
데이터 과학자를 위한 ML툴 - JupyterFlow
8 min read
지난 포스트 “데이터 과학자들은 쿠버네티스에 관심이 없습니다”에 이어 제가 생각하는 좋은 툴은 어떤 것인지에 대해 살펴 보도록 하겠습니다.
이전 포스트의 내용을 정리하자면 다음과 같습니다.
- 쿠버네티스는 기계학습을 효율적으로 수행하기 위한 좋은 툴이다. 쿠버네티스의 뛰어난 기능 덕분에 쿠버네티스를 활용하여 기계학습 모델을 실행하려는 시도는 많이 있다.(Kubeflow 등)
- 하지만 데이터 과학자 입장에서는 사용하기가 불편하다. 쿠버네티스의 복잡한 개념을 전부 이해 해야지만 제대로 사용할 수 있기 때문이다.
- 데이터 과학자가 ML에만 집중할 수 있게 사용하기 편리한 툴이 필요하다.
저도 100% 공감하는 내용이며 어떻게 하면 데이터 과학자가 쿠버네티스의 세부 설정을 전부 알지 못하더라도 쿠버네티스의 강력한 기능을 편리하게 사용할 수 있을까 지속적으로 고민을 하였고 오늘 (정답이 아닐 수는 있지만) 제가 생각하는 해결책을 공유드리고자 합니다.
쿠버네티스 기반의 ML 툴을 사용하기 어려운 이유
앞선 포스트에서도 다뤘지만 다시 한번 짚고 넘어가자면 쿠버네티스 기반의 ML툴, 대표적으로 Kubeflow와 같은 프레임워크를 사용할 때 데이터 과학자가 느끼는 장벽은 크게 두가지입니다.
- 자신의 코드를 컨테이너화 시키는 부분(도커 이미지 빌드 과정 및 실행)
- 쿠버네티스 매니페스트(manifest: YAML 파일)를 작성하는 부분
먼저 컨테이너화 시키는 부분부터 살펴 봅시다. 자신의 모델을 코드로 작성하는 일은 데이터 과학자 누구나 잘하는 일입니다. 문제는 자신의 코드를 학습서버 / 운영서버 위로 배포할 때 발생합니다. 쿠버네티스 기반의 플랫폼 위로 본인의 코드를 올리기 위해서는 컨테이너화라는 작업이 필요하게 되는데 이것은 개발자를 위한 과정이지 데이터 과학자를 위한 과정은 아닙니다. 그렇기 때문에 데이터 과학자 입장에서는 이러한 작업이 어색하게 느껴질 수 있습니다. 쿠버네티스 매니페스트를 작성하는 것도 마찬가지입니다. 데이터 과학자가 굳이 신경 쓸 필요 없는 세부적인 인프라 설정 정보들을 입력해야 하고 규칙에 맞게 매니페스트 파일을 작성해야 합니다. 이를 해결하기 위해서 몇가지 방법들이 있습니다.
해결책
1. 개발자의 도움을 얻는다.
데이터 과학자가 힘들어 하는 부분을 데이터 엔지니어, 소프트웨어 엔지니어가 지원하는 방법이 있을 수 있습니다. 이것은 가장 간단하고 빠른 해결책이 될 수 있습니다. 하지만 개발자들도 본연의 역할들이 있기 때문에 이것은 지속 가능하지 않으며 전반적인 모델 개발 사이클을 늦추게 됩니다. 특히나 분석이라는 업무 자체가 기존 소프트웨어 개발과는 다르게 조금씩 코드를 수정해 보며 모델링 결과를 살펴봐야하는 경우가 많은데 그때마다 매번 다른 사람에게 종속성이 걸려 있으면 쉽게 지치게 됩니다.
2. 교육을 통해 데이터 과학자가 쿠버네티스를 직접 사용할 수 있게 한다.
앞선 포스트에서도 언급했듯이 모두가 유니콘이 될 수 없습니다. 그리고 단일 책임 원칙(Single-responsibility principle)에 따라 각자 잘하는 영역을 집중하는 것이 더 비용 효율적일 수 있습니다.(물론 단일 책임 원칙은 사람에 대한 원칙이 아니라 프로그래밍 원칙이긴 하지만요.)
