![[번역] 쿠버네티스 7,500개 노드 운영하기](/assets/images/scalenode/landing02.png)
[번역] 쿠버네티스 7,500개 노드 운영하기
15 min read
지난 포스트 “[번역] 쿠버네티스 2,500대 노드 운영하기”에 이어 OpenAI에서 7,500대의 노드를 운영한 경험을 공유한 글을 번역하였습니다.
저희는 GPT-3, CLIP 그리고 DALL·E와 같은 큰 모델을 학습 시키기 위해 7,500대의 노드로 쿠버네티스 클러스터를 확장하였습니다. 뿐만 아니라 Scaling Laws for Neural Language Models 처럼 규모가 작은 모델도 실험하였습니다. 단일 클러스터로 이 정도 규모까지 노드를 확장 시킨 일은 흔하지 않았기 때문에 특별한 설정들이 필요합니다. 하지만 반대로 인프라가 간단해 지고 ML팀이 특별한 코드 수정 없이 빠르게 대규모 기계학습을 수행할 수 있게 해줍니다.
지난 포스트 2,500대 노드 운영하기에 이어 분석가들의 오구사항을 만족하기 위해 인프라를 지속적으로 늘려왔고 이를 통해 많은 교훈들을 얻을 수 있었습니다. 이번 포스트를 통해 쿠버네티스 커뮤니티의 많은 사람들에게 도움이 되었으면 좋겠고 현재 저희가 가진 문제들을 같이 고민해 보는 시간을 가졌으면 좋겠습니다.
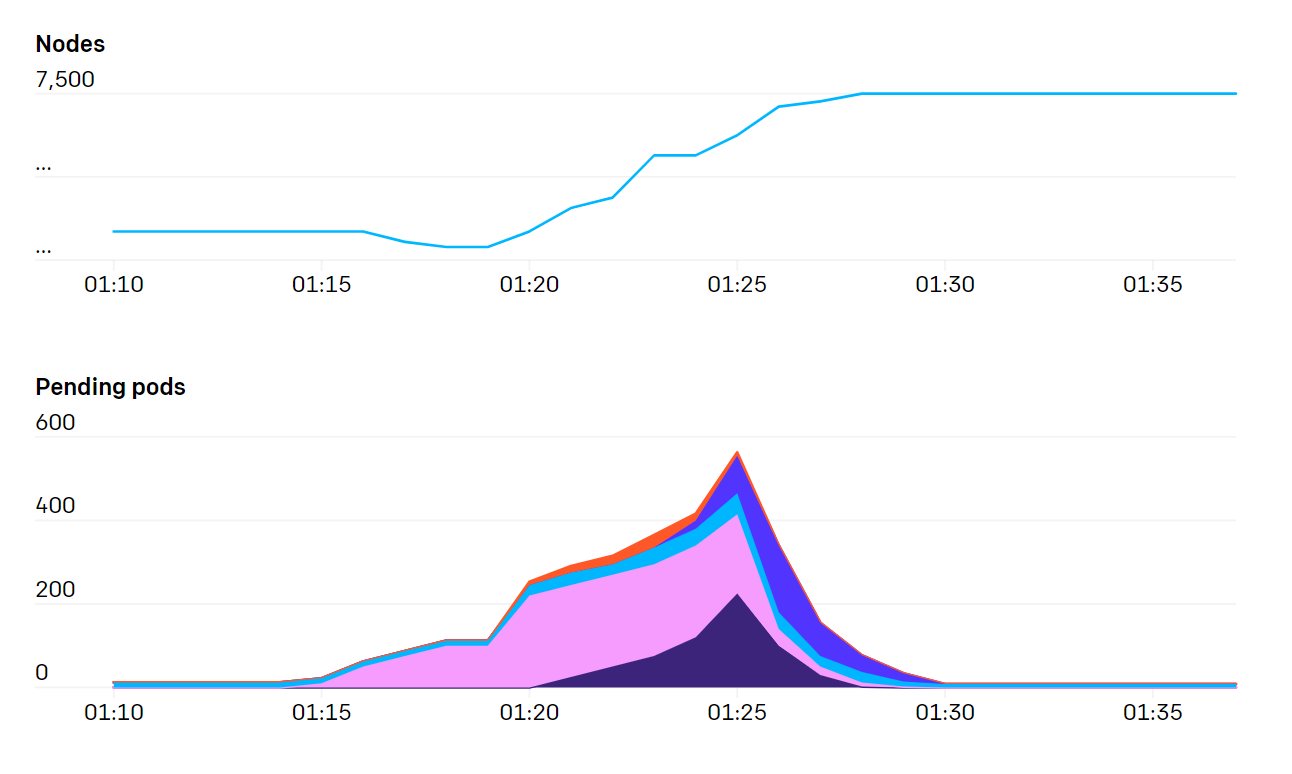
실행하는 작업의 특성
(역자주: 여기서 말하는 작업이란 기계학습 모델을 실행하는 프로세스를 의미합니다.)
자세한 내용을 다루기 전에, 우리가 하는 작업을 먼저 설명하는 것이 좋을 것 같습니다. 우리가 쿠버네티스 위에서 운영하는 어플리케이션과 하드웨어는 일반적인 회사와는 조금 다른 부분이 있습니다. 그래서 우리가 직면했던 문제와 그 해결책이 다른 회사에서 동일하게 적용될지는 모르겠습니다.
