Kubernetes와 MLOps #1
9 min read
저는 오늘 kubernetes에 대해 소개하고자 합니다. 사실 이미 인터넷상에는 kubernetes에 대해서 소개하는 글과 동영상들이 많이 있습니다. 또한 쿠버네티스를 이용하여 웹 서비스를 구축하는 예제도 많습니다. 저는 이와는 조금 다르게 기계학습 관점에서 쿠버네티스를 어떻게 활용할 수 있는지 소개하려 합니다.
쿠버네티스의 MLOps는 다음과 같은 시리즈로 구성되어 있습니다.
- 쿠버네티스와 MLOps#1
- 쿠버네티스와 MLOps#2
- 쿠버네티스와 MLOps#3
- 쿠버네티스와 MLOps#4
우리가 모델을 생성할 때, 한 개 모델을 한 서버에서 학습 시키는 것은 비교적 쉽습니다. 그러나 수 많은 모델들을 여러 서버에 걸쳐서 코드를 배포하고 모델을 학습하는 작업은 그리 간단하지 않습니다. 물론 깃으로 소스코드를 관리하고 ansible로 코드를 배포하고 원격으로 학습을 실행하면 쉽게 해결할 수도 있습니다. 혹은 자체적인 모델 학습 서버 cluster를 구축하여 server-side 엔지니어링에 대해서는 더 이상 고민할 필요 없이 모델링에만 집중할 수 있습니다. 이런 경우라면 상당히 체계적인 모델링 플랫폼을 가지고 있다고 할 수 있습니다. 하지만 모든 곳에서 이런 훌륭한 플랫폼을 갖기 힘들 것입니다. 특히나 많은 경우, 빠르게 모델링 결과를 delivery 분석팀 입장에서는 모델 학습 cluster를 구축하기에는 사치일 수도 있습니다. (이는 회사에 따라, 분석팀에 따라 다를 수 있습니다. 개인적인 의견입니다.) 이런 상황에서 자체 학습 cluster를 구축하기는 어렵지만 체계적으로 모델 학습 서버들를 관리하고 운용하기 원한다면 쿠버네티스도 꽤 괜찮은 선택이 될 수 있습니다. 그렇다면 쿠버네티스가 어떤 녀석인지 조금 더 자세히 살펴 볼까요?
kubernetes 간략 소개
쿠버네티스 공식 홈페이지에 쿠버네티스란 컨테이너화된 어플리케이션을 관리하는 시스템이라고 적혀져 있습니다. 저는 처음 쿠버네티스를 접했을 때 도커 컨테이너를 조금 더 효율적으로 관리해 주는 툴 정도로만 인식했습니다. 하지만 쿠버네티스를 직접 사용해보니 그것 보단 여러 서버를 하나로 묶어서 공통적으로 관리하고 컨테이너를 분산하여 실행해주는 cluster management system에 더 가깝다는 것을 깨닫게 되었습니다. 그렇다면 쿠버네티스는 어떤 컨셉을 가지고 cluster management를 하는지 쿠버네티스 진영에서 자주 사용하는 예시를 들어 조금 더 자세히 설명하겠습니다. 쿠버네티스 진영에서는 서버를 애완동물(Pet)보다는 가축(cattle)에 가깝다고 말합니다. 애완동물과 가축의 차이점을 말하자면, 애완동물은 세심한 관리가 필요하고 가축은 떼로 막 키웁니다. 애완동물은 각 개체마다 부르는 이름이 있고 배고프지 않게 밥을 매끼 챙겨주며 아프지 않게 예방 접종을 합니다. 반면에 가축은 방목을 합니다. 떼로 방목을 하다 무리에서 낙오된 소들은 죽기도 합니다. 하지만 주인은 한두 마리의 소가 죽는다고 슬퍼하지 않습니다. 또한 소들마다 이름을 따로 짓지 않습니다. 이는 일일이 이름을 불러주기에는 수가 너무 많기 때문입니다. 쿠버네티스도 이와 비슷합니다. 쿠버네티스는 서버를 가축 관리하듯 대합니다. 서버마다 특별한 이름을 부여하지 않습니다. 이것은 각 서버마다 특정 역할이 정해져 있지 않는다는 것을 의미합니다. (예를 들어, CI/CD 서버, Web 서버, 모니터링 서버 등) 그렇기 때문에 한두개의 서버가 망가져도 큰 문제라 생각하지 않습니다. 손쉽게 다른 서버가 그 역할을 대체할 수 있기 때문입니다. 이러한 방식이 가능한 이유는 쿠버네티스에는 master 노드가 있어 쿠버네티스 위에서 돌아가는 모든 컨테이너 실행 정보를 관리하고 나머지 worker node들은 단순히 컨테이너를 실행하는 환경(container executor)으로만 사용하기 때문입니다. 그렇기 때문에 마스터가 죽지 않는 이상 나머지 서버들의 죽음은 크게 문제 되지 않습니다.