3. 추상화를 통해 간편하게 사용할 수 있는 툴을 제공한다.
지난 포스트에서의 해결책으로, 적절한 추상화를 통해 쿠버네티스의 복잡한 설정값을 숨겨 데이터 과학자가 일일이 모든 것을 알 필요 없이 모델링에 필요한 파라미터만을 신경 쓸 수 있도록 ML 툴을 개발하여 제공하는 것을 제안하였고 그 구현체로 Determined AI사에서 개발한 제품을 간단하게 소개하였습니다.
커피고래가 제안하는 해결책
제가 제안하는 방법은 3번의 해결책과 비슷하지만 Determined AI의 방식과는 조금 다릅니다. 만약 다음과 같이 할 수 있다면 어떨까요?
컨테이너화 작업을 애초에 수행하지 않게 한다.
앞서 설명드렸듯이 제가 생각하기에 쿠버네티스 기반의 ML툴을 사용하는 것의 큰 장벽 중 하나가 데이터 과학자로 하여금 본인의 ML 코드를 컨테이너화 시키는 작업이라고 말씀드렸습니다. 그렇다면 이 작업을 아예 없앨 수는 없을까요?

여러분들은 제가 도대체 무슨 말도 안되는 소리를 하고 있나 의아해 하실 것 같습니다. 쿠버네티스 공식 홈페이지에 나오는 첫 문장이 “Production-Grade Container Orchestration”으로 쿠버네티스는 컨테이너를 위한 오케스트레이션 플랫폼인 것을 명시하고 있습니다. 이런 플랫폼을 가져다 활용하는 마당에 컨테이너화 작업을 하지 않고도 데이터 과학자의 ML 코드를 쿠버네티스 위에서 실행할 수 있을까요?
제 생각은 “네, 가능합니다.” 단, 한가지 제약 조건이 있습니다.
처음부터 컨테이너 내부에서 개발하면 됩니다.
조금 더 자세하게 설명하겠습니다. 현재 문제는 데이터 과학자가 직접 컨테이너화 작업을 수행해야 하는 것이며 이것이 쉽지 않은 일이라는 것입니다. 그럼 미리 컨테이너화된 환경을 만들어서 데이터 과학자에게 제공하는 것은 어떨까요? 그 안에서 데이터 과학자가 본인의 코드를 개발하면 자연스럽게 데이터 과학자의 머신러닝 코드를 컨테이너에 탑재할 수 있을 것 같습니다. 그리고 이 컨테이너를 쿠버네티스 위로 배포하면 됩니다. 하지만 여기에 문제가 있습니다.
- 어떻게 미리 컨테이너화된 환경을 데이터 과학자에게 손쉽게 제공할 수 있을까요?
- 컨테이너 안에서 만들어진 코드를 어떻게 쿠버네티스로 전달할까요?
JupyterHub on Kubernetes
1번째 문제에 대한 해법은 주피터 허브에 있습니다. 주피터 허브란 여러 사용자가 각자 본인의 분석환경을 개별적으로 가질 수 있도록 제공해주는 플랫폼입니다. 주피터 허브를 구축하는 방법은 여러 가지가 있으나 제가 제시하는 해결책은 쿠버네티스 위에 주피터 허브를 배포하는 경우에 한해서만 유효합니다. 앞으로 설명드리는 주피터 허브는 전부 쿠버네티스 기반의 주피터 허브에 대한 내용입니다.
주피터 허브의 아키텍처는 다음과 같습니다.
