
JupyterFlow - Better way to scale your ML job
9 min read
Introducing JupyterFlow, a better way to scale your ML job on Kubernetes.
I read this article “Data Scientists Don’t Care About Kubernetes” and I totally agree with it. Using Kubernetes for training ML models is a great idea but it is not quite easy to use it, especially for Data Scientist. For those who haven’t read the article, it can be summed up as follows(I recommend you to read the origial article though):
- Kubernetes is a great tool for running ML model on multiple training server efficiently. There are many attempts to utilze Kubernetes in ML field(for example, Kubeflow).
- However, it is not quite friendly to use for data scientist because of Kubernetes’s steep learning curve. Kubernetes is made for software engineer, not data scientist.
- To make data scientist focus only on building ML model thoroughly, it is important to have a abstract ML tool that data scientist can easily utilze Kubernetes without knowing of it.
I also experienced the same problem and thought about a better way to run ML model on Kubernetes. Finally I came up with some idea, which might not be the best solution though, I feel it would fix the problem.
Reason why Kubernetes based ML tools is hard to use.
As the article pointed out, the reason why Kubernetes based ML tools such as Kubeflow is hard to use is two fold.
- Data scientist needs to containerize their ML code.
- Data scientist needs to write k8s manifest file(YAML).
Let’s first take a look at containerization problem. Writing one’s ML model into source code is not hard for data scientist. The problem starts when they want to deploy one’s code on Kubernetes for training or serving. To deploy a program onto Kubernetes, containerization needs to be done first. This process is for software engineer not for data scientist. It might be unnatural for data scientist. Writing Kubernetes manifest file is also burdensome. Data scientist needs to deal with detailed k8s concepts. There are some solutions for this problem.
Solutions
1. Requesting engineer’s support.
Software engineers can support containerizing data scientist’s ML code for them. It is the simplest and fastest solution. However each developer has their own work, so this method can not be sustainable and it will drag down the whole model development cycle. Moreover unlike software development, model development process has more fine-grained incremental steps. For example, you write your code and run right away for validation. It could easily be exhausting if there is a strong dependency between two group everytime the code changes.
2. Learning how to use k8s.
As the aforementioned article states, everyone can not be a unicorn. Also, according to single-responsibility principle, it might be cost-efficient to focus on each of what they are good at(Actually, this principle is for programming, not for person though).
3. Providing abstract ML tool.
The Determined AI’s approach is to provide an abstract way to run on Kubernetes through ML tool. They introduced their own product.
My proposal
I agree with Determined AI’s suggestion and I have a similar approach but slightly different. What do you say if I can to this:
Removing containerization process from Data Scientist
The biggest pain point for data scientist to use Kubernetes based ML tool is containerizing their ML code. Then what if I could remove this step?

You might be thinking, What on earth is he talking about? In Kubernetes website first page, it states Kubernetes as “Production-Grade Container Orchestration”. How could you remove containerization step in the middle of utilizing Kubernetes as a ML platform?
I think, “it is possible”. Yet on one condition.
Developing model inside the container in the first place
Let me explain in more detail. Current problem is that data scientis should build their container by themself. Then, what if we make a container first and provide that containerized environment to data scientist? If data scientist writes their code inside the container in the first place, it would be much easier to run this code on Kubernetes. But there are some problems.
- How can we provide a containerized environment easily to data scientist?
- How can we deliver the ML code written inside a container to Kubernetes?
JupyterHub on Kubernetes
The solution for the first problem is JupyterHub. JupyterHub is a platform that each user can launch their own jupyter notebook server respectively. There are many methods to setup JupyterHub but my approach only works on JupyterHub on Kubernetes. From now on, I wil refer to JupyterHub as JupyterHub on Kubernetes.
The architecture of JupyterHub is following.