큰 규모의 기계학습 작업은 실행되는 노드의 모든 하드웨어 자원을 다 사용할 수 있을 때에 가장 효율적으로 동작할 수 있습니다. 이것은 NVLink를 통해 노드 내에 모든 GPU간 통신을 가능하게 하거나 GPUDirect을 통해 GPU가 직접적으로 네트워크 인터페이스 카드(NIC)와 통신하게 해줍니다. 지금까지 대부분의 기계학습 모델은 한개 Pod가 노드 전체를 선점하는 방식으로 실행되었습니다. NUMA, CPU나 PCIE 자원이 스케줄링의 중요한 기준이 되지 않았습니다. Bin-packing이나 fragmentation은 일반적이지 않은 문제입니다. 현재 저희 클러스터는 모든 노드 간 bandwidth이 동일하기 때문에(full bisection bandwidth) 노드의 랙 위치나 네트워크 토폴로지에 대해서는 고려하지 않습니다. 이러한 이유로 저희가 많은 수의 노드를 운영하더라도 비교적 스케줄러에는 부담이 적습니다.
이 말은, 평상 시에는 kube-scheduler의 부하가 많지 않는 반면, 간혹 한번씩 튄다는(spiky) 것을 의미합니다. 예를 들어, 한번씩 새로운 작업을 시작할 때 수백개의 Pod가 한번에 생성되고 그 이후로는 비교적 낮은 부하를 유지합니다.(역자주: 기계학습 작업들의 특징이죠.)
저희가 가진 큰 작업들은 MPI를 사용합니다. 이 작업을 수행하는 모든 Pod들은 한개의 MPI communicator와 통신합니다.
만약 한개의 Pod라도 죽는다면 전체 작업이 중단되고 재시작해야만 합니다. 대신 기계학습 모델은 지속적으로 checkpoint를 저장하여 재시작하게 되더라도 마지막 checkpoint부터 다시 시작하게끔 만들어졌습니다. 이렇듯 각 작업들이 중간에 중단되어도 다시 동작할 수 있게 만들어졌지만 그럼에도 불구하고 이런 문제가 자주 발생되지 않도록 만들어야 했습니다.
우리의 작업은 쿠버네티스의 로드 밸런싱 기능을 크게 사용하지 않았습니다. HTTP 요청을 하는 경우는 극히 드물었고 A/B 테스팅을 하거나 blue/green 배포를 하거나 카나리 배포를 할 필요가 없었습니다. 각각의 Pod들은 SSH를 이용한 MPI 통신을 Service IP가 아닌 Pod IP를 이용하여 수행하였습니다. 서비스 탐색(Service Discovery) 기능도 그리 필요하지 않았습니다. 작업 시작 시, 단 한번의 질의를 통해 어떤 Pod들이 MPI 통신에 참여하는지 확인하기만 하면 되었기 때문입니다.
대부분의 작업들은 blob 스토리지를 사용했습니다. 대부분, blob 스토리지로부터 데이터셋이나 checkpoint를 불러와서 로컬 디스크에 캐싱하여 사용했습니다. 몇 가지 POSIX 인터페이스가 유용한 경우를 제외하고는 PersistentVolume을 많이 사용하지는 않았습니다. blob 스토리지가 훨씬 더 확장 가능하기 쉬웠고 무거운 마운트/해제 작업이 필요 없었습니다.
마지막으로, 우리의 작업은 기본적으로 연구에 가까웠습니다. 그렇기에 대부분의 작업들이 자주 변경되었습니다. 이에 반에 슈퍼컴퓨팅 팀(역자주: 기계학습 인프라 및 플랫폼을 제공하는 팀)은 프로덕션 수준의 퀄리티를 유지하기 위해 노력하였습니다.(역자주: 프로덕션 수준의 퀄리티를 유지하기 위해 슈퍼컴퓨팅 팀에서는 잦은 변경을 최소화하려 했을 것으로 예상합니다. 이는 분석가들의 패턴과 상반되었을 것 같습니다.) 그렇기에 안정적이면서 빠른 변경에 효율적으로 대응할 수 있는 새로운 방법론이 필요하였습니다.
네트워킹
Pod와 Node의 개수가 증가함에 따라, 원하는 처리량(throughput)만큼 Flannel이 효과적으로 확장하는데에 어려움이 있다는 것을 발견하였습니다. 그래서 Azure에서 제공하는 CNI 플러그인을 이용하여 Azure 환경에 native하게 사용할 수 있는 CNI로 변경하였습니다. 이를 통해 각 Pod들이 호스트 노드 레벨의 네트워크 처리량을 가질 수 있게 되었습니다.(역자주: Azure에서 제공하는 CNI를 사용할 경우, 클라우드 NIC를 직접 각 Pod들에 연결할 수 있습니다. 그렇게 되면 각 Pod마다 노드 레벨의 네트워크 처리량을 가질 수 있게 될 것입니다.)
또 다른 이유는 우리는 한번의 작업에 약 200,000개의 IP 할당이 필요했었습니다. 이 때 Flannel와 같은 L2 기반의 CNI에는 한계가 있다는 것을 확인하였습니다.
또한 쿠버네티스 레벨에서의 네트워크 가상화를 제거하게 되면 클라우드 네트워크 레벨(underlying SDN)에서 더 많은 부담을 가지게 되지만 전반적인 네트워크의 구조 자체를 간결하게 만들 수 있었습니다. 클라우드에서 Pod의 네트워크를 직접 관리하였기 때문에 VPN이나 터널링을 추가하는데에 있어서 새로운 어답터를 추가할 필요가 없었고 낮은 MTU로 인해 패킷 fragmentation을 걱정할 필요도 없었습니다. 또한 네트워크 정책을 설정하거나 트래픽을 모니터링하는 것이 매우 간단해졌습니다.(역자주: Pod 네트워킹을 overlay network에서 처리하는 것이 아니라 클라우드 네트워크에서 직접 처리하기 때문에 클라우드에서 제공하는 기능들을 그대로 Pod 레벨 네트워크에서 사용할 수 있게 됩니다.)
