kubernetes와 MLOps #2
15 min read
이번 포스트에서는 쿠버네티스 환경을 구축해보고 직접 여러 개의 모델을 훈련시켜 보아 기존 방법에 비해 어떤 부분들이 더 좋은지 알아보도록 하겠습니다.
쿠버네티스의 MLOps는 다음과 같은 시리즈로 구성되어 있습니다.
- 쿠버네티스와 MLOps#1
- 쿠버네티스와 MLOps#2
- 쿠버네티스와 MLOps#3
- 쿠버네티스와 MLOps#4
kubernetes 환경 구축
쿠버네티스 클러스터를 직접 구축하는 일은 그리 간단하지 않습니다. 저는 AWS 클라우드 상에서 클러스터를 구축하는 방법을 소개해 드리겠습니다. 크게 3가지 방법이 있습니다.
1. CloudFormation 이용
heptio 라는 회사에서 손쉽게 쿠버네티스 클러스터를 구축할 수 있게 만든 cloudformation 탬플릿입니다. 쿠버네티스를 처음 접하시는 분이라면 어떤 방식으로 클러스터가 구성되는지 파악할 수 있는 좋은 자료가 됩니다. 다만 단일 마스터로 구성이 되오니 프로덕션 레벨에서 사용하는 것을 권장하지 않습니다. 이번 시간에는 해당 방법을 이용해서 클러스터를 만들어 볼 예정입니다.
2. kops 이용
Kubernetes OPerationS의 약자로 클라우드 상에서 쉽게 프로덕션 레벨의 클러스터를 구축할 수 있게 도와주는 오픈소스 tool입니다. kops는 특정 클라우드 벤더와 상관 없이 모든 클라우드 서비스에서 사용되는 것을 지향하지만 사실상 AWS에 최적화 되어 있습니다. 쿠버네티스 정식 프로젝트 중 하나이며 AWS가 공식적으로 kops 프로젝트를 지원하고 있습니다. kops는 직접 여러 AWS 리소스를 생성하기 때문에 Route53, S3, EC2, VPC 등 많은 권한을 요구하기도 합니다. AWS 위에서 프로덕션 레벨로 쿠버네티스를 구축하길 원하신다면 kops가 괜찮은 선택이 될 수 있습니다.
3. eksctl 이용
AWS에서 제공하는 쿠버네티스 managed 서비스인 Amazon EKS를 쉽게 컨트롤할 수 있는 CLI 툴입니다. 위 2개 방법과는 다르게 EC2위에 마스터 노드를 직접 설치하는 형태가 아닌 AWS에서 제공해주는 마스터를 가져다 사용하는 방법입니다. 워커 노드는 똑같이 EC2 서버를 이용합니다. 마스터 노드를 AWS에서 관리해주기 때문에 관리 포인트가 줄어든다는 장점이 있습니다. 대신 AWS라는 특정 클라우드 벤더에 완전히 락인되게 됩니다. 재밌는 점은 eksctl 툴 자체는 AWS에서 만든 것이 아니라 쿠버네티스 network provider 중 하나인 Weave Net을 만든 회사에서 eksctl을 만들었습니다. AWS에서 제공하는 CLI 툴은 여느 다른 서비스와 마찬가지로 aws cli 를 이용하여 EKS를 컨트롤해야 하는데 그리 편리하진 않았습니다. (개인적 의견입니다.) 그렇기 때문에 다른 회사에서 직접 eksctl이라는 툴을 만들지 않았을까 생각합니다. 결과적으로 AWS에서도 eksctl 툴 개발에 참여하기 시작하였고 Amazon sample 코드에서도 eksctl을 활용하여 튜토리얼을 진행합니다. 개인적으로 Amazon이 대단하다고 생각하는 것이, 본인들이 굳이 노력을 안해도 다른 회사가 먼저 나서서 자기네 회사의 제품을 편리하게 사용할 수 있게끔 만드는 점이 참 흥미롭습니다.