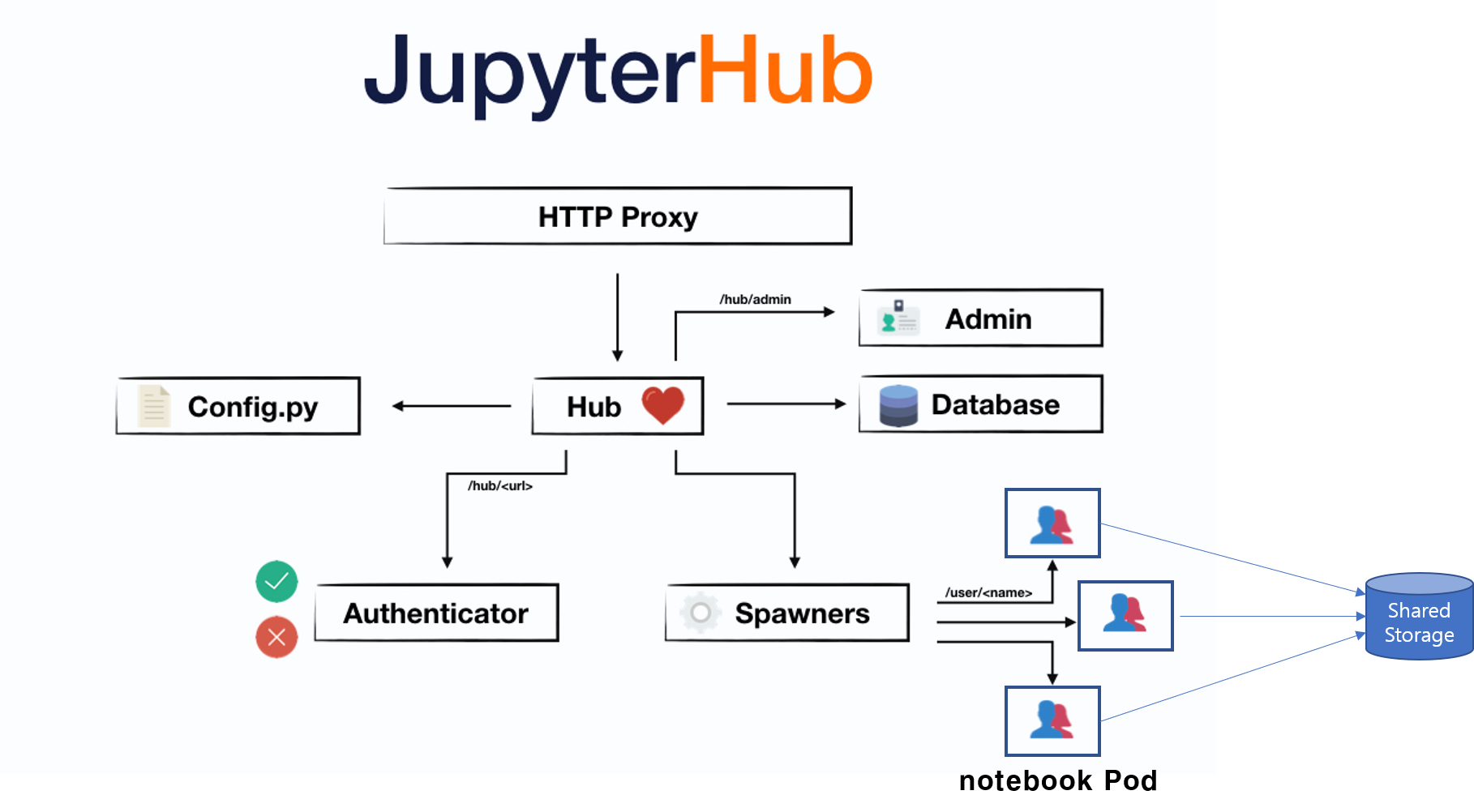
It might look complicated but you only need to focus on Spawners and Pod. Everytime users launch their notebook, Spawners spawns a new Pod on Kubernetes. Each Pod represents jupyter notebook for each user. Each user writes their code in their notebook. Each Pod is connected to a shared storage, such as NAS(Network Attached Storage) server so every written code gathers to one place.
