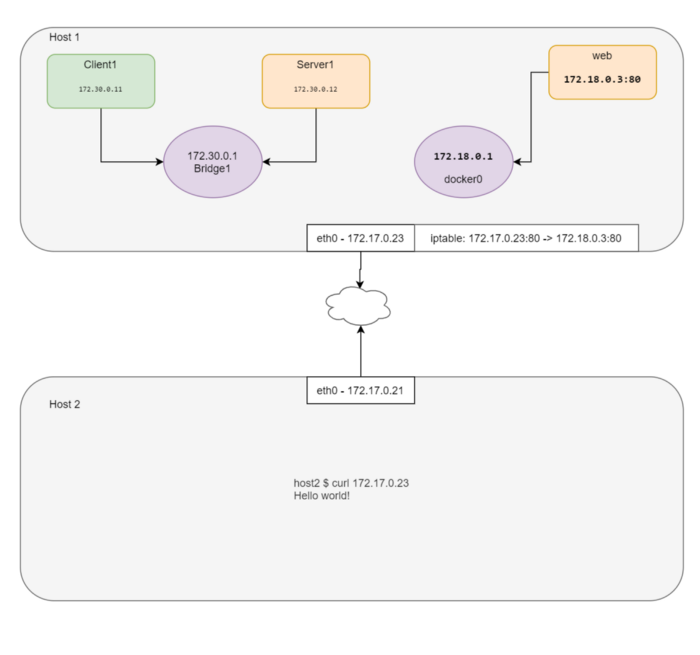
정상적으로 동작하는 것을 확인했습니다. 그리고 CNI plugin이 바로 이런 방식으로 동작합니다.(정확히 동일하진 않지만 비슷합니다.) CNI plugin이 loopback, eth0 인터페이스를 만들고 IP를 컨테이너에게 할당하는 작업을 담당합니다. 컨테이너 runtime (쿠버네티스, PodMan 등)이 바로 이 CNI를 이용하여 Pod 네트워크를 설정합니다.
CNI란 무엇인가?
“CNI plugin은 컨테이너 네트워크 namespace에 네트워크 인터페이스를 삽입하고 호스트에 적절한 변경을 수행하는 것에 책임이 있습니다.(예를 들어, veth 페어를 한쪽 컨테이너에 연결하고 호스트의 bridge에 연결하는 작업 등) 그리고 난 다음 해당 네트워크 인터페이스에 IP를 할당하고 IP대역에 맞는 라우팅 정보를 설정하는 역할을 수행합니다.”
어떤가요? 뭔가 비슷하지 않나요? 맞습니다. 앞서 살펴 본 컨테이너 네트워킹에 대한 내용과 동일합니다.
CNI(Container Network Interface)는 CNCF(Cloud Native Computing Foundation) 프로젝트로, 리눅스 컨테이너의 네트워크 인터페이스를 설정할 수 있도록 도와주는 일련의 명세와 라이브러리로 구성되어 있습니다. CNI는 오직 “컨테이너의 네트워크 연결성”과 “컨테이너 삭제시 관련된 네트워크 리소스 해제”에 대해서만 관여합니다. 그 외의 구체적인 사안에 대해서는 특별히 제한을 두지 않습니다. 이러한 특징 때문에 이를 만족하는 다양한 CNI 구현체가 존재하고 구현하기가 간단합니다.
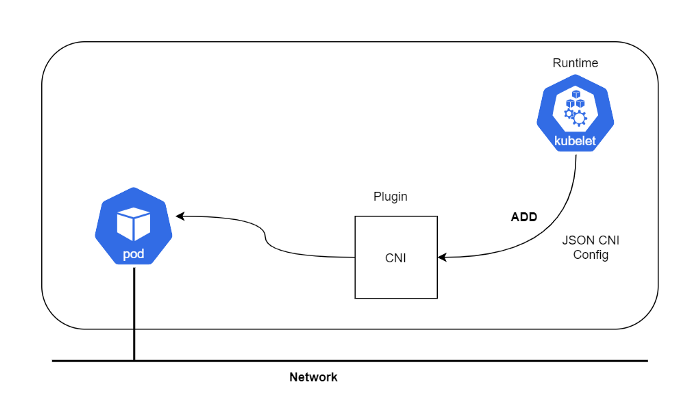
이를 실행하는 runtime은 어떤 것이든 상관 없습니다. (쿠버네티스, PodMan, cloud foundry 등)
CNI 명세
CNCF에 정의된 CNI의 명세는 다음과 같습니다: https://github.com/containernetworking/cni/blob/master/SPEC.md
이 중에서 몇 가지 흥미로운 내용들을 살펴 봅시다.