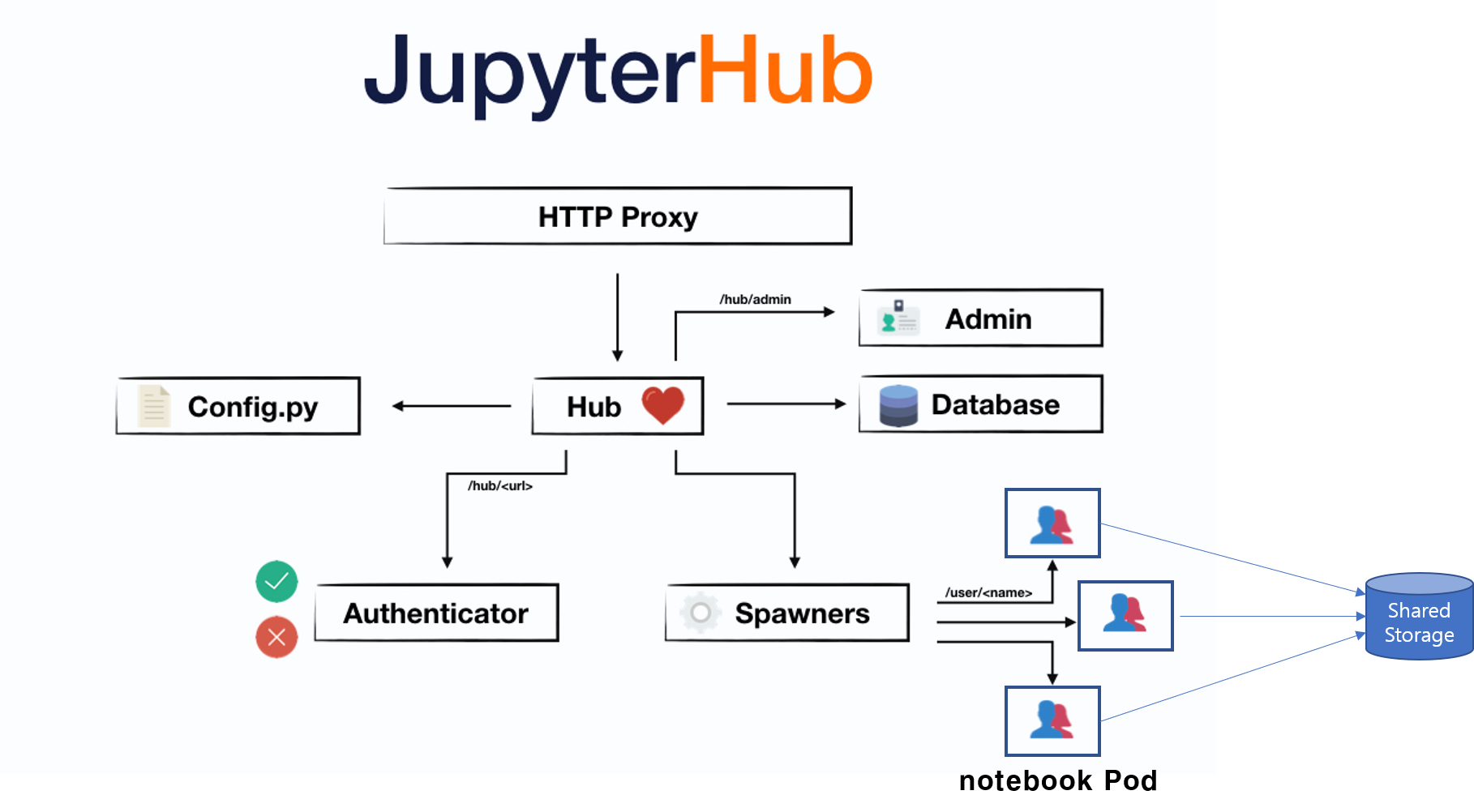
조금 복잡해 보일 수도 있지만 여기서는 Spawners와 Pod만 보시면 됩니다. 사용자가 본인의 주피터 노트북을 런칭할 때마다 Spawners라는 녀석이 쿠버네티스 Pod를 하나씩 생성합니다. 이 Pod 하나는 주피터 노트북 서버 하나를 의미합니다. 사용자들은 저마다의 주피터 노트북 서버 하나씩을 배정 받아 그 안에서 모델을 개발합니다. 각 Pod들은 전부 Shared Storage, 예를 들어 NAS(Network Attached Storage) 서버와 연결되어 주피터 노트북 서버에서 작성한 코드는 전부 한 곳에 저장됩니다.