Heptio CloudFormation Launch
- 먼저 아래의 주소로 들어가서
배포방법 - 새 VPC에 배포을 클릭합니다.
https://aws.amazon.com/quickstart/architecture/heptio-kubernetes/
-
기본적으로 us-west-2 리전으로 설정되어 있습니다. 본인의 상황에 맞는 리전을 선택하시기 바랍니다. 저 같은 경우는 서울 (ap-northeast-2) 리전을 선택하도록 하겠습니다.
다음을 클릭 -
빈칸에 아래와 같이 정보를 입력하시기 바랍니다.
- Stack Name: CloudFormation stack 이름, 예제로
k8s-stack이라 입력 - Availability Zone선택: ap-northeast-2a
- Admin Ingress Location: 0.0.0.0/0
- SSH Key: 본인이 사용하고 있는 pem key
- Node Capacity: 테스트할 worker node 개수, 기본 2개
- 나머지는 default 값으로 설정
- 끝까지
다음버튼 클릭 - 마지막 기능에 리소스 권한 승인, 최종적으로
승인클릭
승인 버튼을 누르게 되면 CloudFormation stack이 생성되기 시작합니다. CloudFormation dashboard에 k8s-stack이라는 이름의 stack이 CREATE IN PROGESS 중이라고 표시됩니다.
최종적으로 아래와 같은 클러스터를 구성되게 됩니다.
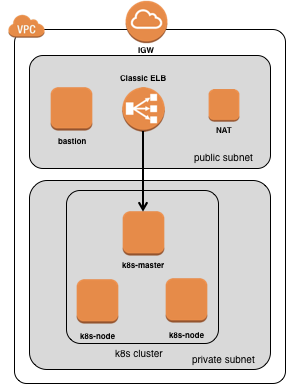
클러스터 생성이 완료되면 bastion 서버에 들어가서 다음과 같은 명령을 통하여 master에 들어있는 kube-config 파일을 bastion 서버로 옮깁니다. (bastion 서버에서 kubectl 명령을 날리기 위해)
mkdir ~/.kube
scp -i PEM_KEY.pem ubuntu@$MASTER_IP:~/.kube/config ~/.kube/config
그럼 다음 아래의 명령어를 실행하여 쿠버네티스 클러스터가 제대로 생성되었는지 확인합니다.
kubectl get node
NAME STATUS ROLES AGE VERSION
ip-10-0-26-143.ap-northeast-2.compute.internal Ready master 1d v1.12.1
ip-10-0-14-9.ap-northeast-2.compute.internal Ready <none> 1d v1.12.1
ip-10-0-3-193.ap-northeast-2.compute.internal Ready <none> 1d v1.12.1
모든 노드의 status가 Ready 상태로 나온다면 문제 없이 쿠버네티스 클러스터 생성이 완료되었다고 보실 수 있습니다. 혹시 NotReady가 뜬다면 조금 더 기다리시길 바랍니다. 충분한 시간이 지났는데도 NotReady 상태로 있다면
kubectl get pod -nkube-system
이라는 명령어를 입력하여 나오는 결과 중에 이상있는 Pod는 없는지 확인 바랍니다.
그럼 이제 실제로 모델 학습 훈련을 해볼까요?
첫 Job 실행
쿠버네티스에는 Job 이라는 종류의 리소스가 있습니다. 데몬 형태로 계속 떠 있는 프로세스가 아닌 한번 실행하고 완료되는 용도로 많이 사용합니다.
먼저 다음과 같은 간단한 mnist 데이터를 학습하는 모델이 있다고 생각해 봅시다.
# train.py
import os, sys, json
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop
#####################
# parameters
#####################
epochs = int(sys.argv[1])
activate = sys.argv[2]
dropout = float(sys.argv[3])
print(sys.argv)
#####################
batch_size = 128
num_classes = 10
hidden = 512
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Dense(hidden, activation='relu', input_shape=(784,)))
model.add(Dropout(dropout))
model.add(Dense(hidden, activation='relu'))
model.add(Dropout(dropout))
model.add(Dense(num_classes, activation=activate))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(),metrics=['accuracy'])
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
그리고 난 후 도커 이미지를 만들어 줍니다.
FROM python:3.6.8-stretch
RUN pip install tensorflow==1.5
RUN pip install keras==2.0.8
RUN pip install h5py==2.7.1
ADD train.py .
docker build . -t $REPO/k8s-ml:model01
마지막으로 다음과 같이 YAML 파일을 작성합니다.