Pod== Jupyter notebook server- ML code location == Shared Storage(NAS server)
Data scientist can write their ML code on this containerized Jupyter server.
Delivering the code
Next, we need to solve the second problem. Even if we manage to write a code inside a container, we still need to deliver that code to Kubernetes to run a job. Do we have to re-build an image from Jupyter notebook server? Not at all. There is a way to deliver the ML code without re-building the container.
Using Shared Storage simply solves the problem. Because the code, data scientist wrote, gets stored in Shared Storage(NAS), you only need to connect that same Shared Storage volume when you run a job on Kubernetes.
Let’s take a look at the basics of running ML code. There are three main parts. “Execution environment, ML code, Model hyper-parameter”.
venv/bin/python train.py epoch=10 dropout=0.5
- Execution Env:
virtualenvpython environment(venv) - ML code:
train.py - Model H.P.:
epoch=10 dropout=0.5
If we could send these information to Kubernetes, data scientist can use k8s without any hard works. Suprisingly, you can get all these information from JupyterHub. Using the metadata of jupyter notebook Pod is the key.
- Execution Env: jupyter notebook container image (
Pod.spec.containers.image) - ML code: ML code located on Shared volume (
Pod.spec.volumes) - Model H.P.: parameter passed to ML tool
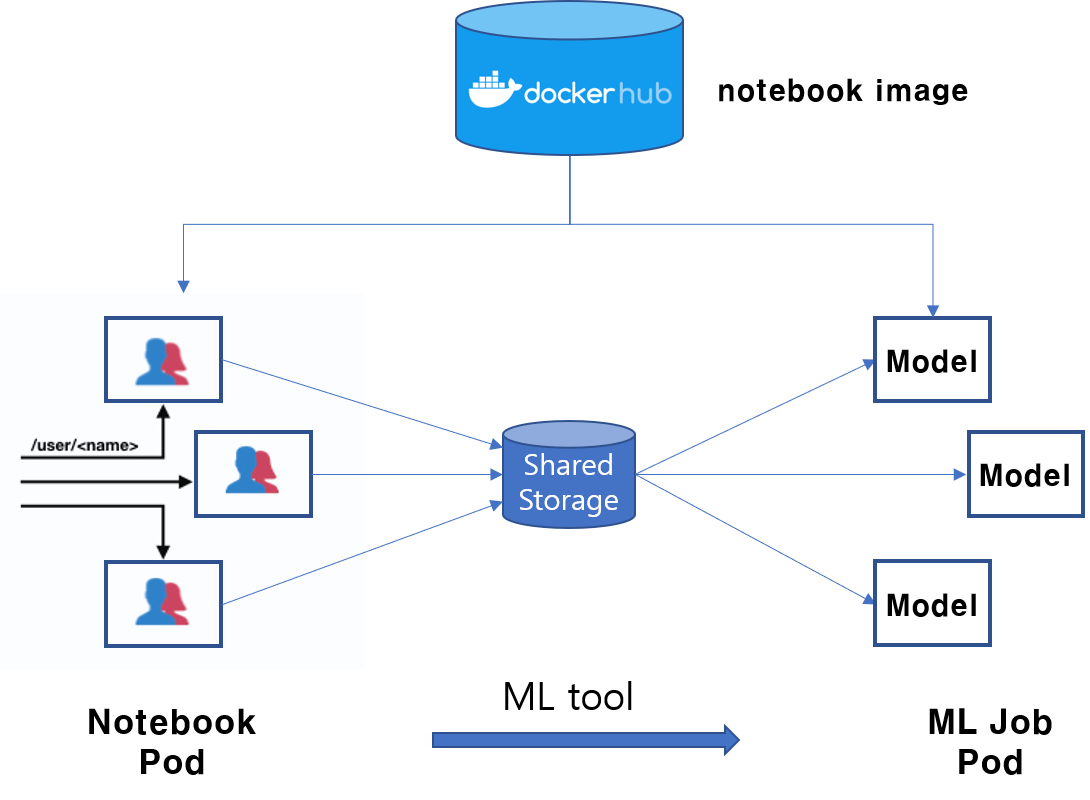
What if there is a ML tool which is smart enough to find the container image, ML code and H.P. from jupyter notebook Pod and constructs a Kubernetes manifest file and send it to k8s master, then data scientist can run their ML code without containerization job & writing k8s manifest.