Pod== 주피터 노트북 서버- 데이터 저장 위치 == Shared Storage(NAS 서버)
이러한 주피터 노트북 환경(컨테이너 환경)에서 데이터 과학자가 모델을 개발하면 됩니다.
쿠버네티스로 코드 전달하기
2번째 문제가 남았습니다. 컨테이너 속에 데이터 과학자의 코드를 넣는 것까진 해결을 하였지만 이것을 어떻게 다시 쿠버네티스 위로 올릴 수 있을까요? 쿠버네티스는 기본적으로 빌드된 이미지를 실행할 뿐이지, 한번 실행된 컨테이너를 다시 실행하진 않습니다. 그렇다면 지금까지 사용한 컨테이너(주피터 노트북 서버)를 다시 이미지로 빌드해야 할까요? 그렇지 않습니다. 다시 이미지를 빌드하지 않고도 컨테이너 안에서 작성한 코드를 쿠버네티스로 전달할 수 있습니다.
앞에서 언급한 Shared Storage를 사용하면 간단하게 해결됩니다. 데이터 과학자가 작성한 ML 코드는 Shared Storage(NAS)에 저장되기 때문에 쿠버네티스에 새로운 Job을 실행 시킬 때 주피터 노트북에서 사용한 Shared Storage를 다시 Volume으로 연결 시키기만 하면 변경된 ML 코드를 그대로 사용할 수 있습니다.
다음 학습 스크립트를 살펴 봅시다. 머신러닝 코드를 실행할 때 필요한 정보는 크게 3가지 입니다. 그것은 “모델 실행환경, 머신러닝 소스코드, 모델 하이퍼파라미터” 입니다.
venv/bin/python train.py epoch=10 dropout=0.5
- 모델 실행환경:
virtualenv실행환경(venv) - 머신러닝 소스코드:
train.py - 모델 하이퍼파라미터:
epoch=10 dropout=0.5
이러한 정보들을 어떻게든 쿠버네티스에게 전달할 수만 있다면 별도의 이미지 빌드 작업 없이 바로 ML Job을 scalable하게 쿠버네티스에서 실행할 수 있을 것입니다. 재밌게도 주피터 허브를 활용하면 이러한 정보들을 손쉽게 알 수 있습니다. 주피터 노트북 Pod에 묻어나오는 메타데이터를 추출하면 됩니다.
- 모델 실행환경: 주피터 노트북 서버에서 사용한 이미지 (
Pod.spec.containers.image) - 머신러닝 소스코드: 모델 소스코드가 저장된 Shared 볼륨 (
Pod.spec.volumes) - 모델 하이퍼파라미터: ML툴에 전달된 파라미터
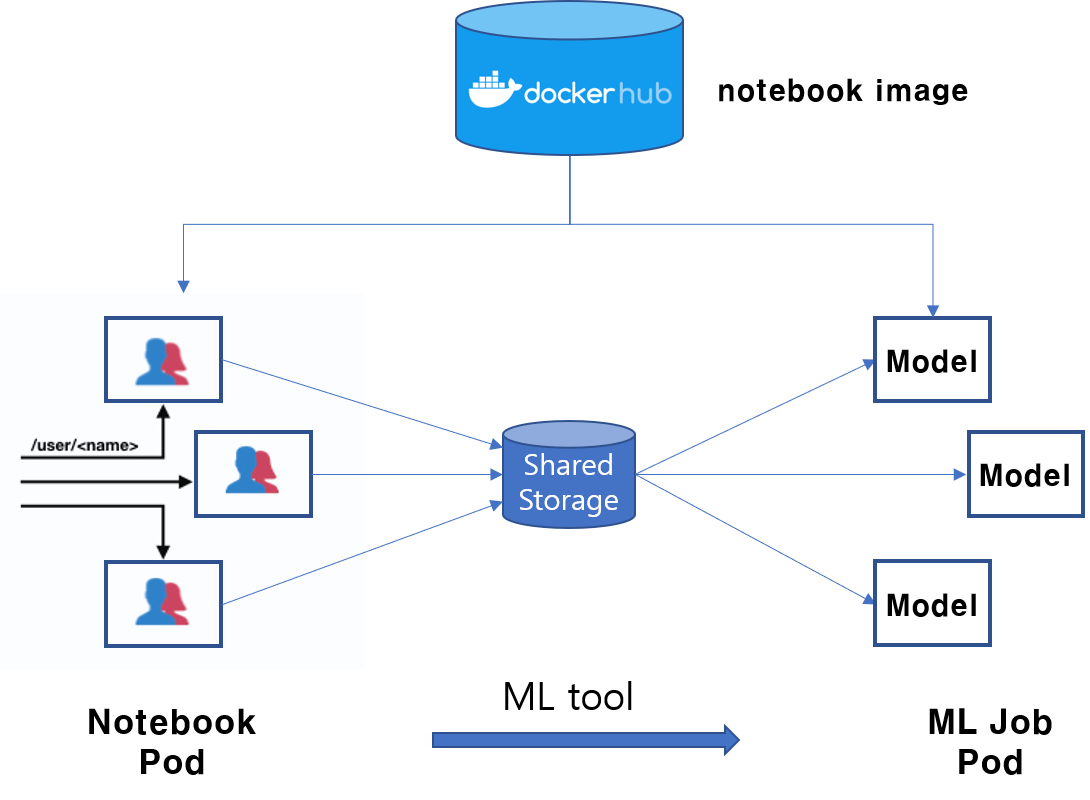