- 명세에는 컨테이너가 리눅스 네트워크 namespace안에 있다고 정의합니다. 도커와 같은 컨테이너 runtime은 매 컨테이너 실행 시, 새로운 namespace를 만들기에 네트워크 namespace에 대해 잘 알고 있어야 합니다.
- CNI의 네트워크 정의서는 JSON 형식으로 정의됩니다.
- 네트워크 정의서는 STDIN을 통해 스트림으로 CNI plugin에 전달되어야 합니다. 네트워크 설정을 위한 파일이 따로 특정 위치에 저장되어 참조되지 않아야 합니다.
- 다른 매개변수들은 환경변수로 plugin에 전달되어야 합니다.
- CNI plugin은 실행파일(executable)로 구현되어야 합니다.
- CNI plugin은 컨테이너 네트워크 연결에 책임을 가지고 있습니다. (컨테이너가 네트워크에 연결되기 위한 모든 작업에 책임을 가집니다.) 도커에서는 컨테이너의 네트워크 namespace를 호스트에 연결 시키는 것까지 포함됩니다.
- CNI plugin은 IPAM(IP 할당관리)에 책임을 가지고 있습니다. 이것은 IP주소 할당 뿐만 아니라 적절한 라우팅 정보를 입력하는 것까지 포함됩니다.
이제 쿠버네티스를 이용하지 않고 직접 Pod 생성하여 IP를 부여하는 작업을 흉내내 보도록 하겠습니다. 이를 통해 쿠버네티스의 Pod가 무엇인지 더 자세히 이해할 수 있을 것입니다.
1단계: CNI plugin을 다운로드 받습니다.
controlplane $ mkdir cni
controlplane $ cd cni
controlplane $ curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
# % Total % Received % Xferd Average Speed Time Time Time Current
# Dload Upload Total Spent Left Speed
# 100 644 100 644 0 0 1934 0 --:--:-- --:--:-- --:--:-- 1933
# 100 15.3M 100 15.3M 0 0 233k 0 0:01:07 0:01:07 --:--:-- 104k
controlplane $ tar -xvf cni-amd64-v0.4.0.tgz
# ./
# ./macvlan
# ./dhcp
# ./loopback
# ./ptp
# ./ipvlan
# ./bridge
# ./tuning
# ./noop
# ./host-local
# ./cnitool
# ./flannel
2단계: CNI 설정 파일을 JSON 형식으로 정의합니다.
cat > /tmp/00-demo.conf <<"EOF"
{
"cniVersion": "0.2.0",
"name": "demo_br",
"type": "bridge",
"bridge": "cni_net0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.0.10.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.0.10.1"}
]
}
}
EOF
여기서 몇 가지 살펴 볼 CNI 설정들은 다음과 같습니다.
cniVersion: CNI 명세의 버전을 정의합니다.name: 네트워크 이름type: 사용할 plugin 종류를 지정합니다. 이 경우에는 실제 사용할 실행파일의 이름을 지정합니다.args: Optional 추가 파라미터ipMasq: 아웃바운드 masquerade 설정(NAT 설정)ipam:type: IPAM plugin 실행파일의 이름subnet: IPAM에서 사용할 subnet대역routes:dst: 도달하려는 subnet대역gw: dst에 도달하기 위한 default g/w주소
dns:nameservers: 해당 네트워크에서 사용할 네임서버 목록domain: DNS 요청에 사용할 search domainsearch: search domain 목록options: 추가적인 옵션값
3단계: IP주소가 없는 none 네트워크를 가진 컨테이너를 하나 생성합니다.
아무 이미지를 사용해도 무방하나 쿠버네티스를 흉내내기 위해 pause 이미지를 사용합니다.