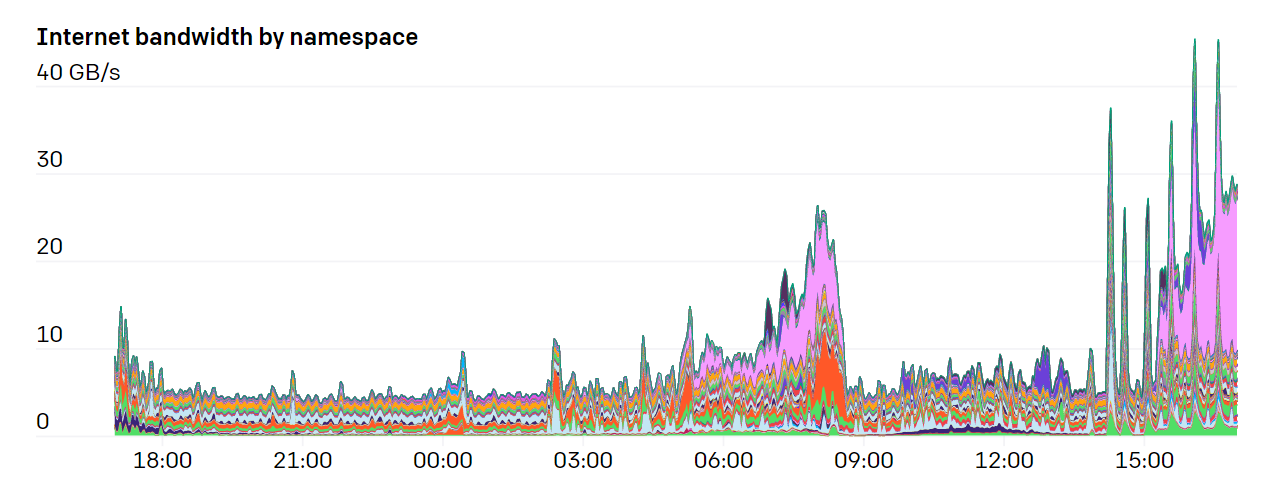
우리는 Namespace와 Pod별로 네트워크 트레픽을 추적하기 위해 iptables tagging이라는 것을 이용했습니다. 이를 통해 분석가들은 자신의 네트워크 패턴을 쉽게 이해할 수 있었습니다. 특히 많은 실험들이 특정 인터넷 사이트와 Pod간의 뚜렷한 통신 패턴이 있었기에 어디에서 병목현상이 일어나는지 확인하기에 용이했습니다.
iptables mangle 명령을 이용하여 특정 조건에 맞는 패킷을 표시했습니다. 다음 명령은 내/외부 네트워크 트래픽을 특정짓는 예시입니다. FORWARD 룰이 Pods로부터 오는 트래픽을 잡고, INPUT, OUTPUT 룰이 호스트로부터 오는 트래픽을 잡습니다.(역자주: 여기서 10.0.0.0/8은 Pod CIDR 대역으로 보입니다. 해당 대역을 통해서 들어오는지(나가는지) 아닌지에 따라 출발지/목적지 네트워크를 구분하는 것 같습니다.)
iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
일단 표식이 되면, iptables이 해당 패킷의 트래픽 양을 계산할 것입니다. 그리고 다음 명령을 이용하면 그 양을 확인할 수 있습니다.
iptables -t mangle -L -v
# Chain FORWARD (policy ACCEPT 50M packets, 334G bytes)
# pkts bytes target prot opt in out source destination
# ....
# 1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */
# 1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */
우리는 해당 정보를 모니터링 시스템인 Prometheus에 넣기 위해 iptables-exporter라는 exporter를 사용했습니다. 이 모듈을 이용하여 다양한 조건에 해당하는 패킷을 추적하였습니다.
한가지 우리 네트워크 모델만의 특별한 부분은 바로, Node, Pod와 Service CIRD를 분석가에게 전부 직접적으로 노출했다는 점입니다. 우리는 hub-and-spoke 모양의 네트워크 구조(역자주: 각 거점마다 큰 hub가 있고 그 hub와 연결되는 작은 spoke 노드가 있는 네트워크 구조를 말합니다. 전세계 거점마다 있는 큰 국제공항과 그와 연결된 작은 지방공항을 생각하면 이해하기 쉽습니다.)를 가졌습니다. 그리고 Node와 Pod CIDR 대역을 이용하여 해당 네트워크 위에서 서로 라우팅할 수 있게 설계되었습니다. 분석가는 특정 hub에 접속을 할 수 있었고 그 hub로부터 연결된 어떤 spoke 클러스터로든지 상관없이 접근할 수 있었습니다. 하지만 한번 특정 spoke 클러스터에 들어가게 되면 다른 클러스터와는 통신을 할 수 없게 만들었습니다. 이를 통해 클러스터간 네트워크 종속성을 끊어내 확실한 구분을 지을 수 있었습니다.
우리는 각 spoke 클러스터로부터 나오는 트래픽에 대하여 Service CIDR 대역을 NAT하여 사용하였습니다. 이를 통해 분석가들로 하여금 굉장히 유연한 구조로 자신들의 실험 모델을 구성할 수 있게 하였습니다.
API Servers
쿠버네티스의 API서버와 etcd는 클러스터가 정상적으로 동작하기 위한 필수적인 요소입니다. 그렇기 때문에 해당 component들의 부하 문제에 각별한 신경을 썼습니다. 우리는 kube-prometheus에서 제공하는 grafana 대시보드를 기본적으로 이용했습니다.(역자주: Prometheus 진영에서는 다양한 prometheus-stack을 지원합니다. 자세한 내용은 다음 링크를 참고해 보시기 바랍니다.) 거기에 추가적으로 직접 만든 대시보드를 추가하였습니다. 또한 API 서버에서 발생하는 HTTP 응답 코드 중 429 (Too Many Requests)와 5xx번대 에러(Server Error)에 알람을 걸어놓는 것이 API 서버의 이상을 파악하는데 많은 도움을 주었습니다.