만약 어떤 ML툴이 충분히 똑똑하게도 데이터 과학자의 요청에 따라 현재 사용하고 있는 학습 실행환경(주피터 노트북 컨테이너 이미지)을 파악하고 데이터 과학자가 작성한 머신러닝 소스코드를 찾아 모델 하이퍼파라미터와 조합하여 쿠버네티스 매니페스트(YAML 파일)를 작성한 후 쿠버네티스에 전달한다면 컨테이너화 작업과 쿠버네티스 매니페스트 파일 작성 없이 데이터 과학자의 ML 코드를 쿠버네티스 위에서 실행할 수 있게 됩니다.
정말 이런 ML툴이 존재할까요?
JupyterFlow
JupyterFlow를 소개합니다.
여러분께 JupyterFlow (https://jupyterflow.com)를 소개합니다.

JupyterFlow는 편리한 머신러닝을 위한 CLI 툴로써 주피터 노트북 위에서 작성한 ML 코드를 컨테이너화 작업 없이 곧바로 쿠버네티스 위에 ML Job을 실행할 수 있도록 도와줍니다.
예를 들어, 다음과 같이 주피터 노트북에서 hello.py와 world.py 파일을 원하는대로 작성하고 jupyterflow CLI를 통해 Job을 submit하면 자동으로 쿠버네티스 학습 파이프라인이 생성됩니다.
# hello.py & wrold.py 작성
echo "print('hello')" > hello.py
echo "print('world')" > world.py
# jupyterflow를 설치합니다.
pip install jupyterflow
# jupyterflow에서 `>>` 지시자는 output redirection이 아니라
# 프로세스간의 종속성을 나타냅니다.
# 마치 Airflow처럼 말이죠
jupyterflow run -c "python hello.py >> python world.py"
실행 결과는 다음과 같습니다.
만약 JupyterFlow 없이 기존 방법대로 모델을 개발한다면 다음과 같은 모델 개발 사이클을 가집니다.
- 데이터 과학자가 모델을 개발한다.
- 개발한 ML 코드를 컨테이너화 시킨다.
- 쿠버네티스 매니페스트(YAML파일) 파일을 작성한다.
kubectl을 통해 Job을 submit한다.

반대로 JupyterFlow를 사용하면 데이터 과학자의 모델 개발 사이클은 다음과 같이 간편해집니다.
- 주피터 허브를 통해 노트북을 할당 받는다.
- 노트북에서 모델을 개발한다.
jupyterflowCLI를 통해 학습 Job을 쿠버네티스에 submit한다.

그러면 나머지는 JupyterFlow가 알아서 똑똑하게 일을 처리합니다. 어떤가요, 꽤나 멋지지 않나요?
JupyterFlow Architecture
JupyterFlow의 큰 그림은 다음과 같습니다.