controlplane $ container_id=pause_demo
controlplane $ docker run --name $container_id -d --rm --network none kubernetes/pause
# Unable to find image 'kubernetes/pause:latest' locally
# latest: Pulling from kubernetes/pause
# 4f4fb700ef54: Pull complete
# b9c8ec465f6b: Pull complete
# Digest: sha256:b31bfb4d0213f254d361e0079deaaebefa4f82ba7aa76ef82e90b4935ad5b105
# Status: Downloaded newer image for kubernetes/pause:latest
# 763d3ef7d3e943907a1f01f01e13c7cb6c389b1a16857141e7eac0ac10a6fe82
controlplane $ container_netns=$(docker inspect ${container_id} --format "{{ .NetworkSettings.SandboxKey }}")
controlplane $ mkdir -p /var/run/netns
controlplane $ rm -f /var/run/netns/${container_id}
controlplane $ ln -sv ${container_netns} /var/run/netns/${container_id}
# '/var/run/netns/pause_demo' -> '/var/run/docker/netns/0297681f79b5'
controlplane $ ip netns list
# pause_demo
controlplane $ ip netns exec $container_id ifconfig
# lo Link encap:Local Loopback
# inet addr:127.0.0.1 Mask:255.0.0.0
# UP LOOPBACK RUNNING MTU:65536 Metric:1
# RX packets:0 errors:0 dropped:0 overruns:0 frame:0
# TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
# collisions:0 txqueuelen:1
# RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
Step 4: Invoke the CNI plugin with the CNI configuration file.
4단계: CNI 설정 파일과 함께 CNI plugin을 실행합니다.
controlplane $ CNI_CONTAINERID=$container_id CNI_IFNAME=eth10 CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/$container_id CNI_PATH=`pwd` ./bridge </tmp/00-demo.conf
# 2020/10/17 17:32:37 Error retriving last reserved ip: Failed to retrieve last reserved ip: open /var/lib/cni/networks/demo_br/last_reserved_ip: no such file or directory
# {
# "ip4": {
# "ip": "10.0.10.2/24",
# "gateway": "10.0.10.1",
# "routes": [
# {
# "dst": "0.0.0.0/0"
# },
# {
# "dst": "1.1.1.1/32",
# "gw": "10.0.10.1"
# }
# ]
# },
# "dns": {}
CNI_COMMAND=ADD: 실행동작 (ADD/DEL/CHECK)CNI_CONTAINER=pause_demo: CNI에게 사용할 network namespace 이름을 전달CNI_NETNS=/var/run/netns/pause_demo: 사용할 network namespace의 위치를 전달CNI_IFNAME=eth10: 컨테이너 내부에서 사용할 네트워크 인터페이스 이름 지정CNI_PATH=`pwd`: CNI에게 plugin 실행파일의 위치를 전달(예시에서는 현재 위치에 있기 때문에pwd명령을 사용)
CNI의 세부 동작 방법에 대해 파악하기 위해 꼭 CNI specification을 한번 읽어 보시는 것을 추천드립니다. 하나의 JSON파일에 한개 이상의 plugin도 사용할 수가 있습니다. (방화벽 규칙 추가 등)
5단계: 위의 명령을 실행하면 몇가지 정보를 반환해 줍니다.
- IPAM이 내부적으로 참조하는 파일을 찾을 수 없다고 에러를 뱉습니다. 다른 namespace에 대해서 동일한 명령을 수행 시, 그때에는 해당 메세지가 발생하지 않습니다. 첫 번째 명령 실행에서 이미 파일이 만들어졌기 때문입니다.
- JSON 객체를 반환합니다. 여기에는 CNI plugin에 의해 할당된 IP주소가 적혀져 있습니다. 예시에서는 bridge가
10.0.10.1/24IP주소를 할당 받고 컨테이너의 네트워크 인터페이스가10.0.10.2/24IP주소를 받았는 것으로 나옵니다. 또한1.1.1.1/32에 도달하귀 위한 default 라우팅 정보도 볼 수 있습니다.
직접 컨테이너의 내부 네트워크 설정을 확인해 봅시다.
controlplane $ ip netns exec pause_demo ifconfig
# eth10 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:02
# inet addr:10.0.10.2 Bcast:0.0.0.0 Mask:255.255.255.0
# UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
# RX packets:18 errors:0 dropped:0 overruns:0 frame:0
# TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
# collisions:0 txqueuelen:0
# RX bytes:1476 (1.4 KB) TX bytes:0 (0.0 B)
# lo Link encap:Local Loopback
# inet addr:127.0.0.1 Mask:255.0.0.0
# UP LOOPBACK RUNNING MTU:65536 Metric:1
# RX packets:0 errors:0 dropped:0 overruns:0 frame:0
# TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
# collisions:0 txqueuelen:1
# RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
controlplane $ ip netns exec pause_demo ip route
# default via 10.0.10.1 dev eth10
# 1.1.1.1 via 10.0.10.1 dev eth10
# 10.0.10.0/24 dev eth10 proto kernel scope link src 10.0.10.2
CNI가 bridge를 생성하고 앞서 정의한 대로 설정값들을 대신 세팅해 줬습니다.