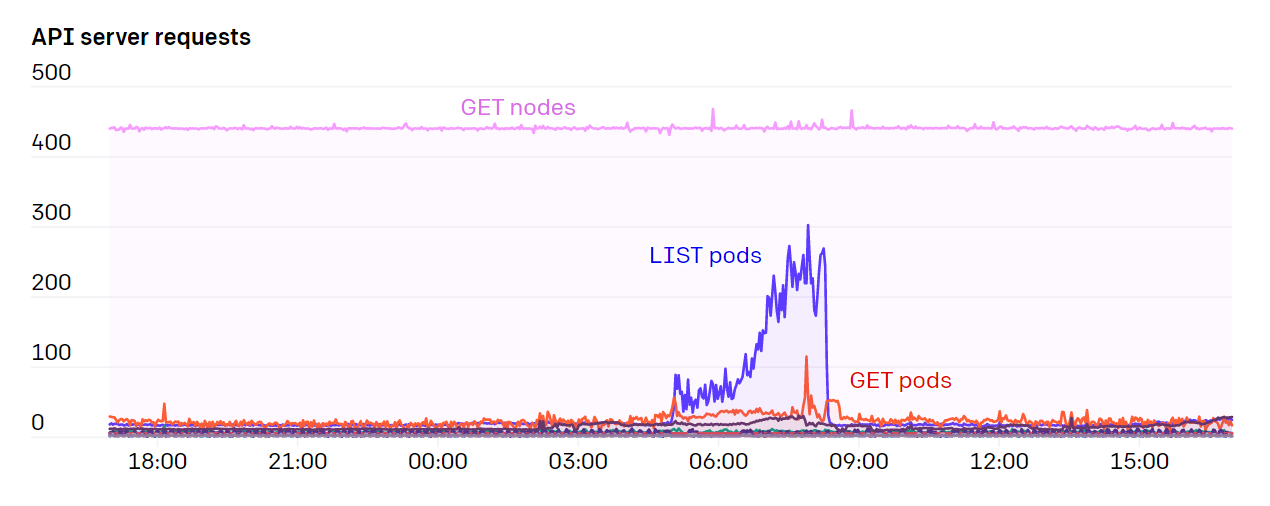
많은 사람들은 API서버를 쿠버네티스 내부에 두지만 우리는 API서버를 항상 클러스터 외부에 설치했습니다.(역자주: kubelet이 관리하는 static pod 형태가 아닌 Systemd에서 직접 관리하는 형식으로 API서버를 구성했는 것으로 추측합니다.) API서버와 etcd 둘다 전용 서버(dedicated nodes) 위에서 실행되었습니다. 우리가 운영하는 클러스터 중 가장 큰 녀석에는 각각 5개의 API서버와 etcd를 구성하여 부하를 분산 시키고 노드 장애에 대비하였습니다. 앞선 포스트에서 얘기한 내용으로, etcd에서 쿠버네티스 Event를 다른 etcd로 분리한 이후에는 etcd에서 큰 문제가 발생하지 않았습니다. API서버는 stateless하기 때문에 self-healing instance나 scaleset으로 운영하는 것이 비교적 쉬웠습니다.(역자주: 각 클라우드 플랫폼에서 제공해주는 autoscaling 기능을 말합니다.) 반대로 etcd를 자동 자가치유 시스템으로 만들어보진 않았습니다. 왜냐하면 아직까지 etcd에서 그리 큰 문제가 발생한 적이 없었기 때문입니다.
API서버는 꽤 많은 양의 메모리를 잡아 먹습니다. 또한 클러스터의 노드 수에 따라 선형적으로 증가하는 모습을 보입니다. 약 7,500대의 노드를 가진 우리 클러스터에서는 각 API서버마다 약 70GB의 힙 메모리를 사용하는 것을 확인했습니다. 다행히 이것은 현재 존재하는 하드웨어 스펙 내에서도 충분히 감당할 만한 사용량입니다.