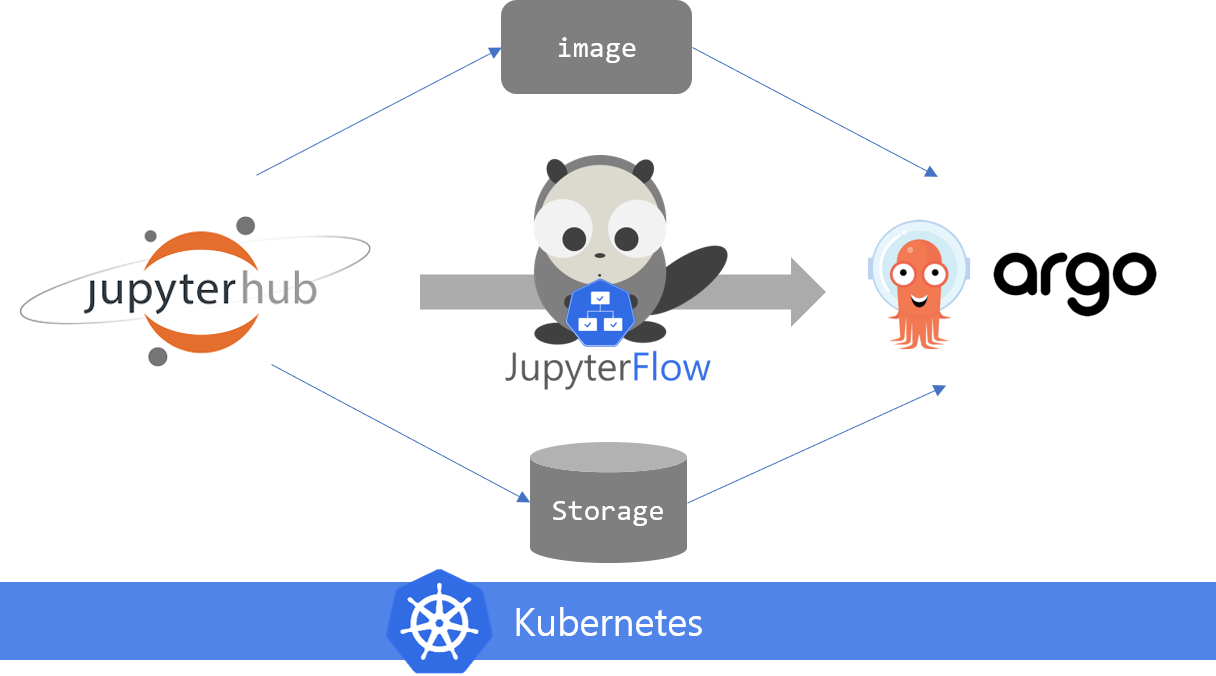
JupyterFlow를 사용하려면 두가지 컴포넌트가 필요합니다. 주피터 허브와 Argo Workflow가 필요합니다. Argo Workflow는 쿠버네티스에서 컨테이너 간의 종속성을 부여하여 작업흐름(Workflow)을 구성할 수 있게 만들어주는 커스텀 컨트롤러입니다.
Argo Workflow를 설치하면 Workflow라는 CRD(CustomResourceDefinition)를 사용할 수 있게 됩니다. 간단한 Workflow의 YAML 예시는 다음과 같습니다.
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: hello-world-
spec:
entrypoint: whalesay
templates:
- name: whalesay
container:
image: docker/whalesay
command: [cowsay]
args: ["hello world"]
resources:
limits:
memory: 32Mi
cpu: 100m
해당 YAML을 쿠버네티스에 전달(submit)하면 쿠버네티스는 YAML 정의에 맞게 적절한 워크플로우를 생성합니다. 사용자는 워크플로우의 결과를 Argo 설치 시 제공되는 Web UI(argo-ui)를 통해 확인할 수 있습니다.