# exp01-example.yaml
apiVersion: batch/v1
kind: Job # 리소스 종류
metadata:
name: exp01-example # 이름
spec:
template:
spec:
containers:
- name: ml
image: $REPO/k8s-ml:model01 # 이미지 주소
command: ["python", "train.py"] # 실행 방법
args: ['20', 'softmax', '0.5'] # 사용할 args
resources:
limits: # 리소스 제한
cpu: "1" # cpu core
memory: "5Gi" # mem size
restartPolicy: Never
backoffLimit: 0
쿠버네티스의 Job 이라는 리소스 타입을 통해 어떤 이미지를 어떤 방식으로, 어느 정도의 리소스를 이용하여 실행할지 정하였습니다. 이제 해당 YAML 파일을 쿠버네티스에 넘겨서 실행하도록 하겠습니다.
쿠버네티스에서는 사용자 인터페이스로 kubectl 이라는 커멘드 툴을 이용하여 클러스터를 컨트롤합니다. 다음 명령을 통해 실행해 보겠습니다.
kubectl apply -f exp01-example.yaml
방금 실행한 Job이 쿠버네티스에 잘 제출되었는지 다음 명령을 통해 확인하실 수 있습니다.
kubectl get job
NAME DESIRED SUCCESSFUL AGE
exp01-example 1 0 3s
쿠버네티스는 모든 container의 실행을 Pod라는 리소스를 통하여 실행 시킵니다. Job도 마찬가지로 Pod를 통하여 실제 작업을 진행하게 됩니다. 그렇기 때문에 Pod 정보를 이용하여 현재 잡의 상태를 파악합니다. 혹시 Pod에 대해 더 알아보고 싶으시다면 쿠버네티스 공식 홈페이지 Pods 를 참고하시기 바랍니다. 그럼 현재 돌고 있는 Pod를 확인해 보겠습니다.
kubectl get pod
NAME READY STATUS RESTARTS AGE
exp01-example-mnpbz 0/1 ContainerCreating 0 29s
현재는 Container가 생성되고 있는 중입니다. 조금 기다렸다가 다시 현재 pod 상태를 받아왔을때 Running 상태로 바뀌었다면 정상적으로 Pod가 실행하고 있다는 것을 뜻합니다. 간혹 Pending 상태로 계속해서 남아 있는 경우가 있을 수도 있는데 그럴 경우 쿠버네티스의 describe 명령어를 통해 Pod의 상태를 확인해 보시기 바랍니다.
kubectl describe pod exp01-example-mnpbz
Name: exp01-example-mnpbz
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: <none>
Status: Pending
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 57s (x22 over 16m) default-scheduler no nodes available to schedule pods
워커 노드에 문제가 있거나 서버의 스펙이 너무 낮아서 제출한 Job이 실행되지 못할 수도 있습니다. 그럴 경우 아래의 Events 부분을 확인하여 어떤 이유 때문에 실행이 되지 않는지 확인해 보시기 바랍니다.
이제 실행하고 있는 컨테이너에 붙어서 로그 기록을 확인해 보겠습니다.
kubectl logs -f exp01-example-mnpbz # docker logs
# or
kubectl attach exp01-example-mnpbz # docker attach
다음 명령을 입력하면 콘솔창에서 실제 학습하고 있는 로그를 확인해 보실 수 있습니다.
kubectl 툴 관련하여 조금 더 자세히 알아보고 싶다면 kubectl cheat sheet 한번 참고하시기 바랍니다. 유용한 명령어들이 상세히 설명되어 있습니다.
이처럼 쿠버네티스를 이용하여 직접 서버에 들어가지 않고도 kubectl이란 툴을 이용하여 원격에서 기계학습 Job을 실행하고 모니터링을 하거나 실행 중인 Job을 중단할 수도 있습니다.
지금까진 단일 Job에 대해서 학습을 실행해보며 쿠버네티스가 어떻게 동작하는지 알아봤습니다. 이번에는 파이썬 스크립트를 이용하여 동시에 여러개의 기계학습 모델을 실행해 보고 쿠버네티스가 어떻게 동작하는지 알아보도록 하겠습니다.