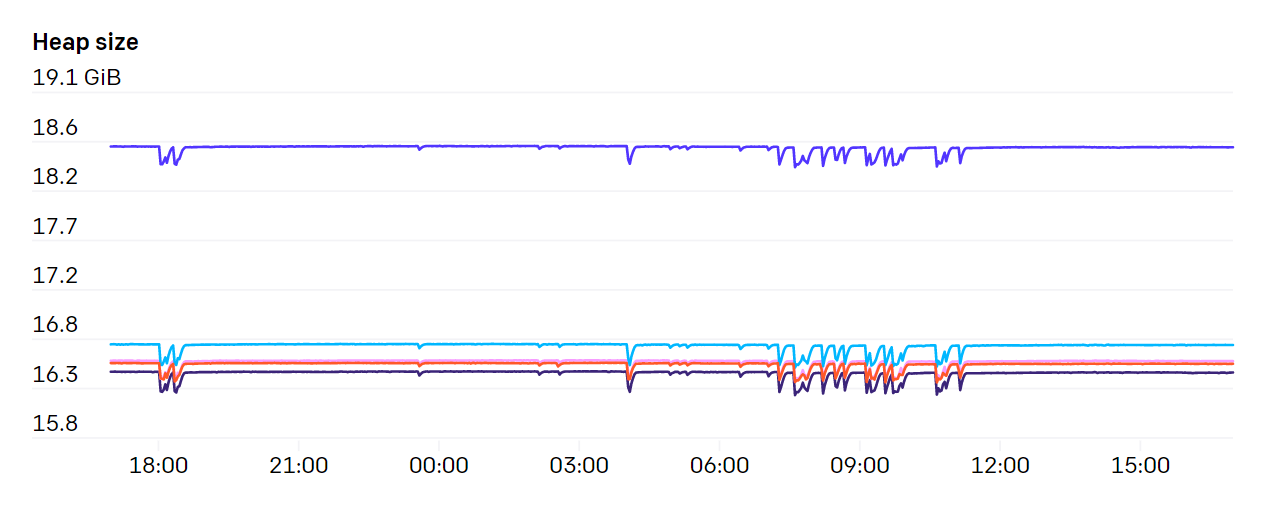
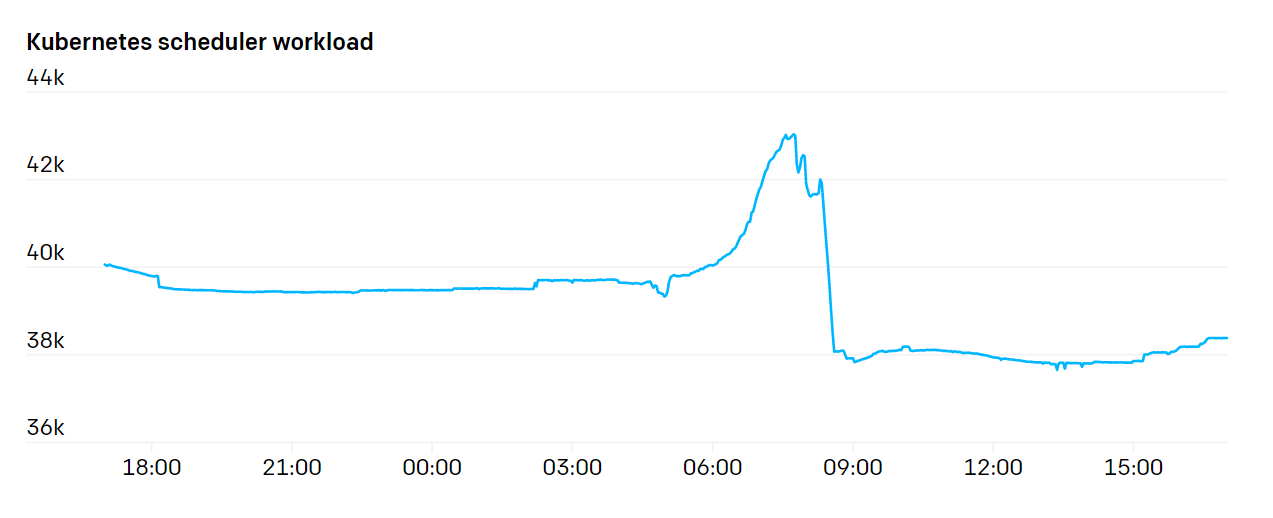
한가지 API서버에서의 큰 부담은 바로 Endpoint 리소스를 Watch하는 것이었습니다. kubelet이나 node-exporter처럼 클러스터의 모든 노드에 존재하는 서비스들이 있었습니다. 매번 새로운 노드가 클러스터에 추가되거나 제거될 때, 이 Watch하는 부분에서 큰 부하가 발생하였습니다. 왜냐하면 일반적으로 각 노드마다 있는 kubelet을, kube-proxy를 통해 관리(watching)하고 있는데 노드 변경으로 발생하는 네트워크 bandwitdh 요구량은 \(N^2\) 이 되었고 이는 평균적으로 1GB/s 이상이 필요했습니다. 다향히 쿠버네티스 1.17 버전에서 EndpointSlices가 나온 이후부터 그 부하가 1000배 이하로 떨어지게 되었습니다.
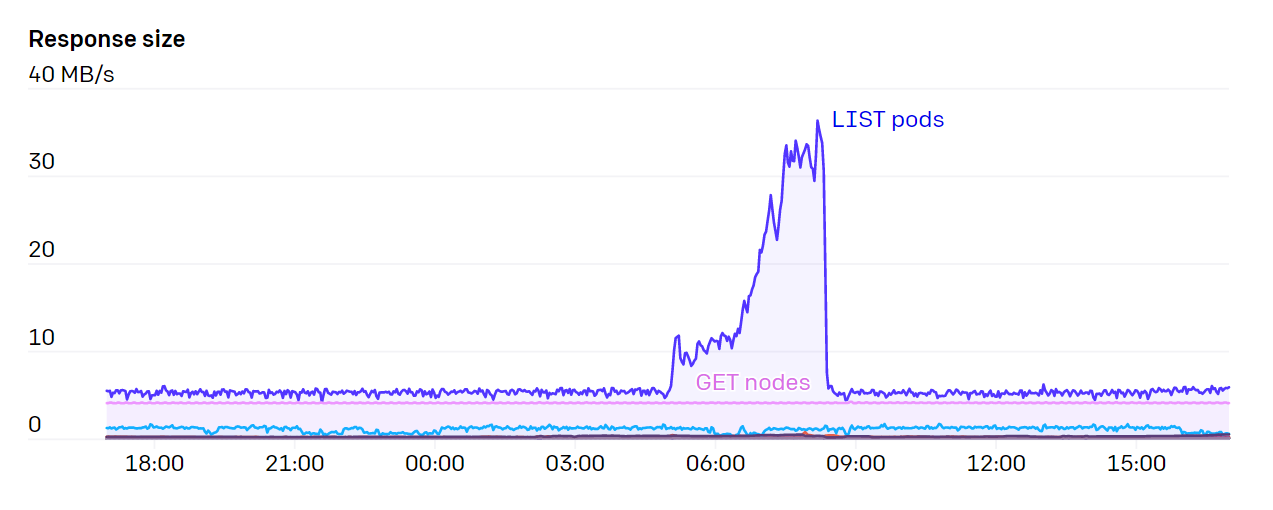
우리는 클러스터 크기에 따라 비례적으로 증가하는 API서버 요청에 대해서 각별한 주의를 가졌습니다. 예를 들어, Daemonset이 API서버와 직접적으로 통신하는 것을 최대한 막았습니다. 만약에 각 노드들이 특정 변경을 지속적으로 확인해야 하는 상황이 발생한다면(역자주: 모든 노드들이 특정 변경 사항을 지속적으로 확인하려면 주기적으로 API서버에 질의해야 하기 때문에 노드 수에 비례하여 API서버에 부하를 주게 됩니다.) Datadong Cluster Agent와 같이 중간 캐싱 서비스를 두는 것이 클러스터 레벨의 병목현상을 제거하는데 좋은 해결책이 되었습니다.