JupyterFlow의 역할은 주피터 노트북의 정보(Pod 메타정보 - 이미지 주소, NFS volume 등) 및 모델 파라미터를 수집하여 최종적으로 위의 예시와 비슷한 Workflow YAML 파일(매니페스트 파일)을 생성하여 쿠버네티스 마스터로 전달합니다. 그러면 나머지는 쿠버네티스가 알아서 YAML 정의에 맞게 학습 파이프라인을 실행합니다. 데이터 과학자는 Argo UI를 통해 간편하게 학습 결과를 확인하기만 하면 됩니다.
Zeppelin & Spark과의 비교
이해를 돕기 위해 Zeppelin과 Spark간의 관계에 대해서 생각해 봅시다.
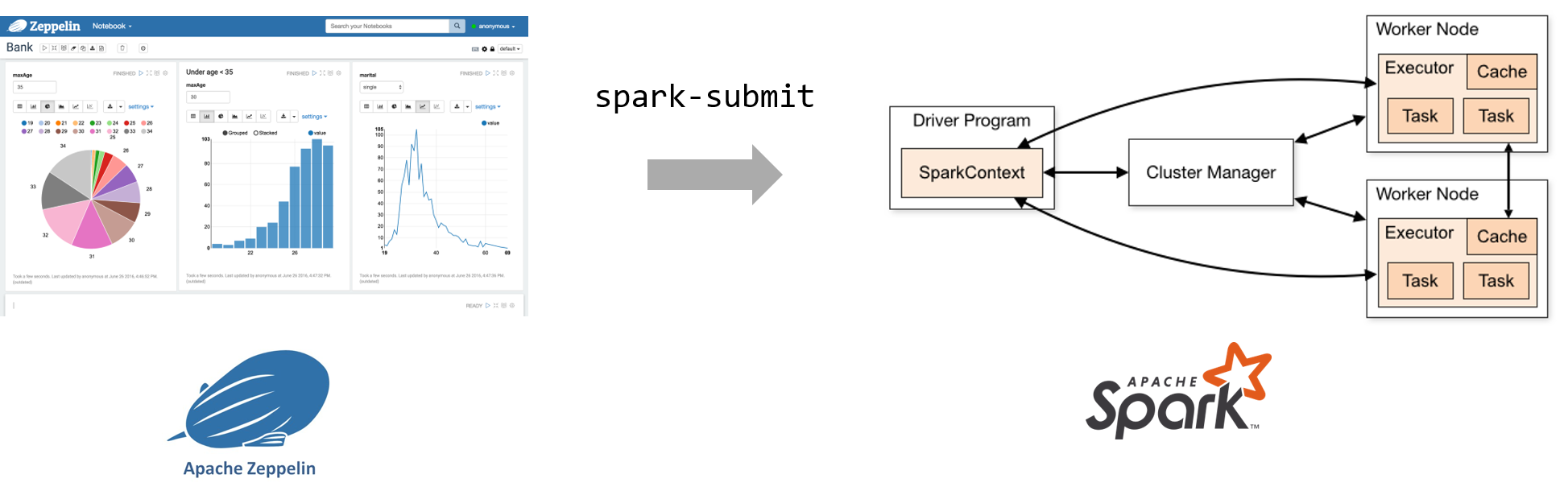
데이터 엔지니어는 Spark의 구체적인 아키텍처와 상세 구현을 전부 알지 못하더라도 손쉽게 Zeppelin UI를 통해 Interactive하게 분석을 하고 spark-submit이라는 툴(script)을 이용하여 Spark 클러스터에 Job을 submit합니다.