Multi 모델 실험 실행
여러개의 기계학습 모델을 동시에 실행하기 위해 간단한 파이썬 스크립트를 작성하겠습니다.
# run-experiments.py
import os
import yaml
JOB_TEMPLATE = \
"""cat << EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: exp%02d
spec:
template:
spec:
containers:
- name: ml
image: %s
command: ["python", "train.py"]
args: ['%s', '%s', '%s']
resources:
limits:
cpu: "1"
memory: "6Gi"
restartPolicy: Never
EOF
"""
with open('experiments.yaml') as f:
experiments = yaml.load(f)
count = 1
for exp in experiments:
for idx, arg in enumerate(exp['args']):
run_job_cmd = JOB_TEMPLATE % tuple([count, exp['script'], *arg])
######################
# Run exp
######################
os.system(run_job_cmd)
count += 1
단일 잡 실행한 YAML파일과 거의 비슷합니다. 단지 모델 실험 정보가 저장된 experiments.yaml파일로 부터 정보를 얻어와서 하나씩 쿠버네티스에게 던져주는 것이 전부 입니다.
모델 실험 정보를 모아둔 experiments.yaml 파일은 다음과 같습니다.
# experiments.yaml
- script: $REPO/k8s-ml:model01
args:
- [10, softmax, 0.2]
- [10, relu, 0.3]
- [10, tanh, 0.4]
- [10, linear, 0.5]
- [10, selu, 0.6]
- [10, elu, 0.7]
- [10, sigmoid, 0.8]
- [10, softsign, 0.9]
- script: $REPO/k8s-ml:model02
args:
- [10, softmax, 0.2]
- [10, relu, 0.3]
- [10, tanh, 0.4]
- [10, linear, 0.5]
- [10, selu, 0.6]
- [10, elu, 0.7]
- [10, sigmoid, 0.8]
- [10, softsign, 0.9]
- script: $REPO/k8s-ml:model03
args:
- [10, softmax, 0.2]
- [10, relu, 0.3]
- [10, tanh, 0.4]
- [10, linear, 0.5]
- [10, selu, 0.6]
- [10, elu, 0.7]
- [10, sigmoid, 0.8]
- [10, softsign, 0.9]
ubuntu@ip-172-31-22-76:~$ python run-experiments.py
job.batch/exp01 created
job.batch/exp02 created
job.batch/exp03 created
...
job.batch/exp23 created
job.batch/exp24 created
ubuntu@ip-172-31-22-76:~$ kubectl get pod
NAME READY STATUS RESTARTS AGE
exp01-vszdr 1/1 Running 0 8s
exp02-dcwtg 1/1 Running 0 8s
exp03-ngjws 1/1 Running 0 8s
exp04-65bk4 1/1 Running 0 7s
exp05-cntcm 0/1 Pending 0 7s
exp06-xvhft 0/1 Pending 0 7s
...
exp23-khvfg 0/1 Pending 0 3s
exp24-dk6bk 0/1 Pending 0 3s
kubectl get pod를 실행해보면 지금까지 쿠버네티스에 제출된 학습들이 나옵니다. 그중에서 몇몇 Pod는 실행 중이고 나머지는 Pending 상태에 있습니다. 쿠버네티스에 리소스를 설정하면 쿠버네티스가 요청한 리소스와 현재 Node에 남아있는 리소스를 비교하여 부족하다고 판단하면 더 이상 컨테이너를 실행 시키지 않고 Pending 상태로 둡니다. 이를 통해 굳이 분석가가 일일이 가용한 서버를 찾을 필요 없이 쿠버네티스에 맡기면 쿠버네티스가 리소스 상황에 맞춰서 스케줄링하게 됩니다. 정말 편리하지 않나요?
또한 여러개의 모델을 여러 서버에서 실험을 돌려도 각 서버에 들어가서 확인해 볼 필요 없이 kubectl 툴을 통하여 여기 저기의 Job들을 확인해 볼 수 있습니다.
kubectl attach exp02-dcwtg
kubectl attach exp04-65bk4
Out of Memory 발생 실험
이번에는 고의적으로 OOM 상황을 발생 시켜 예상한대로 서버 전체에 영향을 미치지 않고 해당 pod만 작동을 중단 시키는지 확인해 보겠습니다.
