![[번역] 쿠버네티스에서 쉽게 저지르는 10가지 실수](/assets/images/landing/dockerlego.png)
[번역] 쿠버네티스에서 쉽게 저지르는 10가지 실수
11 min read
쿠버네티스를 사용하면서 쉽게 저지르는 10가지 실수에 대한 번역글입니다. 원글을 읽고 공감가는 부분이 많아 기록으로 남기고자 번역하였습니다.
우리는 그 동안 다양한 쿠버네티스 클러스터(직접 혹은 관리형)를 볼 수 있는 기회가 있었고 사람들이 몇가지 반복적인 실수를 하는 것을 알게 되었습니다. 사실 우리도 비슷한 실수들을 하였습니다. 몇가지 흔한 케이스에 대해서 설명하고 고치는 방법에 대해서 공유하고자 합니다.
리소스 설정 - requests and limits
리소스 설정 부분이 가장 많은 관심을 갖기에 충분하기에 첫번째로 말씀 드립니다.
CPU 요청량이 설정되어 있지 않거나 혹은 너무 낮게 설정되어 있는 경우입니다. 많은 Pod들을 한 노드에 넣기 위한 방법이죠. 하지만 이로 인해 노드들이 초과할당(overcommited)된 상태가 됩니다. 평상 시에는 문제가 없더라도 CPU 자원을 많이 사용하게 되는 경우, 각 어플리케이션들은 초기에 요청한 자원만큼만 사용할 수 있어 CPU throttle이 발생하게 되고 어플리케이션 지연이 발생하게 됩니다.
다음과 같은 설정들을 지양합시다.
BestEffort:
resources: {}
너무 낮은 CPU 설정:
resources:
requests:
cpu: "1m"
반면에, CPU limit을 설정하는 것은 노드의 CPU가 한가함에도 불구하고 Pod에 불필요한 CPU throttle을 발생시킬 수 있습니다. 현재 리눅스 커널에서의 CPU CFS quota를 이용하는 것과 CPU limit을 이용한 CPU throttling에 대한 논의가 이루어지고 있습니다. CPU limits는 문제를 해결하는 것보다 문제를 더 야기 시키는 경우가 많습니다.
메모리 초과할당(overcommit)은 더 큰 문제를 불러올 수 있습니다. CPU limit에 도달하는 경우에 CPU throttling이 발생하지만 메모리 limit에 도달하는 경우 Pod가 죽게 됩니다. OOMKill에 대해서 들어보셨나요? 바로 그것이 발생합니다. 이것의 발생 빈도를 줄이고 싶다면 메모리를 초과할당하지 말고 Guaranteed QoS(Quality of Service)로 설정하시기 바랍니다. Guaranteed QoS란 아래의 예시처럼 메모리의 요청량(requests)을 제한량(limits)과 동일하게 설정하는 것을 의미합니다. 더 자세한 내용은 Henning Jacobs’ (Zalando) 발표자료를 참고하시기 바랍니다.
Burstable(OOMkilled될 가능성이 더 많아짐):
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: 2
Guaranteed:
resources:
requests:
memory: "128Mi"
cpu: 2
limits:
memory: "128Mi"
cpu: 2
리소스 설정을 한다면 어떤 이점이 있을까요?
Pod의 현재 CPU와 메모리 사용량을 확인할 수 있습니다. (그 안에 컨테이너의 사용량도 확인할 수 있습니다.) 바로 metrics-server를 통해서 볼 수 있습니다. 다음 명령을 실행해 봅시다.
kubectl top pods
kubectl top pods --containers
kubectl top nodes
해당 명령은 현재 리소스 사용량만 보여줍니다. 이 정도로도 훌륭하지만 결국에는 시간별 리소스 사용량을 확인할 필요가 생기게 됩니다. (그러면 다음과 같은 질문들에 대한 답을 얻을 수 있습니다. “어제 아침 peak 때의 CPU 사용량이 어느 정도 였나요?”) 이것은 Prometheus, DataDog와 같은 플랫폼을 이용하여 확인할 수 있습니다. 이들은 metrics-server로 부터 메트릭 정보를 받아 내부적으로 저장하고 사용자들이 쿼리할 수 있게 지원하는 시스템들입니다.
VerticalPodAutoscaler는 자동으로 Pod의 리소스 사용량을 확장 시켜주는 친구입니다. CPU/메모리 사용량을 지켜보고 있다가 새롭게 리소스 제약을 설정해 줍니다.