클러스터의 크기가 증가함에 따라 실제로 autoscaling하는 경우는 줄어들게 되었습니다. 하지만 간혹 한번씩 한번에 너무 많이 autoscaling하는 경우가 발생했습니다. 새로운 노드 한대가 클러스터에 추가 될때 많은 요청이 발생하게 되는데 백여개의 노드가 한번에 클러스터에 추가 되면 API서버에 큰 부하를 주게 되어 API서버의 처리량을 넘어서게 될 수 있습니다. 이러한 문제는, 몇 초의 시간이라도, 약간 시간을 두고 autoscaling을 수행하게 되면 장애를 방지하는데 큰 도움을 줬습니다.
Prometheus와 Grafana - 시계열 메트릭
우리는 시계열 메트릭을 수집하기 위해 Prometheus를 사용하였고 메트릭을 시각화하고 알람을 설정하기 위해 Grafana를 이용했습니다. kube-prometheus 스택을 먼저 배포함으로써 기본적으로 제공하는 다양한 메트릭과 대시보드를 클러스터에 설치하였습니다. 시간이 지남에 따라 우리에게 필요한 여러가지 메트릭과 알람, 대시보드를 추가하였습니다.
노드를 계속 추가함에 따라, 너무도 많은 양의 메트릭이 수집되는 것에 애를 먹었습니다. kube-prometheus가 유용한 데이터를 수집하는 것은 분명하지만 그 중에 어떤 데이터는 전혀 쳐다보지도 않았고 어떤 것은 지나치게 너무 짧은 주기를 가지고 수집한다는 것을 발견했습니다. 그래서 우리는 Prometheus Rule을 이용하여 특정 메트릭을 drop하는 규칙을 추가하였습니다.
한동안 우리는 Prometheus 서버가 점점 더 많은 메모리를 소비하다가 OOM(Out-Of-Memory)으로 죽는 문제로 고생했습니다. 이러한 문제는 Prometheus 컨테이너에 엄청나게 많은 메모리를 할당한 이후에도 지속적으로 발생하였습니다. 더 큰 문제는 Prometheus 서버가 죽은 이후에 WAL(write-ahead-log) 파일을 다시 읽느라 너무 많은 시간을 소비하는 것에 있었습니다.
결국, 우리는 OOM이 발생하는 근본적인 이유를 추적하기 시작했고 Grafana와 Prometheus가 서로 통신하는 과정에서 문제가 발생하는 것을 발견했습니다. Grafana가 {le!=""} 쿼리와 함께 Prometheus의 /api/v1/series URL로 API를 요청한다는 사실을 알게 되었습니다.(한마디로 프로메테우스한테 모든 히스토그램 데이터를 달라는 것을 의미했습니다.) /api/v1/series API는 특정 시간 대역과 메트릭에 제약되지 않았기 때문에 엄청나게 많은 쿼리 결과를 유발하여 많은 메모리를 소비하게 만들었습니다. 더군다나 요청자가 포기하고 커넥션을 종료하더라도 지속되었습니다. 우리는 메모리가 항상 충분하지 않았기 때문에(역자주: 기계학습 모델들 중에서 메모리를 많이 사용하는 경우가 많기 때문이라 생각합니다.) 해당 API가 특정 조건 안에서 질의하도록 하고 timeout을 강제하도록 API를 수정하여 문제를 완벽히 해결하였습니다.
이를 통해 Prometheus가 crash되는 경우가 현저히 줄어 들었지만 여전히 장애가 발생하여 재시작되면 WAL 파일을 다시 읽느라 초기 로딩 시간이 엄청 길어지는 문제가 있었습니다. Robust Perception사의 도움으로 GOMAXPROCS=24 옵션을 추가하는 것이 큰 도움이 된다는 것은 발견했습니다. 해당 옵션을 사용하면 Prometheus가 WAL 파일을 읽는 동안 모든 코어를 사용하려고 노력하였고 더 빠르게 WAL 파일을 읽을 수 있었습니다. 하지만 이로 인해 Prometheus 외 다른 시스템의 퍼포먼스를 떨어뜨렸습니다. 현재 우리는 예전이 이 문제를 해결하려고 노력하고 있습니다. 아래의 “아직 해결하지 못한 문제들”에서 더 다룹니다.
상태점검 (Healthchecks)
기본적으로 우리 클러스터는 자동으로 장애 노드를 발견하고 제거하게끔 설계되어 있습니다. 그리고 몇 가지 우리만의 상태점검 시스템을 추가하였습니다.
소극적인 상태점검 (passive healthchecks)
특정 상태점검은 소극적으로 동작하고 항상 모든 노드에서 실행됩니다. 이들은 네트워크 연결성(reachability), 디스크 장애나 GPU 장애와 같이 기본적인 시스템 리소스를 모니터링합니다. GPU는 다양한 형태로 장애가 나타나는데 대표적인 것으로 “Uncorrectable ECC error” 에러가 있습니다. DCGM(Nvidia의 Data Center GPU Manager)을 이용하면 손쉽게 에러를 찾을 수 있으며 Xid 메트릭을 이용하여 그 외 다양한 에러를 발견할 수 있습니다. 우리가 사용한 방법으로는 dcgm-exporter를 이용하여 Prometheus로 해당 메트릭을 수집하였습니다. 이것은 DCGM_FI_DEV_XID_ERRORS이라는 메트릭 이름으로 표시되었으며 가장 최근에 발생한 에러 코드가 저장되었습니다. 추가적으로 NVML Device Query API를 사용하면 더 많은 상세 GPU 상태 정보를 제공해 줍니다.
GPU 에러를 발견하면, 많은 경우 단순히 GPU나 시스템을 재시작하면 해결이 되었지만 간혹 물리적으로 GPU 카드를 교체해야 하는 경우도 있었습니다.