Is there really such a tool that can do this?
JupyterFlow
Introducing JupyterFlow
Introducing JupyterFlow (https://jupyterflow.com), a better way to scale your ML job on Kubernetes.

JupyterFlow is an Machine Learning CLI tool installed in jupyter notebook which helps you run ML code on Kubernetes without containerization & manifest.
For example, write your code(hello.py, world.py) as you wish, run your code with jupyterflow CLI and JupyterFlow will create a ML pipeline for you.
# write code. hello.py & wrold.py
echo "print('hello')" > hello.py
echo "print('world')" > world.py
# install jupyterflow.
pip install jupyterflow
# in jupyterflow `>>` directive expresses container dependencies similar to Airflow.
jupyterflow run -c "python hello.py >> python world.py"
The result looks like below:
Think of model development cycle without JupyterFlow:
- Data scientist writes their code.
- Containerize their code.
- Write k8s manifest file.
- Submit job through
kubectlCLI.

On the otherhand, model development cycle with JupyterFlow becomes piece of cake:
- Spawn jupyter notebook.
- Write ML code on notebook.
- Run your ML pipeline through
jupyterflow.

Then JupyterFlow will do the rest. How about it, isn’t it simple?
JupyterFlow Architecture
This is the architecture of JupyterFlow.
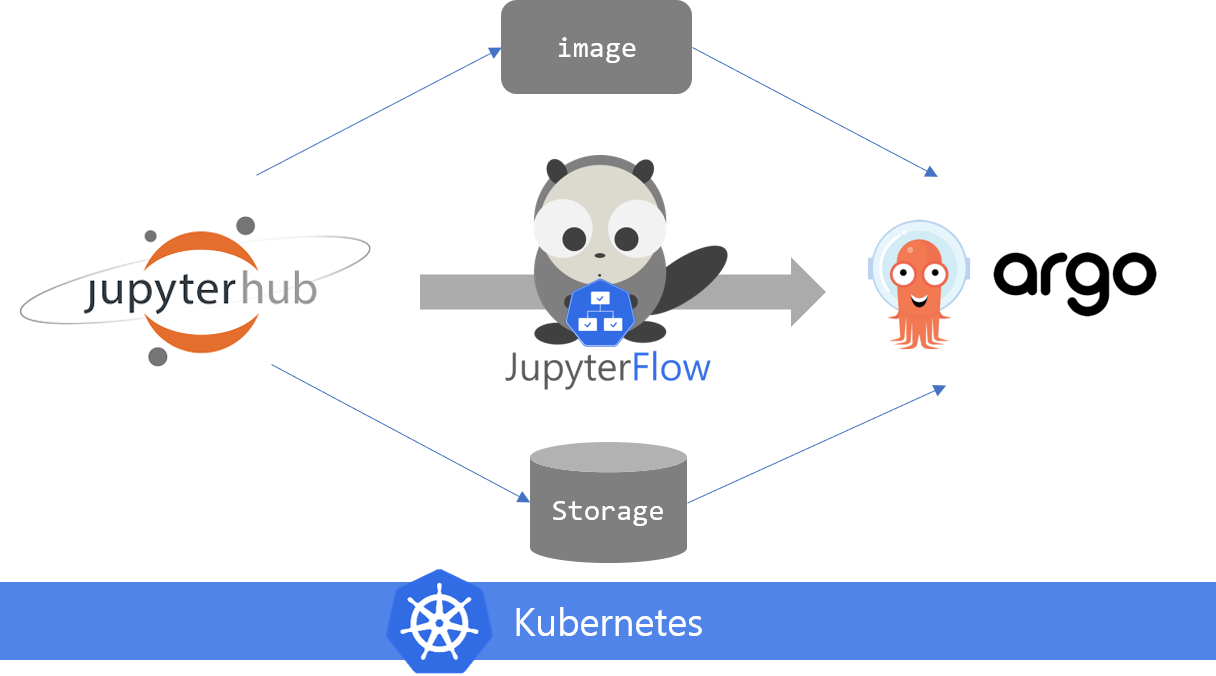
To use JupyterFlow, you need two main components. JupyterHub and Argo Workflow. Argo Workflow is a custom controller which let user to define dependencies between containers to make a workflow. You can use a new CRD(CustomResourceDefinition) called Workflow when you install Argo Workflow. Simple Workflow example looks like this:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
resources:
limits:
memory: 32Mi
cpu: 100m
If you write this manifest, custom controller(argo workflow controller) reads it and creates containers sequentially based on the instruction. Users can check the result from Argo Web UI (argo-ui) provided by Argo Workflow.