최적의 리소스 사용량을 찾는 작업은 쉽지 않는 일입니다. 마치 매번 테트리스를 하는 느낌이죠. 만약에 평균적으로 낮은 리소스 사용량(대략 ~10% 미만)을 보이는데 리소스 사용량을 설정하는데 많은 시간을 보내고 있다면 AWS Fargate나 가상 kubelet (virtual kubelet)을 지원하는 제품을 사용하는 것을 한번 고려해 보시기 바랍니다. 이러한 제품들은 서버리스의 이점과 사용량에 따른 비용 과금 방식을 활용하여 더 싸고 운영 효율적인 솔류션이 될 수 있습니다.
Health 체크 - liveness and readiness probes
기본적으로 Pod를 생성하면 liveness와 readiness 설정이 없습니다. 때론 그 상태 그대로 놔두죠. 하지만 그러한 설정은 당신의 서비스가 알 수 없는 장애에 맞닥뜨리게 되었을 때 어떻게 Pod를 재시작하게 만들 수 있을까요? 또는 당신의 Pod가 사용자 요청을 처리할 수 있을지 로드밸런서가 어떻게 알 수 있을까요?
사람들은 대부분 다음 두가지 설정의 차이를 잘 구분하지 못합니다.
- Liveness 체크는 당신의
Pod가 linvess 검사를 통과하지 못할 경우 재시작됩니다. - Readiness 체크는 검사를 통과하지 못하는 경우 더 이상 요청을 받지 못하게
Service로 부터 오는 트래픽을 끊습니다.
두가지 검사 모두 Pod의 생명주기 전체 기간동안 지속적으로 검사합니다. 이것은 중요한 부분입니다. 사람들은 주로 ReadinessProbe의 경우 Pod를 시작할 시점에만 검사를 진행하여 트래픽의 전달 여부를 결정한다고 생각합니다. 하지만 그것은 단지 하나의 사용사례에 불과합니다. 또 다른 중요한 사용법으로는, 특정 Pod에 너무 많은 트래픽이 몰리게 되어 너무 뜨거워지는 경우(too hot) 더 이상 트래픽이 전송되지 않게 함으로써 열을 시킬 수 (cool down) 메커니즘을 제공합니다. 어느 정도 시간이 지난 후 ReadinessProbe이 성공적으로 검사를 통과하기 시작하면 다시 트래픽을 전송하게 됩니다. 이런 상황에서 liveness와 readiness 검사를 동일하게 설정하여 readiness가 실패할 경우, Pod가 재시작하게 된다면 매우 비생산적일 수 밖에 없습니다. 굳이 건강한 (healthy) Pod가 단지 일을 많이 한다고 해서 재시작하는 것이 맞을까요?
때로는 차라리 상태 검사를 둘다 제대로 설정을 안하는 것이 잘못 설정해 놓는 것보다 나은 경우가 있습니다. 위에서 언급했듯이, livness 검사와 readiness 검사를 동일하게 설정한다면 큰 문제가 발생할 수 있습니다.(역자주: Pod가 할일이 많은데 계속해서 재시작이 될 수 있는 위험성이 존재합니다.) 처음 시작한다면 readiness 검사만 설정하길 권장드립니다. 왜냐하면 liveness 검사는 자칫 위험할 수도 있기 때문입니다.
종속성이 있는 다른 서비스가 죽는다고 하더라도 linvess와 readiness에 영향이 가지 않게 설정하시길 바랍니다. 연쇄적 실패(cascading failure)가 발생할 수도 있기 때문입니다. 잘못하다간 자기 스스로 문제를 악화 시킬 수 있습니다.
모든 서비스에 로드밸런서 달기
많은 경우, 클러스터에서 한개 이상의 endpoint를 외부로 노출 시켜야 하는 상황이 존재합니다. Service의 타입을 type: LoadBalancer로 생성하는 경우 플랫폼에 따라 알맞는 외부 로드밸랜서가 만들어지고 연결이 됩니다.(L7 로드밸랜서가 아닌 L4 LB인 경우가 많죠) 이러한 리소스는 많이 생성하는 경우 비용이 많이 들 수도 있습니다.(공인 IP, 서버 등)
이러한 상황에서는 쿠버네티스 Service를 NodePort로 생성하면서 한개의 외부 로드밸런서를 공유하는 방법이 있습니다. 혹은 더 좋은 방법으로는 nginx-ingress-controller(혹은 traefik)과 같은 Ingress 컨트롤러를 이용하여 한개의 endpoint를 이용하여 L7 레벨에서 트래픽을 라우팅하는 방법도 있습니다.