또 다른 상태점검 지표는 클라우드 서비스에서 제공하는 서버 유지보수 지표(maintenance events)였습니다. 각 메이저 클라우드 서비스 업체들은 현재 사용하는 VM이 유지보수로 인해 서버가 중단할 것인지 알려주는 지표를 제공합니다. 하이퍼바이저 패치나 실제 물리 노드 교체로 인해 서버를 재부팅해야 하는 경우가 있기 때문입니다.
이러한 소극적인 상태점검 프로세스가 모든 노드에서 주기적으로 동작합니다. 만약에 특정 상태점검이 실패한다면 해당 노드는 자동으로 cordon이 되어 더 이상 새로운 Pod가 스케줄링되지 않게 합니다. 더 중대한 문제가 발생하면 모든 Pod를 evict 시켜서 해당 노드에서 돌고 있는 모든 프로세스를 종료 시킵니다. 하지만 실제로 evict될지 말지는 Pod Disruption Budget 리소스를 통해서 Pod를 생성한 사용자가 직접 선택할 수 있습니다. 결국에 모든 Pod가 종료되거나 저희의 SLA(Service Level Agreement)에 의해 7일이 지나게 되면 VM을 강제로 종료합니다.
능동적인 GPU 테스트
불행히도 모든 GPU 문제가 DCGM에 의해서 발견되는 것은 아닙니다. 우리는 직접 저희만의 GPU 상태를 테스트할 수 있는 모듈을 개발하였습니다. 이 테스트들은 백그라운드로 실행될 수 없고 명시적으로 GPU를 할당 받아서 사용해야 합니다.
처음에는 GPU 서버가 리부팅될 때 해당 테스트를 실행하였습니다. 우리는 이것을 “preflight” 시스템이라 불렀습니다. 클러스터에 추가되는 모든 노드들은 “preflight”이라는 taint와 label이 붙혀졌습니다. 이로 인해 정상적인 Pod가 테스트 중인 노드에 할당되는 것을 막아줬습니다. 그리고 특정 Daemonset이 “preflight” 라벨이 붙은 노드에서 자동으로 동작하도록 설정하였습니다. 해당 Daemonset이 성공적으로 모든 테스트를 통과하게 되면 자동으로 taint와 label을 제거하도록 하여 테스트 이후에 자동으로 운영 상태로 넘어가도록 구성하였습니다.
이후 우리는 서버 리부팅때 뿐만 아니라 주기적으로 이 테스트가 노드에서 동작하도록 만들었습니다. CronJob을 이용하여 임의의 노드에서 동작할 수 있도록 만들었습니다. 비록 특정 알고리즘을 이용하여 모든 노드가 테스트 되도록 설정하지 않고 임의로 노드를 선택하여 테스트하도록 만들었지만 나름 충분한 coverage를 제공하는 것을 확인하였습니다.
Quotas와 리소스 사용량
클러스터를 확장함에 따라 분석가들은 자신들에게 할당된 리소스를 전부 사용하는게 어렵다는 것을 알게 되었습니다. 전통적인 잡 스케줄링 시스템에서는 클러스터를 사용하는 각 팀마다 공정한 리소스를 할당 해주기 위해 다양한 feature들을 제공해 줍니다. 하지만 쿠버네티스에서는 이러한 기능이 빈약하죠. 그래서 우리는 이러한 전통적인 잡 스케줄링 시스템에 대해서 공부하여 “쿠버네티스”스럽게(kubernetes-native way) 클러스터에 적용하였습니다.
팀별 taints
이를 위해, 각 클러스터마다 “team-resource-manager”라는 서비스를 두었습니다. 이 서비스는 다양한 기능을 가졌는데요, ConfigMap에 정의된 설정값을 통해 서비스를 컨트롤할 수 있었습니다. 이 설정값에는 node selector, 팀 라벨, 사용 가능한 리소스양에 대한 정보가 들어 있었습니다. 이 서비스는 현재 클러스터의 상황과 설정값의 정보를 보고 자동으로 적절한 노드 수를 taint를 이용하여 각 팀에 할당하였습니다. (openai.com/team=teamname:NoSchedule)
“team-resource-manager” 서비스는 admission webhook 기능도 있어서 새로운 작업이 실행되면 그 작업을 실행한 팀의 정보가 toleration으로 추가되었습니다.(역자주: admission control이란 어떤 리소스, 예를 들어 Pod를 생성 시, 추가적인 기능을 넣거나 제거하거나 deny할 수 있는 쿠버네티스 기능 중에 하나입니다. 여기서는 자동으로 toleration property를 추가하였습니다. 자세한 내용은 커피고래의 Admission Control 시리즈를 확인하시기 바랍니다.) taint와 admission control은 Pod들을 유연하게 스케줄링할 수 있는 메커니즘을 제공해 주었습니다. 예를 들어, 낮은 우선순위를 가진 Pod들에 대해서는 “any”라는 toleration을 허용함으로써 다른 팀의 리소스를 빌리는 방법 등이 가능해졌습니다.
CPU & GPU 풍선(balloons)
(역자주: 아무 작업도 하지 않는 빈껍데기 Pod를 여기서는 풍선이라 표현하였습니다.)
cluster-autoscaler는 동적으로 VM을 확장하기 위해 사용하는 것 외에도, 상태가 나쁜(unhealthy) 노드를 교체하는 용도로도 사용할 수 있습니다. “min size”를 0으로 놓고 “max size”를 가용한 최대 사이즈로 설정하면 쉽게 노드를 교체할 수 있었습니다. 하지만 cluster-autoscaler는 놀고 있는 노드를 발견하게 되면 자동으로 노드를 축소하는데 이것은 몇 가지 문제를 만들었습니다. 먼저 리소스가 부족해져서 새로운 VM을 띄울 때(autoscaling 될 때) 올라오는 시간이 걸렸고, 이로인해 앞서 설명한 것처럼 API 서버에 부하를 주었습니다.