먼저 oom을 발생시키는 파일을 먼저 작성해 보겠습니다.
import os, sys, json, time
from tqdm import tqdm
#######################
# parameters
#######################
epochs = int(sys.argv[1])
activate = sys.argv[2]
dropout = float(sys.argv[3])
print(sys.argv)
#######################
# Out of memory Error
#######################
arr = []
pbar = tqdm(range(1000))
pbar.set_description("Training")
for i in pbar:
a = bytearray(12000000)
time.sleep(0.07)
arr.append(a)
해당 파일을 $REPO/k8s-ml:oom 이라는 이름으로 이미지를 빌드하겠습니다.
YAML 파일 자체는 기존의 형식과 거의 똑같습니다. 단지 실행할 이미지만 oom을 발생 시키는 스크립트로 교체하였습니다.
# oom.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: exp-oom
spec:
template:
spec:
containers:
- name: ml
image: $REPO/k8s-ml:oom
imagePullPolicy: Always
command: ["python", "-u", "train-oom.py"]
args: ['20', 'softmax', '0.5']
resources:
limits:
cpu: "1"
memory: "5Gi"
restartPolicy: Never
backoffLimit: 0
이제 oom 스크립트를 실행 시켜 보겠습니다.
kubectl apply -f oom.yaml
실행 이후에 Pod의 상태를 파악하는 명령어에 watch를 걸어서 OOM이 발생하는 Pod의 상태가 어떻게 변하는지 알아보겠습니다.
watch kubectl get pod -o wide
Every 2.0s: kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
exp-oom-vh7lp 1/1 Running 0 11d 192.168.165.54 ip-192-168-160-71.ap-northeast-2.compute.internal <none>
실제 Pod가 실행되고 있는 Node로 들어가서 nmon 과 같은 리소스 모니터링 툴을 이용하여 서버의 리소스 사용률을 확인해 보실 수도 있습니다.
kubectl attach exp-oom-vh7lp
명령으로 직접 컨테이너로 들어가서 로그를 확인해 보시면 어느 정도 진행이 되다가 컨테이너가 죽는 것을 볼수 있습니다. 이때 Pod의 STATUS를 확인해 보면 OOMKilled으로 상태가 바뀐 것을 확인하실 수 있습니다. 이것은 문제의 컨테이너가 서버의 모든 자원을 다 소진하여 죽은 것이 아니라 미리 정의된 리소스까지만 사용하다가 죽은 것입니다. 직접 Node의 리소스 상황을 모니터링해 보시면 서버의 메모리가 100% 사용하기 전에 컨테이너가 죽었는 것을 확인하실 수 있습니다.
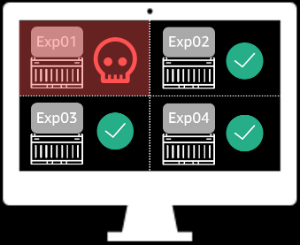 이렇게 쿠버네티스를 이용하면 문제가 되는 한두개의 Job이 다른 기계학습의 실험을 방해하는 상황을 쉽게 막을 수 있습니다. 쿠버네티스만 잘 이용해도 정말 편리하게 모델을 학습 시킬 수 있어 보입니다.
이렇게 쿠버네티스를 이용하면 문제가 되는 한두개의 Job이 다른 기계학습의 실험을 방해하는 상황을 쉽게 막을 수 있습니다. 쿠버네티스만 잘 이용해도 정말 편리하게 모델을 학습 시킬 수 있어 보입니다.
지금까지 직접 Job을 실행해보며 쿠버네티스가 어떻게 동작하는지 알아봤습니다. 다음 시간에는 helm 이라는 패키지 매니저를 통하여 몇가지 쿠버네티스 controller를 설치하여 쿠버네티스 리소스 모니터링(metrics-server), AWS EFS 저장소 사용, auto scaling 작업들을 진행해보겠습니다.