클러스터 내부의 서비스들끼리 통신을 하는 경우에는 단순히 ClusterIP 타입의 서비스를 이용하고 내부 DNS 서비스 탐색 기능을 사용하길 바랍니다. 이런 경우에는 굳이 외부 DNS/IP를 이용하여 응답시간이 지연되거나 클라우드 비용이 추가적으로 발생하지 않게 주의하시기 바랍니다.
쿠버네티스가 모르는 자동확장
쿠버네티스는 클러스터에 노드를 추가하거나 삭제할 때, 단순히 간단한 CPU 사용량을 보고 자동확장을 수행하지 않습니다. 쿠버네티스는 Pod를 스케줄링할 때, Pod, Node affinity, taints, toleration, resource requests, QoS 등 다양한 스케줄링 제약사항을 확인하여 결정합니다. 그렇기 때문에 이러한 세부적인 사항들을 이해하지 못하는 외부 자동확장 컴포넌트를 사용하는 것은 문제를 일으킬 수 있습니다.
예를 들어, 새로운 Pod를 생성하는데 기존의 Pod들이 클러스터의 모든 CPU 리소스 만큼 CPU 요청량을 설정하여 Pod가 Pending 상태에 빠져 있는 경우를 생각해 봅시다.(예를 들어, 클러스터 전체 CPU 용량이 100인데 전체 Pod 요청량 합산이 100인 경우) 이 경우, 외부 자동확장 컴포넌트는 현재 CPU 평균 사용량을 보고 노드를 추가하지 않을 것입니다.(요청량은 100이라 하더라도 실제 사용량은 적을 수 있기 때문에) 결과적으로 새로 생성한 Pod는 계속 Pending 상태에 빠져 있을 것입니다.
Scaling-in(클러스터에서 노드를 삭제)은 항상 더 어렵습니다. 예를 들어, Stateful Pod(persistent 볼륨이 연결된 Pod)가 있다고 생각해 봅시다. persistent 볼륨은 주로 특정 가용영역(Availability Zone)에 속해 있는 자원이고 리전간 복제되지 않습니다. 만약 외부 자동확장 컴포넌트가 이러한 노드를 삭제하는 경우 그 안에 들어 있던 Pod는 다른 노드에 할당되지 못하고 Pending 상태에 빠져 있게 될 것입니다. 이 Pod는 특정 가용영역에 존재하는 노드에서만 동작하기 때문입니다.
이러한 이유로 쿠버네티스 커뮤니티에서는 cluster-autoscaler를 많이 사용합니다. 이 컴포넌트는 대부분의 퍼블릭 클라우드 벤더에서 지원하며 모든 세부적인 쿠버네티스 스케줄링 제약사항을 이해하여 자동확장을 수행합니다. 뿐만 아니라 최대한 주어진 제약사항에 영향이 가지 않게 아름답게 노드를 제거(gracefully scale-in)할 수 있는 방법을 찾아 운영 비용을 최소화합니다.
권한관리 부재
클러스터의 권한제어를 위해 IAM User의 액세스 키를 각 서버와 어플리케이션에 저장하지 말고 역할(Role)이나 서비스 계정(Service Account)를 이용하여 임시 권한을 발급하는 형식을 사용하길 바랍니다.
우리는 종종, 하드코딩된 액세스 키가 어플리케이션 설정값으로 들어있는 것을 봅니다. 권한관리를 할 때 절대로 이러한 방법을 사용하지 않길 바랍니다. 최대한 IAM 역할이나 서비스 계정을 활용하길 바랍니다.

kube2iam을 사용하지 말고 바로 ServiceAccount를 위한 IAM Role을 사용하기 바랍니다.
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/my-app-role
name: my-serviceaccount
namespace: default
annotations 하나만 추가하면 됩니다. 어때요, 쉽죠?
또한 꼭 필요한 경우가 아니라면 서비스 계정이나 인스턴스 프로파일에 admin이나 cluster-admin 권한을 부여하지 않길 바랍니다. 일일이 권한을 나누는 일은 조금 귀찮은 일이긴 하지만 충분히 그럴 가치가 있습니다.
Anti Affinity 설정
가용성을 위해 3개 Pod 레플리카를 생성하였지만 노드가 죽을 때 3개 Pod 모두 한꺼번에 죽었습니다. 어떻게 된 일인가요? 3개 Pod가 전부 한개 노드 위에서 돌았군요. 쿠버네티스가 알아서 고가용성(HA)을 보장해주는 것이 아니었나요?
쿠버네티스 스케줄러가 강제로 anti-affinity를 설정해 주진 않습니다. 명시적으로 선언해야 합니다.