쿠버네티스의 이러한 특징 때문에 모델 학습 cluster로 사용하기에 딱 알맞다고 생각합니다. 모델 학습에 필요한 모든 소스코드 및 하이퍼 파라미터들은 마스터를 통해서만 정보를 주고 받고 나머지 서버들은 단순히 컨테이너화된 모델 학습 Job을 수행하는 executor로 활용할 수 있습니다. 이제는 더 이상 각 서버를 순회하면서 서버의 자원이 가용한지 확인하고 직접 모델 학습 스크립트를 실행 시킬 필요 없이 (애완동물) 학습에 사용할 서버를 전부 쿠버네티스 클러스터에 연결하고 필요한 작업들을 마스터에 맡기면 마스터가 알아서 서버 떼를 보살피게 됩니다. (가축 방식)
k8s를 이용한 ML 실행환경 구성
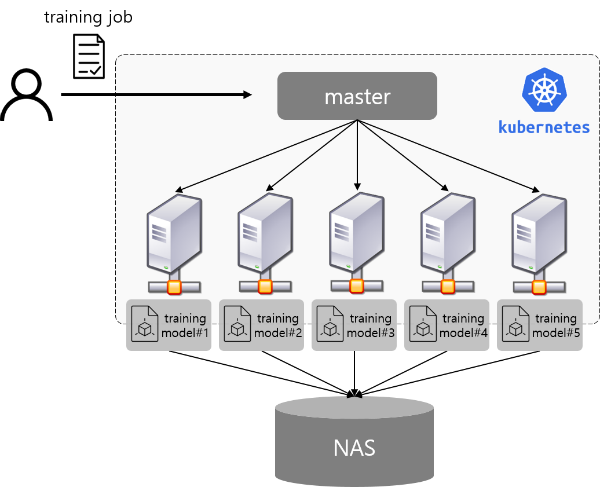
위의 그림에서 볼 수 있듯이 모든 학습 서버들은 쿠버네티스 마스터에 연결이 되어있습니다. 마스터는 논리적으로는 하나이나 가용성을 위해 보통 여러대의 서버를 묶어서 마스터를 만듭니다. 각 서버는 마스터와 통신하며 필요한 정보를 전달(node 상태 정보 등)하고 마스터로 부터 정보를 받습니다. (모델학습 실행 정보 등) 또한 각 학습 서버는 NFS로 연결이 되어 각 서버에서 실행한 결과를 한곳에 모이도록 구성되어 있습니다. 이를 통해 학습이 끝난 이후에 각 서버에 직접 접속하여 학습 결과 (모델 파일, 성능 지표 등)를 확인하는 것이 아니라 NAS 서버로 접속하여 한번에 확인할 수 있습니다.
k8s을 이용한 모델 학습 방식의 장점
이러한 방식으로 모델 학습을 하면 다음과 같은 장점들이 있습니다.
1. 매번 서버에 접속해서 스크립트를 실행하고 모니터링하는 작업이 사라집니다.
기존의 방법으로는 직접 학습 서버에 들어가서 실행 명령을 내려줘야 했습니다. 반면 쿠버네티스를 이용하면 모든 명령을 쿠버네티스 마스터로만 요청하면 되고 마스터에서 학습 프로세스를 관리합니다. 또한 학습이 어디까지 진행이 되었는지, 정상적으로 학습하고 있는지 학습 로그를 통해서 확인해야 하는데 쿠버네티스를 이용한다면 마스터를 통해 한 곳에서 각 학습 진행 상황을 모니터링할 수 있습니다.