JupyterFlow’s role is to fetch jupyter notebook’s meta data(image, volume) and H.P. from user, and write Workflow manifest similar to this example. Then Kubernetes will run the ML pipeline for you.
Compare with Zeppelin & Spark
Let’s think about Zeppelin and Spark to help you understand more.
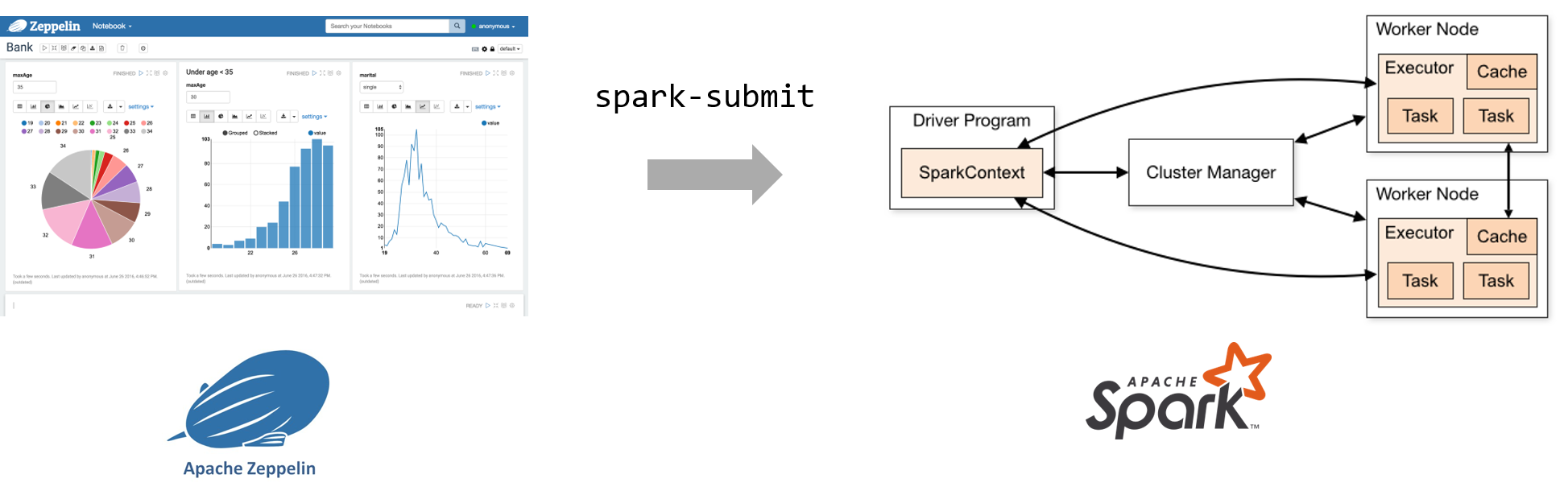
Data engineer can use Zeppelin for interactive programming and submit Spark job through spark-submit even if they do not know all the details of Spark & Hadoop cluster.