controlplane $ ifconfig
# cni_net0 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:01
# inet addr:10.0.10.1 Bcast:0.0.0.0 Mask:255.255.255.0
# inet6 addr: fe80::c4a4:2dff:fe4b:aa1b/64 Scope:Link
# UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
# RX packets:7 errors:0 dropped:0 overruns:0 frame:0
# TX packets:20 errors:0 dropped:0 overruns:0 carrier:0
# collisions:0 txqueuelen:1000
# RX bytes:1174 (1.1 KB) TX bytes:1545 (1.5 KB)
6단계: 웹 서버를 실행하고 pause 컨테이너와 네트워크를 공유합니다.
controlplane $ docker run --name web_demo -d --rm --network container:$container_id nginx
# 8fadcf2925b779de6781b4215534b32231685b8515f998b2a66a3c7e38333e30
7단계: pause 컨테이너 IP주소를 이용하여 웹 페이지를 요청합니다.
controlplane $ curl `cat /var/lib/cni/networks/demo_br/last_reserved_ip`
# <!DOCTYPE html>
# <html>
# <head>
# <title>Welcome to nginx!</title>
# <style>
# body {
# width: 35em;
# margin: 0 auto;
# font-family: Tahoma, Verdana, Arial, sans-serif;
# }
# </style>
# </head>
# <body>
# <h1>Welcome to nginx!</h1>
# <p>If you see this page, the nginx web server is successfully installed and
# working. Further configuration is required.</p>
# <p>For online documentation and support please refer to
# <a href="http://nginx.org/">nginx.org</a>.<br/>
# Commercial support is available at
# <a href="http://nginx.com/">nginx.com</a>.</p>
# <p><em>Thank you for using nginx.</em></p>
# </body>
# </html>
이제 Pod의 정의에 대해서 살펴 봅시다.
Pod 네트워크 namespace
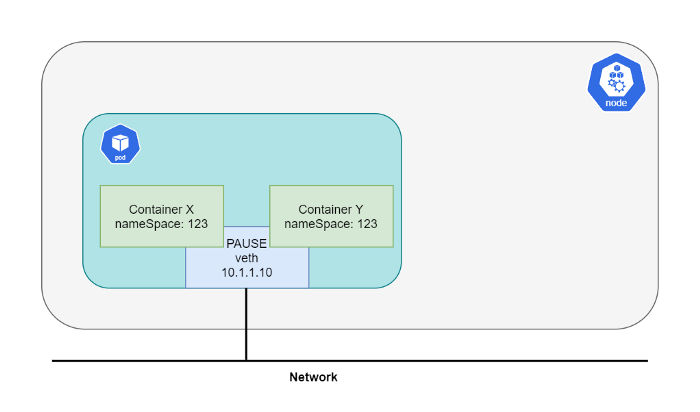
첫번째로 쿠버네티스에서 Pod는 한개 컨테이너와 대응되지 않는다는 사실을 이해해야 합니다. Pod는 여러 컨테이너의 집합입니다. 이 컨테이너들은 동일한 네트워크 스택을 공유합니다. 쿠버네티스는 pause 컨테이너를 사용함으로써 서로 네트워크 스택을 공유하도록 설정합니다. 그래서 이 pause 컨테이너는 실행하는 모든 Pod에 들어있습니다. 다른 모든 컨테이너들이 바로 이 pause 컨테이너에 연결되고 pause 컨테이너가 네트워킹 기능을 제공합니다. 이러한 이유 때문에 Pod 안에 들어있는 컨테이너들이 localhost로 서로 통신할 수 있는 것입니다.
References
- https://man7.org/linux/man-pages/man7/namespaces.7.html
- https://github.com/containernetworking/cni/blob/master/SPEC.md
- https://github.com/containernetworking/cni/tree/master/cnitool
- https://github.com/containernetworking/cni
- https://tldp.org/HOWTO/BRIDGE-STP-HOWTO/set-up-the-bridge.html
- https://kubernetes.io
- https://www.dasblinkenlichten.com
마치며
첫 번째 글은 쿠버네티스 네트워킹 이전에 컨테이너 생성 시점에서, CNI가 어떻게 컨테이너의 네트워크를 설정하는지 상세히 살펴 보았습니다. CNI의 역할은 컨테이너의 네트워크 연결과 삭제, IP주소 할당이라는 네트워크 연결성의 아주 기초적인 부분만 담당하는 것을 이해할 수 있는 시간이었습니다. 다음 편에서는 CNI plugin의 여러 구현체 중 유명한 Calico CNI에 대해서 살펴 보도록 하겠습니다.