2. 서버별 모델 실행 환경(라이브러리)을 동일하게 맞추는 작업이 사라집니다.
모델 학습 서버가 한 두개일 때는 직접 서버별로 학습에 필요한 Driver 및 라이브러리를 설치하면 됩니다. 설치 스크립트를 만든다면 어느 정도 규모의 서버도 조금은 귀찮지만 설치할 수 있습니다. 하지만 만약 모델 학습 서버가 10대, 20대가 넘어가기 시작하면 어떨까요? 거의 재앙에 가까운 상황일 것입니다. 오랜 노력 끝에 서버 환경을 맞추었다 하더라도 이후에 사용하는 라이브러리를 바꿔야 한다면 머리가 아파올 것입니다. 쿠버네티스를 사용하면 이러한 문제는 말끔히 해결됩니다. 쿠버네티스는 기본적으로 모든 프로세스를 컨테이너로 실행 시키기 때문에 업데이트할 이미지만 바꾸면 모든 서버에서 동일하게 수정할 수 있습니다. (사실 이것은 쿠버네티스가 해주는 것이 아니라 컨테이너를 사용하는 모든 시스템의 장점이죠)
3. 모델 실험이 편리해집니다.
새로운 모델을 실험할 때, 어느 서버에서 어떤 모델을 돌리는지 확인하는 일은 중요합니다. 여러 서버에서 다양한 모델 파라미터를 사용하게 되면 간혹 자신이 어디까지 실험을 완료하였는지, 앞으로 어떤 모델들을 테스트해야 하는지 헷갈릴때가 있습니다. 한두대의 서버에서 실험을 한다면 직접 수기로 기록해 둘 수 있을 것입니다. 서버 개수가 많아진다면 모델 실험 파라미터들을 디비로 저장하는 로직을 개발하여 관리할 수도 있습니다. 쿠버네티스를 이용한다면 조금은 더 편리하게 모델 실험을 할 수가 있습니다. 먼저 모델 실험 파라미터들을 (hyper-parameter set) 여러 서버에 분산하여 관리할 필요 없이 마스터 서버에서만 들고 있으면 됩니다. 실행한 모델 학습 정보는 자동으로 쿠버네티스의 저장소에 메타 정보로 남게 됩니다. 추가적인 노력 없이 모델 실행 정보를 관리하게 되는 것이죠.
4. 서버 자원 관리를 직접할 필요가 없어집니다.
기계학습에서 서버의 자원을 관리하는 일은 무척 수고스러운 일입니다. 새로운 학습을 실행 시키기 위해서 가장 먼저, 놀고 있는 서버를 찾아야 합니다. 그 다음, 찾은 서버 중에 학습 시키고자 하는 모델의 성격과 가장 적합한 서버를 골라야 합니다. (CPU bound, Memory bound, GPU usage등) 만약 현재 가용한 서버가 없다면 가장 빨리 끝날 것 같은 서버를 찾아 스케줄을 등록해야 할 것입니다. 쿠버네티스를 이용한다면 이 모든 것을 쿠버네티스가 관리해 줍니다. 쿠버네티스에는 자체 스케줄러가 있어, 컨테이너가 요청한 자원의 크기를 보고 적절하게 가용한 서버에 할당을 합니다. 또한 쿠버네티스의 매커니즘 중에 하나인 라벨(label)을 이용하여 사용자가 지정한 서버들 중에서 고르게 할 수도 있습니다. 예를 들어 CPU 성능이 중요한 학습인 경우 high-cpu 라는 라벨을 가진 서버 중에서 가용한 서버를 선택합니다.
5. 모델 학습 결과를 한곳에서 확인할 수 있습니다.