# 생략...
# 라벨 설정
labels:
app: zk
# 생략...
# anti-affinity 설정
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname"
이것이 전부입니다. 이렇게 하면 모든 Pod들이 각각 다른 노드에서 실행될 것입니다. 뿐만 아니라 topologyKey를 kubernetes.io/hostname가 아닌 availability zone으로 바꾸는 경우 가용영역에 따라 나눠서 스케줄링할 수도 있습니다.
PodDisruptionBudget 설정
운영 환경에서 쿠버네티스를 운영하는 경우, 시간에 따라 노드관리를 해야 합니다. (노드 추가, 업그레이드, 삭제 등) PodDisruptionBudget(이하 pdb)는 클러스터 관리자와 클러스터 사용자간의 서비스 보증을 해주는 API입니다.
pdb를 꼭 생성하여 노드 삭제 시(node drain) 서비스 장애가 발생하지 않게 설정하길 바랍니다.
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeper
이러한 pdb 리소스는 클러스터 사용자로써 클러스터 관리자에게 이런 말을 남기는 것과 같습니다. “저는 무슨 일이 있어도 zookeeper 서비스가 최소 2개 이상 가용한 상태로 유지되어야 합니다.”
더 자세한 논의는 다음 블로그 포스트를 참고하시기 바랍니다.
Cluster 공유
쿠버네티스 네임스페이스는 완벽히 고립된 환경(isolation)을 제공하지 않습니다.
사람들은 종종 네임스페이스를 이용하여 운영환경과 개별환경을 나누고 싶어합니다. 특정 워크로드가 다른 네임스페이스에 영향을 미치지 않게 않게 하고 싶어 합니다. 쿠버네티스의 여러 메커니즘을 잘 이용한다면 어느 정도 가능한 얘기입니다. - 리소스 사용량 제약, quotas, priorityClasses, affinity, tolerations, taints, nodeSelector 등을 이용하면 되지만 꽤나 복잡한 일입니다.
만약 동일한 클러스터에서 스테이지별(dev, prod) 같은 작업을 해야하는 워크로드가 있는 경우 어쩔 수 없이 이 복잡성을 감수하고 사용해야 하지만 그렇지 않는 경우 클러스터를 나누길 바랍니다. 이것은 더 강한 고립성을 부여하고 복잡성을 감소 시킵니다.
externalTrafficPolicy: Cluster 설정
모든 트래픽들이 NodePort 서비스를 통해 클러스터 내부에서 전부 라우팅될 수 있게 Service의 기본값인 externalTrafficPolicy: Cluster로 설정되는 경우가 대부분입니다. 이 뜻은 NodePort가 모든 노드에 동일하게 열려 있어 어떤 노드를 통하든 원하는 Pod로 도달할 수 있는 것을 의미합니다.
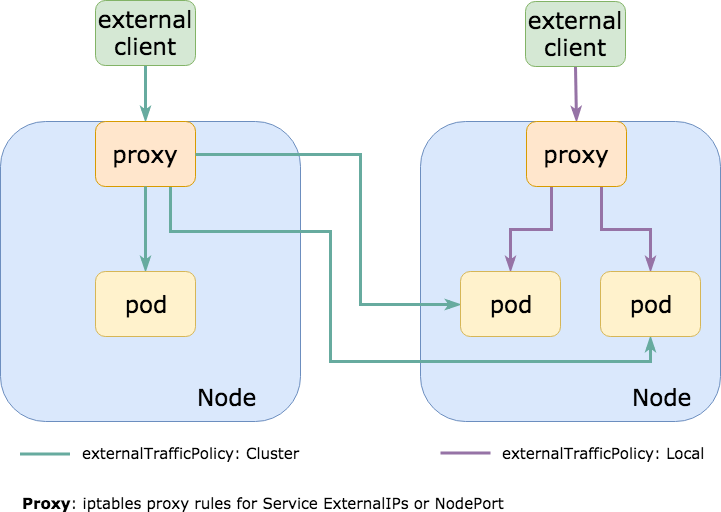
통신하고자 하는 Pod들이 모든 노드에 있는 것은 아니기 때문에 나의 요청이 실제로 Pod가 존재하는 노드로 라우팅되지 않는 경우 내부적으로 추가적인 네트워크 홉(network hop)을 야기 시키고 이는 네트워크 지연을 발생 시킵니다.(노드들이 서로 다른 가용영역이나 데이터센터에 있을 경우 더 높은 지연시간과 추가적인 아웃바운드 비용을 발생 시킵니다.)