그래서 우리는 CPU, GPU 노드에 풍선 Deployment라는 녀석을 배포하였습니다. 이 Deployment는 우선순위가 낮은 Pod들을 최대 노드 개수만큼 만들었고 이에 cluster-autoscaler는 여유분의 노드들에 대해서 놀고 있다고 판단하지 않게 되었습니다. 만약 진짜 작업을 위한 Pod가 들어오게 되면 우선순위가 낮은 풍선 Deployment들의 Pod들은 자연스럽게 evicted되어 자리를 비켜주었습니다. 우리는 이 풍선 역할에 Daemonset 대신에 Deployment를 사용했습니다. 왜냐하면 Daemonset은 노드가 놀고 있는지 판단할 때 계산에서 제외되기 때문입니다.
한가지 기억해야 하는 점은, Deployment에 anti-affinity 설정을 하여 Pod가 각 노드에 전체적으로 분산되도록 설정하였습니다. 쿠버네티스 초기의 anti-affinity는 \(O(N^2)\)라는 퍼포먼스 이슈가 있었습니다. 다행히 이것은 1.18 이후에 고쳐졌습니다.
Gang 스케줄링
기계학습 실험에서 간혹 StatefulSet 리소스를 사용하였습니다. 각 Pod들은 각자 학습에 다른 부분을 맡아서 실행됩니다. Optimizer인 경우(역자주: 기계학습에서 모델을 최적화하기 위한 옵티마이저를 의미합니다.) 학습이 끝나기 전에 StatefulSet의 모든 Pod들이 미리 스케줄링되어야 합니다.(optimizer끼리의 조정을 위해 MPI 프로토콜을 사용하기 때문입니다. MPI 프로토콜은 그룹 멤버십 변화에 민감합니다.)
하지만 쿠버네티스는 기본적으로 특정 그룹의 Pod들이 한꺼번에 실행하도록 강제하지 못합니다.(역자주: 기본적으로 Gang 스케줄링을 지원하지 않습니다.) 예를 들어 두개의 실험을 동시에 실행하는데 리소스가 충분치 않는 경우, 한개 실험의 관련된 Pod들만 전부 실행되고 나머지 실험의 Pod들은 대기하고 있는 것이 아니라 두개의 실험의 Pod들이 섞여서 실행됩니다. 이로 인해 한개 실험이 완벽하게 끝나지 못하고 교착상태(deadlock)에 빠지게 될 수도 있습니다.(역자주: Gang 스케줄링의 필요성을 말하고 있습니다. Gang 스케줄링이란, 어떤 그룹의 프로세스들이 전부 스케줄링 되던지 아니면 모두가 스케줄링되지 않던지 결정하는 스케줄링을 말합니다. 마치 갱조직처럼 무리지어 다닌다고 하여 Gang 스케줄링이라 부릅니다.)
그리하여 우리는 Gang 스케줄링을 지원하기 위해 커스텀 스케줄러를 만들려고 노력했지만 특정 상황에서 정상적인 Pod가 제대로 실행되지 않는 또 다른 문제에 봉착하게 되었습니다. 다행히 쿠버네티스 1.18부터 기본 스케줄러(default scheduler)에 플러그인을 추가할 수 있는 기능이 생겨 훨씬 더 쉽게 특정 기능을 추가할 수 있게 되었습니다. 최근에는 Coscheduling 플러그인을 이용하여 해당 문제를 효과적으로 해결할 수 있게 되었습니다.
아직 해결하지 못한 문제들
쿠버네티스 노드를 7,500대 확장하면서 발생한 문제들 중에 아직까지 해결하지 못한 부분들이 있습니다.
메트릭
저희가 다루고 있는 노드의 스케일에서는 프로메테우스가 제공하는 자체 TSDB(Time Series DB)에 많은 문제점들이 발생했습니다. 특히 WAL파일을 압축하거나 WAL파일을 다시 처음부터 읽는 시간이 너무 길었습니다. 질의하는 쿼리들도 다음과 같은 에러가 발생하는 경우가 점점 빈번해 졌습니다: “query processing would load too many samples”.
현재 프로메테우스와 비슷한 역할을 수행하는 다른 쿼리 엔진을 검토해 보고 있습니다.(역자주: Thanos나 Victoria Metric과 같은 대안이 있습니다.)
트래픽 집중 문제
노드를 추가함에 따라, 각 Pod들이 발생하는 트래픽으로 인해 의도치 않게 특정 인터넷 서비스에 큰 부하를 발생하는 경우가 생겼습니다. 예를 들어 인터넷에 있는 특정 데이터셋을 다운 받거나 소프트웨어 패키지를 한꺼번에 받는 경우가 그렇습니다.(역자주: 의도치 않게 특정 사이트에 디도스 공격을 발생 시킬 수 있다는 것을 말한다고 봅니다.)
결론
쿠버네티스는 우리가 수행하는 연구에 놀랍도록 유연하게 잘 맞아 떨어진다는 것을 확인했습니다. 우리가 원하는 대부분의 작업을 쿠버네티스가 문제 없이 수행하였습니다. 여전히 많은 부분에서 개선해야 할 것들이 있지만 저희 OpenAI팀에서 끊임 없이 쿠버네티스를 잘 확장해서 사용할 수 있도록 노력할 것입니다. 이러한 일들은 정말 흥미롭습니다!
마무리
OpenAI팀은 정말 대단한 것 같습니다. 글을 번역하면서 일부는 제가 속한 조직에서 해결한 방법과 비슷한 부분도 보였고 반대로 전혀 새로운 방법도 알게 되었습니다. 비슷한 부분에서는 “우리도 영 이상하게 가고 있지는 않구나”라는 안도감을, 새로운 방법에서는 많은 것들을 배울 수 있는 시간이 되었습니다.