여러 서버에서 학습을 수행 하였을 때 또 다른 불편한 점을 들자면, 학습 결과물을 한 곳에서 확인하기 힘들다는 점입니다. 쿠버네티스를 이용하면 손쉽게 모델 파일을 원격 중앙 저장소에 모을 수 있습니다. 사실 원격 저장소를 연결하는 기술은 쿠버네티스가 제공하는 기능은 아닙니다. 단순히 NFS 프로토콜을 이용하여 원격 저장소에 마운트하는 것이 전부입니다. 하지만 쿠버네티스가 제공하는 Persistent Volume Claim (이하 pvc) 이라는 추상화된 쿠버네티스 volume 인터페이스를 사용하게 되면 구체적인 원격 저장소 정보를 알 필요 없이 손쉽게 컨테이너에 volume을 연결할 수 있습니다. 또한 pvc를 이용하면 사용자가 직접 NAS 서버에 저장소를 마운트할 필요 없이 쿠버네티스가 필요할 때마다 연결해 줍니다. 마지막으로 pvc는 개별적으로 이름을 가지는데 사용자는 해당 이름을 reference하여 전혀 다른 컨테이너에서 파일을 접근할 수도 있습니다.
6. 특정 서버에서 장애가 발생해도 크게 문제가 되지 않습니다.
간혹 기계학습 라이브러리를 업데이트하다 (NVIDIA driver, tensorflow 등) 환경 설정이 꼬이는 일이 발생하기도 합니다. 환경을 원복 시키는데 성공하면 다행이지만 복구가 제대로 되지 않는다면 많은 시간을 환경 설정하는데 허비하게 됩니다. 또 다른 케이스로, 어제까지만 해도 잘 돌았던 서버가 오늘 갑자기 접속이 안되거나 알 수 없는 에러를 내뱉는 경우도 있습니다. 그리고 꼭 이런 경우가 발생할 때, 빨리 학습 결과가 나와야하는 상황에 맞닥뜨리게 되죠. 모든 것을 처음부터 새로 설치할지, 발생한 장애를 어떻게든 해결해야 할지 고민이 되기 시작합니다. 쿠버네티스를 이용한다면 이런 상황이 발생해도 크게 걱정하지 않아도 됩니다. 모델 학습에 관련한 모든 실행 정보는 쿠버네티스 마스터에서 관리하기 때문에 장애가 발생한 노드를 제거하고 바로 다른 노드에서 학습을 시작하면 됩니다.
7. 한개 프로세스의 문제로 서버 전체에 장애가 발생하는 것을 방지해 줍니다.
여러 모델을 한 서버에서 학습하는 경우, 문제가 되는 한개의 학습 프로세스로 인해 서버 전체가 영향을 받는 경우가 있습니다. 예를 들어, 한개의 프로세스가 모든 GPU 자원을 점유한다던지 서버의 모든 메모리를 혼자서 차지하는 경우입니다. 이러한 문제는 엄격한 코드 리뷰를 통해 코드 레벨에서 문제가 되는 부분을 걸러낼 수 있지만 매번 엄격한 코드 리뷰를 하는 것은 현실적으로 힘들고 리뷰를 한 경우에도 미처 찾아내지 못한 코드가 문제를 일으킬 수 있습니다. 쿠버네티스를 통해 모델 학습을 실행하면 각 컨테이너마다 리소스 제한을 할 수 있기 때문에 한개 프로세스의 문제로 서버 전체가 망가지는 것을 방지해 줍니다. 이를 통해 조금 더 안정적으로 모델 학습 운영을 할 수 있습니다.
8. On-premise / Cloud 서버 구분 없이 통합하여 관리할 수 있습니다.
학습 서버가 모두 클라우드 서비스 위에 있는 경우에는 크게 상관 없지만 보안 문제로, 또는 가격 효율적인 측면에서 자체 서버를 가지고 직접 운영하는 경우도 있습니다. 그런 경우에도 동일한 운영 환경에서 작업을 하고 싶지만, Cloud / On-premise 환경의 제약 사항 때문에, 혹은 Legacy 시스템에 대한 종속성 때문에 별개의 운영 환경을 가져가게 됩니다. (소스 관리, CI / CD 서버, OS 종류 및 버젼 등) 이것은 곧 관리의복잡성을 증가 시킵니다. 쿠버네티스를 이용한다면 모든 서버의 환경을 (비교적) 동일하게 통일 시킬 수 있습니다. On-premise 서버든 Cloud 서버든 쿠버네티스 마스터와만 통신할 수 있다면 어떤 서버든 구분 없이 쿠버네티스 Worker Node로 활용할 수 있습니다. 이를 통해 평상시에는 On-premise 서버를 이용하여 학습을 진행하고 서버 자원이 갑자기 많이 필요할 때 Cloud 서버를 마스터로 붙여서 elastic하게 학습을 추가 실행할 수 있습니다.