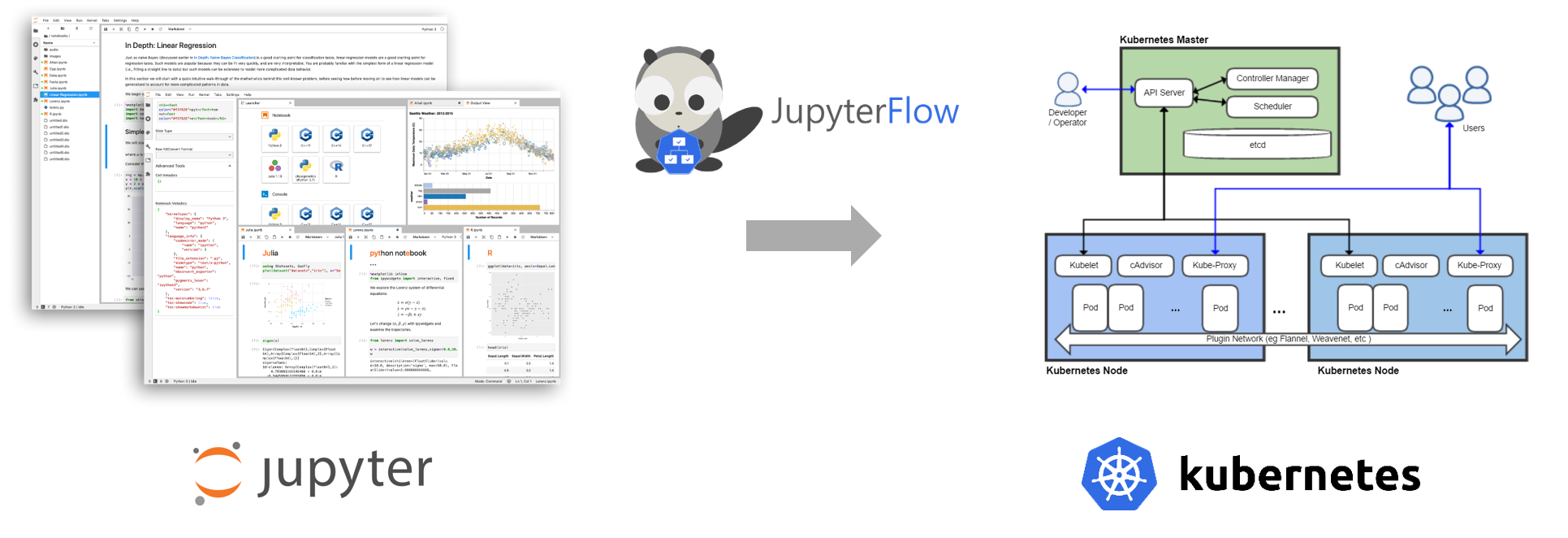
마찬가지로 데이터 과학자는 쿠버네티스의 구체적인 아키텍처와 복잡한 설정을 전부 알지 못하더라도 손쉽게 Jupyter UI를 통해 Interactive하게 모델링하고 JupyterFlow라는 ML툴을 이용하여 Kubernetes 클러스터에 Workflow를 submit할 수 있습니다.
차이점이 있다면 Spark에는 job을 submit할 수 있는 메커니즘이 자체적으로 구현(spark-submit)되어 있는 반면 주피터 & 쿠버네티스에는 이런 툴이 없기 때문에 바로 JupyterFlow가 이를 대신합니다.
JupyterFlow Docs
더 자세한 JupyterFlow에 대한 설명은 JupyterFlow Docs를 참고해 주시기 바랍니다.
이제 데이터 과학자는 JupyterFlow만 있으면 본인이 작성한 코드를 곧바로 쿠버네티스 위에서 실행할 수 있습니다. 여러분도 한번 JupyterFlow의 멋진 기능을 테스트해 보시기 바랍니다!
마치며
JupyterFlow는 제가 개인적으로 시작한 오픈소스 프로젝트입니다. 아직 초기 단계여서 버그도 있고 완벽하진 않습니다. 그럼에도 불구하고 JupyterFlow가 가지는 굉장한 가능성을 보고 계속해서 조금씩 투자하고 있습니다. 제가 확인했을 때는 아직까지 이런 방식의 해결책이 나온 사례나 프로젝트는 없으며 여전히 MLOps 진영에서는 절대적 강자의 ML툴이 나오지 않은 상황입니다. 여러분도 이 글을 보시고 관심이 가거나 조금 더 살펴보고 싶으시다면 주저하지 마시고 언제든지 저에게 연락 부탁드립니다.
- 메일: hongkunyoo (at) 지메일
- Github 이슈 등록
- 블로그 댓글
다양한 의견, 문의, 트러블슈팅 요청, 피드백, 비판, 프로젝트 참여 환영합니다.