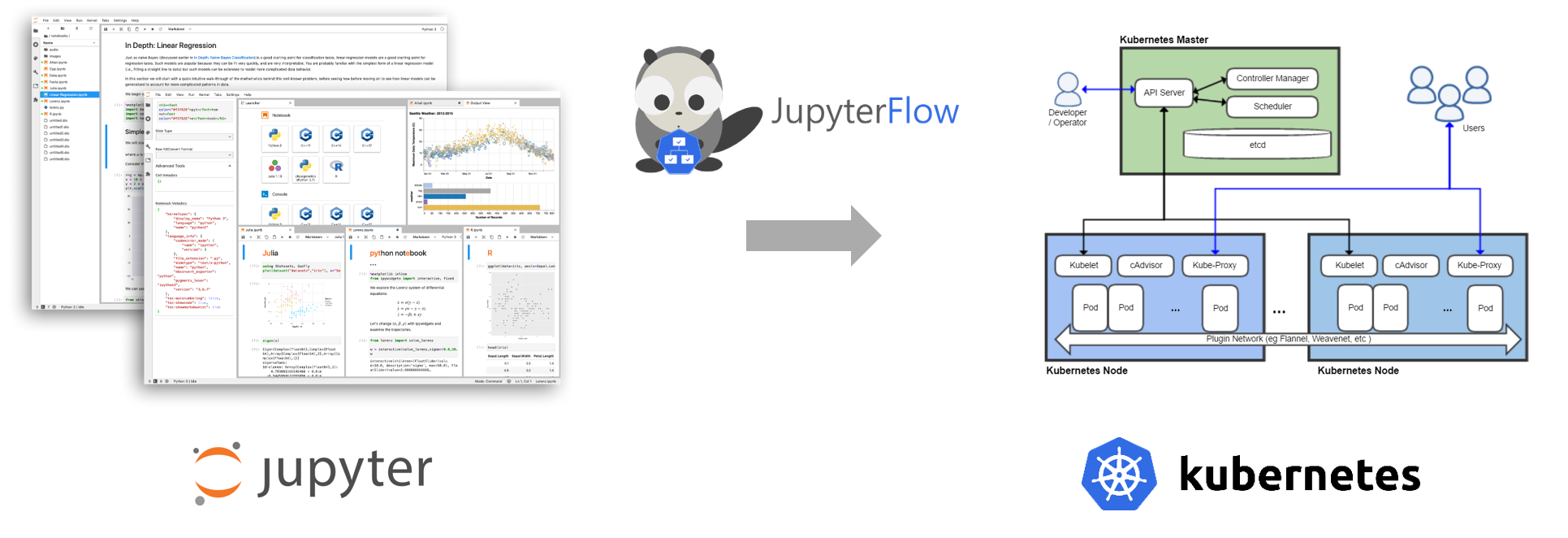
Likewise, data scientist can use Jupyter for interactive modeling and submit Kubernetes job through jupyterflow even if they do not know all the details of Kubernetes cluster.
If there is a difference, Zeppelin & Spark has its own job submitting mechanism(spark-submit script) while Jupyter & K8S don’t have. So JupyterFlow came out for closing the distance.
JupyterFlow Docs
For more details, please refer to the following JupyterFlow documentations.
Now with JupyterFlow, data scientist can write their code, run right away without any worries. How cool is it? Try out JupyterFlow!
Wrap up
JupyterFlow is my personal open source project. It is still in its early stage of development which is imperfect and has some bugs. However, I believe JupyterFlow has its own great strengh and opportunity to change the ML tool field. I have found out that there is no other similar appoach like JupyterFlow and the market still has no “De facto standard” ML tools. I am keep investing my spare time to improve this project. If you are interesting about this project, feel free to contact me by any means.
- email: hongkunyoo (at) gmail
- Github issue
- Blog comments
Any comments, questions, request for trouble shooting, feedbacks and joining the project are welcome!