쿠버네티스만의 장점
사실 위에서 설명드린 장점들은 쿠버네티스만의 장점은 아닙니다. AWS Batch, Docker Swarm, Apache Mesos와 같은 다른 도커 오케스트레이션 툴들을 사용해도 이와 비슷한 이점들을 누릴 수 있습니다. 그렇다면 쿠버네티스만의 장점은 무엇일까요?
활발한 오픈소스 생태계
먼저 AWS Batch 서비스는 오픈소스가 아니기 때문에 AWS에서 기능을 추가하지 않는 한 원하는 기능을 추가하기 어렵습니다. 그럼 나머지 서비스들과 비교해볼까요? 2019년 1월 기준으로 쿠버네티스와 다른 서비스들간의 깃허브 commit, star, fork 개수 등을 비교해 보았습니다.
| Service | Commit | Star | Fork | Releases |
|---|---|---|---|---|
| Kubernetes | 73,239 | 46,464 | 16,162 | 466 |
| Apache Mesos | 16,439 | 3,997 | 1,554 | 235 |
| Docker Swarm | 3,536 | 5,385 | 1,086 | 57 |
위에 표에서 확인할 수 있듯이, 쿠버네티스의 생태계가 압도적으로 활발하다는 것을 볼 수 있습니다. 이것은 그 만큼 문제가 생겼을 때, 더 빠르고 손쉽게 도움을 받을 수 있다는 것을 말합니다. 또한 새로운 feature들이 빠른 속도로 추가되고 더 많은 검증을 거친다는 것을 의미합니다.
확장 가능한 API
쿠버네티스는 기본적으로 확장 가능한 구조로 설계되었습니다. 쿠버네티스에서는 사용자가 Custom Resource를 선언하여 쿠버네티스에서 제공하는 동일한 API로 새로운 기능들을 추가할 수 있습니다. 이러한 구조는 쿠버네티스가 빠르게 발전할 수 있는 밑거름이 됩니다. 사용자가 정의한 새로운 기능을 손쉽게 추가하여 필요에 맞게 사용하고 다른 사용자들도 쉽게 가져다 쓸수 있습니다. 만약 해당 기능이 많은 사용자들로부터 사용된다면 정식 Core API로도 추가될 수 있을 것입니다.
플랫폼 종속성 감소
쿠버네티스를 이용하면 어떤 클라우드 플랫폼이든 상관 없이 동일한 환경에서 운영을 할 수 있습니다. Cloud Provider가 AWS든, Azure든, GCE든 상관 없이 쿠버네티스를 설치할 수만 있다면 플랫폼에 대한 종속성을 줄일 수 있습니다. 또한 클라우드 플랫폼 뿐만 아니라 on-premise 서버를 이용하여 cluster를 구성할 수도 있습니다. 현실적으로는 플랫폼에 대한 종속성을 완벽히 없앨 수는 없습니다. Storage, Network와 같이 cloud provider에서 제공해주는 리소스들이 있기 때문입니다. 그럼에도 불구하고 쿠버네티스를 이용하게 되면 특정 클라우드 벤더에 대한 종속성을 비교적 많이 낮출 수 있습니다.
지금까지 쿠버네티스를 이용하여 모델을 학습 시키면 어떤 장점들이 있는지 얘기해보았습니다. 꽤나 매력적인 플랫폼으로 느껴지지 않나요? 저는 쿠버네티스를 알게 된 후, 이전과 비교할 수 없을 만큼 편리하게 다량의 모델들을 여러 서버에서 효율적으로 학습할 수 있었습니다. 그럼 다음 포스트에서는 실제로 어떻게 쿠버네티스를 사용하는지에 대해 설명하겠습니다.
Updated: 발표
해당 내용으로 AWS Summit 2019 Seoul에서 발표를 하였습니다. 참고하시기 바랍니다.