쿠버네티스 서비스를 externalTrafficPolicy: Local로 설정하게 되면 모든 노드에 NodePort가 열리지 않고 실제로 Pod가 존재하는 노드에만 포트가 열리게 됩니다. 만약 AWS ELB와 같이 지속적으로 타겟 노드의 상태검사(health check)를 수행하는 외부 로드밸랜서를 사용하는 경우 사용자의 요청이 실제로 Pod가 존재하는 노드로만 전달되게 됩니다.(역자주: 해당 Pod가 없는 노드는 health check에서 실패하기 때문에 트래픽을 전달하지 않습니다.) 이것은 지연시간을 개선해주고 처리 속도와 높혀주며 아웃바운드 비용을 감소 시킵니다.
traefix이나 nginx-ingress-controller와 같은 L7 ingress 컨트롤러를 NodePort로 사용하여 HTTP 요청을 처리하는 경우 더 많은 지연시간을 개선할 수 있습니다.
다음 블로그 포스트 externalTrafficPolicy와 트레이드오프에서 더 자세한 내용들을 확인해 보시기 바랍니다.
애완동물 클러스터 + 마스터에 너무 큰 부하주기
당신은 예전에 서버를 Anton, HAL9000, Colossus와 같이 각각의 이름을 지어주었지만(Pet) 이제는 랜덤 ID(cattle)를 부여합니다. 하지만 이제 클러스터에 이름을 부여하기 시작하진 않았나요? 혹시 쿠버네티스를 처음 PoC(Proof of Concept)하기 위해 이름을 “testing”이라고 지어놓고 바꾸기 무서워서 아직도 여전히 그 이름을 사용하고 있진 않나요?(실제로 그런 사례가 있었습니다.)
애완동물 클러스터를 가지는 것은 즐겁지 않습니다. 시간이 지남에 따라 주기적으로 클러스터를 삭제함으로써 재해복구(Disaster Recovery)를 연습하고 마스터(control plane)를 관리해 보시기 바랍니다. 마스터 건들이기를 무서워하는 것은 그리 좋은 신호는 아닙니다.
반면에 너무 자주 클러스터를 만지는 것도 좋지 않습니다. 혹시 마스터가 너무 느려진 것 같다면, 혹시나 너무 많은 쿠버네티스 객체를 생성한 것은 아닌지 의심해 봐야합니다. (특히나 helm과 같은 툴을 사용하면 패키지를 업데이트할 때 기존의 객체를 업데이트하는 것이 아니라 매번 객체를 새로 생성하기 때문에 수 많은 객체들이 마스터에 쌓이게 됩니다.) 혹은 kube-api를 이용하여 주기적으로 수 많은 정보를 수집하거나 수정하는 경우에도 느려집니다.(자동확장, CI/CD, 모니터링, 로그 등)
또한 관리형 쿠버네티스 클러스터를 사용한다면 “SLA(Service Level Aggrement) / SLO(Objective)”를 확인해 보시기 바랍니다. 벤더가 마스터의 가용성은 충분히 보장하더라도 요청에 대한 99% 수준의 응답시간을 보장하지 않을 수 있습니다. 이 뜻은 kubectl get nodes 명령을 내리고 10분 이후에 응답을 받아도 서비스 계약을 위반한게 아닐 수 있습니다.
보너스: latest tag 사용하기
이건 이미 자주 나온 얘기이죠. 최근에는 latest 태그에 대한 문제는 많이 나오지 않는 것 같습니다. 아마 이미 많은 분들이 latest 태그를 그대로 사용함으로써 곤혹을 치뤘기 때문이라 생각됩니다. latest 태그를 그대로 사용하지 말고 명시적으로 버전을 지정하시길 바랍니다.
ECR에서는 불변 태그라는 멋진 기능을 추가하였습니다. 꼭 한번 확인해 보시기 바랍니다.(역자주: 한번 만들어진 태그에 덮어쓰기가 불가능하게 만든 기능입니다.)
마치며
모든 것이 자동으로 해결될 것이라고 기대하진 마십시오. 쿠버네티스는 은총알(silver bullet)이 아닙니다. 나쁜 어플리케이션은 쿠버네티스 위에서도 나쁜 어플리케이션으로 존재할 것입니다.(어쩌면 더 문제가 될 수도 있습니다.) 쿠버네티스를 주의하여 올바르게 사용하지 않는다면 결국에 높은 복잡성과 부하, 느린 control plane 응답을 경험하게 되고 재해복구가 제대로 이루어지지 않을 것입니다. 손쉽게 multi-tenancy와 고가용성을 얻을 것이라 기대하지 마십시오. cloud-native 어플리케이션을 만들기 위한 충분한 시간을 투자하시길 바랍니다.
또다른 실패 경험을 들어보시길 원한다면 Henning의 실패 경험담 사이트를 확인해 보세요!